







一、处理信号
Linux利用信号与运行在系统中的进程进行通信,进程的信号就是预定义好的一个消息,进程能识别它并决定是忽略还是做出反应。进程如何处理信号是由开发人员通过编程来决定的,大多数编写完善的程序都能接收和处理标准Unix进程信号。Linux进程信号如下:
| 信号 | 名称 | 描述 |
|---|---|---|
| 1 | SIGHUP | 挂起进程 |
| 2 | SIGINT | 终止进程 |
| 3 | SIGQUIT | 停止进程 |
| 9 | SIGKILL | 无条件终止进程 |
| 15 | SIGTERM | 尽可能终止进程 |
| 17 | SIGSTOP | 无条件停止进程,但不是终止进程 |
| 18 | SIGTSTP | 停止或暂停进程,但不终止进程 |
| 19 | SIGCONT | 继续运行停止的进程 |
~
进程和作业的区别:
- 区别:进程是一个程序在一个数据集上的一次执行,而作业是用户提交给系统的一个任务。
- 关系:一个作业通常包括几个进程,几个进程共同完成一个任务,即作业。
- 用户提交作业以后,当作业被调度,系统会为作业创建进程,一个进程无法完成时,系统会为这个进程创建子进程。
1. 生成信号
bash shell允许用键盘上的组合键生成两种基本的Linux信号,在需要停止或暂停失控程序时非常方便。
1. 中断进程
CTRL+C组合键会生成SIGINT信号,并将其发送给当前shell中运行的所有进程。
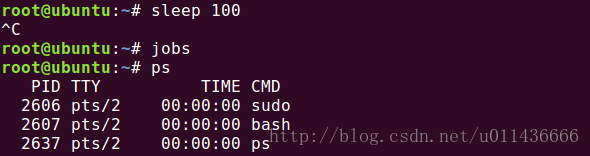
如图,执行sleep过程中,使用CTRL+C可以中断此sleep命令。
2. 暂停进程
你可以在程序运行期间暂停进程,而无需终止它。CTRL+Z会生成一个SIGTSTP信号,停止shell中运行的任何进程。停止和终止进程不同:停止进程会让程序继续保留在内存中,并能从上次暂停的位置继续运行。
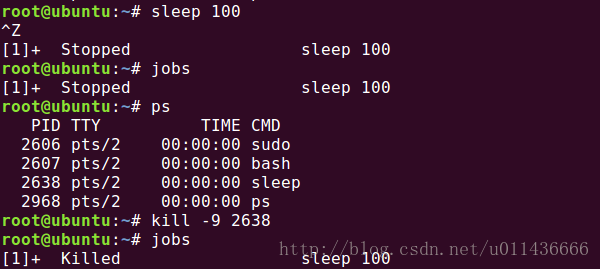
同理,我们使用CTRL+Z时,可以发现此进程是暂停了,使用kill命令发送SIGKILL信号可以将其终止。
二、后台模式运行脚本
以后台模式运行脚本或命令非常简单,只需要在命令后加一个&符号就可以了。如下示例:
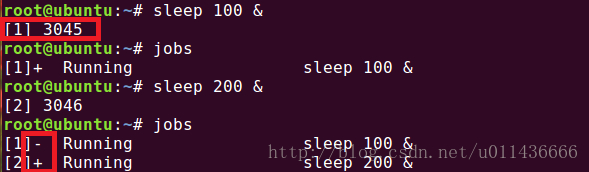
加上了&符号的sleep命令后,显示的第一行为作业号和PID,Linux系统中每个进程都有唯一的PID。此时用jobs命令查看,会发现它正在running状态。当其运行完以后运行jobs可以发现:
root@ubuntu:~# jobs
[1]- Done sleep 100
[2]+ Done sleep 200如果想在终端退出后作业仍以后台模式运行到结束,即使退出了终端会话,这可以用nohup命令来实现。nohup命令会将所有消息重定向到名为nohup.oout文件中,而不是显示在终端中。
jobs命令输出中的+和-
上面我们运行了两个job,通过jobs命令输出是可以看到后面有加号和减号,这是什么意思呢?带加号的作业会被当做默认作业,当我们不指定作业号时,该作业被当做作业命令的操作对象。而带减号的是下一个默认作业。如下图示例,使用bg将命令切换到后台。我们也可以使用bg 作业号来指定作业号将其放入后台,使用fg 作业号将其放入前台模式运行。
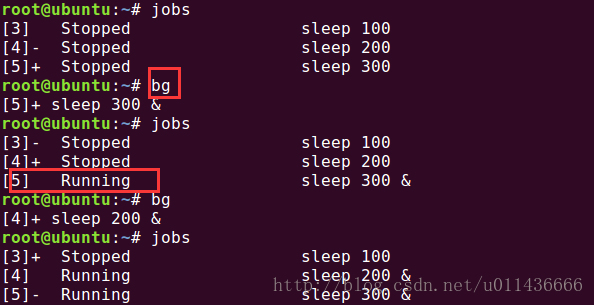
当命令处于stopped状态时可以通过bg或fg使其运行起来。
三、定时运行作业
Linux中提供了at命令和cron表来设置在某个预设的时间运行脚本。
1. 用at命令来计划执行作业
at命令的基本格式为:at [-f filename] time,使用-f参数来指定用于读取命令的文件名。time指定了合适运行该作业,在指定time上面,支持的时间格式很多:
- 标准的小时和分钟格式,如18:34
- AM/PM指示符,指定上午下午
- 标准日期格式,如MMDDYY、DD.MM.YY等
- 时间增量,如now+25min等等
例如我们要在三分钟后执行一个脚本,就可以用:at -f test1.sh now +3 min 来执行。执行之后,Linux系统就会将此作业提交到作业队列中,作业队列会保存通过at命令提交的待处理的作业。通过atq来查看当前的作业队列,然后可以通过atrm job_id来删除作业。
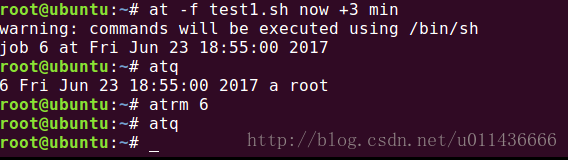
然而,at命令只是执行一次的,如果想要重复定期执行,就需要使用crontab了。
2. 用crontab定期执行作业
Linux程序使用cron程序来安排要定期执行的作业,cron程序会在后台运行并检查crontab(即cron时间表),来获知安排执行的作业。
crontab的格式如下:
min hour dayofmonth month dayofweek command
min:分钟,0~59
hour:小时,0~23
dayofmonth:几号,1~31
month:月份,1~12
week:星期几,0~6(周日,周一...周六)比如,
在每周一早上十点执行命令:00 10 * * 1 command
每个月的第一天12:00执行命令:00 12 1 * * command
如果是在每个月的最后一天呢?因为有可能是29、30、31,所以要用其他的方法:如00 12 * * * if [ 'date +%d -d tomorrow' = 01 ]; then;command
1. 构造crontab
使用crontab -l来查看当前的cron时间表。
使用crontab -e来编辑crontab。输入crontab -e之后,会跳转到编辑器中,输入crontab命令即可。如果我们对脚本运行时间的精确度要求不高的话,可以将其放在系统预置的cron脚本目录中即可:
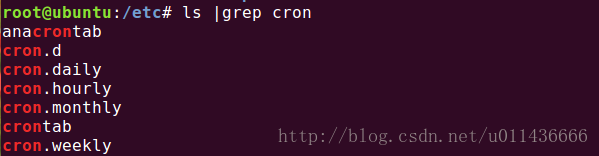
如图中的cron.daily、cron.hourly、cron.monthly、cron.weekly。需要每天执行的脚本放在cron.daily中即可,其他类似。
2. anacron程序
cron程序存在的问题是它假定Linux是7X24h运行的,如果某个作业在crontab中安排的时间到了,但这时候Linux是关机状态的话,这个作业就不会执行。当系统开机后,cron程序不会再去运行那些错过的作业,要解决这个问题,可以用anacron程序。
anacron程序只会处理位于cron目录的程序,它用时间戳来决定作业是否在正确的计划间隔内运行了。每个cron目录都有个时间戳文件,该文件位于/var/spool/anacron/目录下面:
root@ubuntu:~# cd /var/spool/anacron/
root@ubuntu:/var/spool/anacron# ls
cron.daily cron.monthly cron.weekly
anacron使用自己的时间表来检查作业目录,/etc/anacrontab如下:
root@ubuntu:/etc# ll |grep anacron
-rw-r--r-- 1 root root 401 Dec 29 2014 anacrontab
root@ubuntu:/etc# cat anacrontab
# /etc/anacrontab: configuration file for anacron
# See anacron(8) and anacrontab(5) for details.
SHELL=/bin/sh
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
HOME=/root
LOGNAME=root
# These replace cron's entries
1 5 cron.daily run-parts --report /etc/cron.daily
7 10 cron.weekly run-parts --report /etc/cron.weekly
@monthly 15 cron.monthly run-parts --report /etc/cron.monthlyanacrontab的格式为:period delay identifier command,period定义作业多就运行一次,以天为单位;delay以分钟为单位指定了系统启动后anacron需要等待多长时间再运行错过的作业;identifier 表示日志消息和错误邮件中的作业?command条目包含了run-parts程序和一个cron脚本名,如/etc/cron.daily等。
注意:anacron程序不会处理执行时间需求小于一天的脚本。
四、查看系统资源使用情况
也可以叫做进程管理,而进程管理的作用主要有三个:
- 判断服务器健康状态
- 查看系统中所有进程
- 杀死进程,释放资源
1. uptime
执行uptime之后,可以看见如下输出:
root@ubuntu:~# uptime
12:07:29 up 2 min, 1 user, load average: 0.25, 0.23, 0.09
这个命令可以快速查看机器的负载情况,显示的是开机时间、用户数、负载,负载三个数字意思是1分钟、5分钟、15分钟CPU的平均负载情况。我们应该怎么理解CPU平均负载呢?是不是其数值越小越好?结果并非这样。
首先,我们应该知道我们的处理器有几个处理器,每个处理器有几个核心,可以通过命令cat /proc/cpuinfo |grep "cpu cores"来查看。
在多核处理中,你的系统均值不应该高于处理器核心的总数量。
比如说你的机器是双核CPU,那么平均负载不应该高于2;如果是2个CPU,每个CPU是4核的,那么平均负载不应该高于8。通常,应该关注于五分钟或者十五分钟的平均负载。
2. vmstat
vmstat用来获得有关进程、虚拟内存、页面交换空间及CPU活动的信息,可以全面反映系统的负载情况。常用的方式是vmstat命令通过两个数字参数来统计信息,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如:
root@ubuntu:~# vmstat 3 3
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 820216 37088 507628 0 0 42 2 41 65 0 0 99 0 0
0 0 0 820216 37088 507628 0 0 0 0 356 495 0 0 99 0 0
1 0 0 745040 37120 507636 0 0 0 111 990 1409 3 18 79 1 0
上面的信息统计的是每隔3秒、统计共3次的状态。每一个栏位代表的是什么意思呢?
proc进程:
r:等待在CPU资源的进程数。这个数据比平均负载更加能够体现CPU负载情况,数据中不包含等待IO的进程。如果这个数值大于机器CPU核数,那么机器的CPU资源已经饱和。
b :表示阻塞的进程
Memory内存
swpd:正在使用虚拟的内存大小,单位k
free:空闲内存大小
buff:已用的buff大小,对块设备的读写进行缓冲
cache:已用的cache大小,文件系统的cache
Swap交换内存
si:每秒从交换区写入内存的大小(单位:kb/s)
so:每秒从内存写到交换区的大小
IO 磁盘
bi:每秒读取的块数(读磁盘),这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte
bo:每秒写入的块数(写磁盘)
system
in:每秒中断数,包括时钟中断
cs:每秒上下文切换数(每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。)
这两个值越大,会看到由内核消耗的cpu时间会越多。
CPU(百分比)
Us:用户进程执行消耗cpu时间(user time)。us的值比较高时,说明用户进程消耗的cpu时间多
Sy:系统进程消耗cpu时间(system time)。sys的值过高时,说明系统内核消耗的cpu资源多,这个不是良性的表现,我们应该检查原因。
Id:空闲时间(包括IO等待时间)
Wa:等待IO时间。Wa过高时,说明io等待比较严重,这可能是由于磁盘大量随机访问造成的,也有可能是磁盘的带宽出现瓶颈。
3. free
free命令可以查看系统内存的使用情况。
root@ubuntu:~# free -h
total used free shared buff/cache available
Mem: 1.9G 650M 795M 16M 536M 1.1G
Swap: 1.0G 0B 1.0G
-h表示以易读的单位显示。
4. top
top命令包含了前面好几个命令的检查的内容。比如系统负载情况(uptime)、系统内存使用情况(free)、系统CPU使用情况 (vmstat)等。因此通过这个命令,可以相对全面的查看系统负载的来源。同时,top命令支持排序,可以按照不同的列排序,方便查找出诸如内存占用最 多的进程、CPU占用率最高的进程等。选项的使用及输出的信息也和前面类似。
#常用操作
top //默认,每隔5秒显式所有进程的资源占用情况
top -d n //delay每隔n秒显式所有进程的资源占用情况
top -p 1234 -p 6789//每隔5秒显示pid是1234和pid是6789的两个进程的资源占用情况
top -d 2 -p 123 //每隔2秒显示pid是123的进程的资源使用情况下面简单的介绍一下top命令的输出,便于去查看资源的使用情况。
#top命令的输出
#第一行为开机时间,用户数,负载。和uptime输出类似
top - 13:54:48 up 1:49, 1 user, load average: 0.00, 0.00, 0.00
#第二行为总进程数,正在运行的、睡眠的、停止的、僵尸进程。
Tasks: 251 total, 1 running, 246 sleeping, 4 stopped, 0 zombie
#第三行为CPU的使用情况,和vmstat中输出的类似
%Cpu(s): 0.3 us, 1.3 sy, 0.0 ni, 98.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
#第四行为内存的使用
KiB Mem : 2030472 total, 671712 free, 714120 used, 644640 buff/cache
#第五行为交换内存的情况
KiB Swap: 1046524 total, 1046524 free, 0 used. 1100272 avail Mem
#主要的几个值为: NI “nice值,负值表示高优先级,正值表示低优先级”、 VIRT “进程使用的虚拟内存总量”、RES “进程使用的、未被换出的物理内存大小”、 SHR “共享内存大小”、S “进程状态”、TIME+ “进程使用CPU总时间”
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 













 2244
2244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









