







写在前面
在学习Redis的集群内容时,看到这么一句话:Redis并没有使用一致性hash算法,而是引入哈希槽的概念。而分布式缓存Memcached则是使用分布式一致性hash算法来实现分布式存储。所以就专门学习了一下
什么是分布式?什么是一致性?什么是哈希?
1)分布式(distributed)是指在多台不同的服务器中部署不同的服务模块,通过远程调用协同工作,对外提供服务。“分布式一致性hash算法”中的“分布式”就是指缓存数据的分布性。
集中式将一个系统的所有服务模块部署到了不同的服务器上,构成一个集群,通过负载均衡设备对外提供服务。集中式部署就像茶水间同时有多个饮水机提供服务,服务冗余部署。分布式部署则将系统拆分成不同的服务模块,然后将不同的服务模块部署在不同的服务器上。
2)一致性Wiki的定义:
Consistent hashing is a special kind of hashing such that when a hash table is resized, only K/n keys need to be remapped on average, where K is the number of keys, and n is the number of slots. In contrast, in most traditional hash tables, a change in the number of array slots causes nearly all keys to be remapped because the mapping between the keys and the slots is defined by a modular operation.
大概意思就是“一致性哈希是一种特殊的哈希算法,提供了这样的一个哈希表,当重新调整大小的时候,平均只有部分(k/n)key需要重新映射哈希槽,而不像传统哈希表那样几乎所有key需要需要重新映射哈希槽”。一致性hash能保证在分布式环境中,对key进行哈希的结果或者说key与节点之间的映射关系不会受节点的增加和删除而产生重大的变化。
3)hash,俗称“哈希”,也叫散列,是一种将任意长度的消息(数据)压缩到某一固定长度的消息摘要(数据)的算法。常见的hash算法有MD5,SHA等。hash算法具有几个重要的特性:不可逆性(即从hash值反推出原消息是不可能的)、抗冲突性(即给定消息M1,不存在另一个消息M2,使得Hash(M1)=Hash(M2))和分布均匀性(即hash的结果是均匀分布的)。Memcached中,存取数据时都要进行哈希映射。正是这几个特性,保证了memcached缓存中key值得唯一性。
分布式一致性hash算法使用背景
我们已经知道,memcached的分布式主要在于客户端的分布式算法。memcached客户端就像一个网络中的路由,经过特定的算法将数据分散的存在到memcached服务端的机器上,又从分散的memcached服务端的机器上提取数据。实际中,常见的存储和提取数据的算法有取模算法和本文分析的一致性hash算法。
取模算法算法的原理是:
hash(key)%N
其中key 代表数据的键,N 代表memcached服务器的数量。取模的结果就是memcached客户端要定位的memcached服务器。取模算法很明显,结果受N的影响,当服务器数量N增加或者减少的时候,原先的缓存数据定位几乎失效,缓存数据定位失效意味着要到数据库重新查询,这对于高并发的系统来说是致命的。于是,人们提出了一致性hash算法,最终目的是实现在移除、添加一个memcached服务器时对已经存在的缓存数据的定位影响尽可能的降到最小。
环形hash空间
通常,一个缓存数据的key经过hash后会得到一个32位的值,也就是0~2^32 - 1数值范围。我们可以把这个数值范围抽象成一个首尾相连环形的空间,我们称这个空间为环形hash空间。如下图所示:
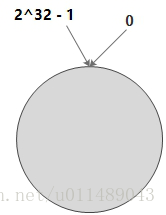
映射key、server节点到环形hash空间
有了环形hash空间之后,缓存数据的key经过hash后得到的值就映射到了环形hash空间。假设有key1、key2、key3、key4,经过hash后,映射到环形hash空间如下图所示。同理,我们可以把memcached服务器抽象成网络上的节点经过hash后映射到环形hash空间。假设有server1(可以是服务器的某些唯一标志信息,如ip等)、server2、server3
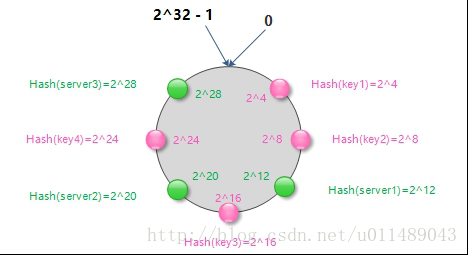
映射key到server节点
现在缓存key和server节点都经过一致性hash算法映射到了环形hash空间,现在就可以将缓存key和server节点的关系进行映射了。顺时针沿着环形hash空间,从某个缓存key开始,直到遇到一个server节点,那么该缓存key就存储到这个server节点上。如图:
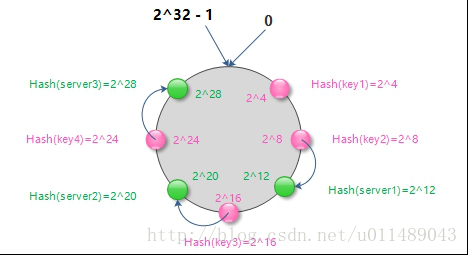
了解了key、server节点、hash空间之间的映射关系之后,已经清楚了缓存数据是怎样分布的存储到memcached服务器了。查找缓存数据的时候,也采用同样的映射方法来定位。
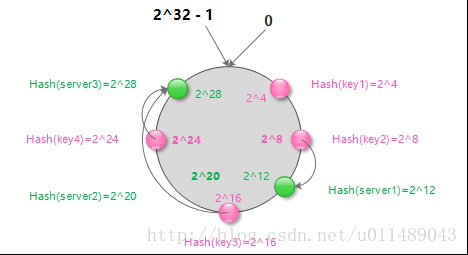
删除server节点
当在server集群中删除server2节点时,受影响的也仅是server1~server2之间的缓存数据Key3,这部分数据需要重新到数据库查找再次映射到server3节点上。如下图所示:
添加server节点
现在我们已经知道memcached存储和访问数据的策略了。那么当在server集群中增加一个server节点时,对数据访问的命中率又有什么影响呢。如下图,在server1和server2节点之间增加一个节点server4
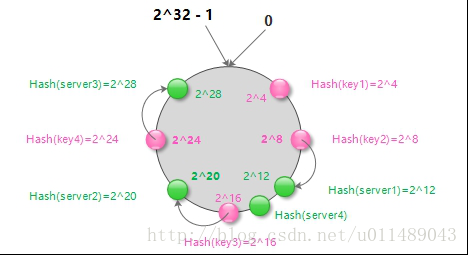
从上图可以看出,增加server4节点后,原有的缓存数据分布中,仅有server1和server4节点之间的数据进行了重新分布,这部分数据需要重新到数据库查找再次映射到新添加的server4节点上。尽管不能命中的缓存数据仍然存在,但相对于取模算法,已经是最大限度地抑制了hash键的重新分布。
虚拟节点的引入
我们已经知道,添加和删除节点都会影响缓存数据的分布。尽管hash算法具有分布均匀的特性,但是当集群中server数量很少时,他们可能在环中的分布并不是特别均匀,进而导致缓存数据不能均匀分布到所有的server上。
为解决这个问题,需要使用虚拟节点的思想:为每个物理节点(server)在环上分配100~200个点,这样环上的节点较多,就能抑制分布不均匀。当为cache定位目标server时,如果定位到虚拟节点上,就表示cache真正的存储位置是在该虚拟节点代表的实际物理server上。另外,如果每个实际server节点的负载能力不同,可以赋予不同的权重,根据权重分配不同数量的虚拟节点。
虚拟节点的hash计算可以采用对应节点的 IP 地址加数字后缀的方式。例如假设 serverA 的 IP 地址为 127.0.0.1 。
引入虚拟节点前,计算serverA 的 hash 值:
hash(“127.0.0.1”);
引入虚拟节点后,计算虚拟节点serverA1 和 serverA2 的 hash 值:
hash(“127.0.0.1#1”);
hash(“127.0.0.1#2”);
一致性hash算法与取模算法的比较
取模算法的方法简单,数据的分散性也可以,但其主要缺点是当添加或移除server节点时,缓存重新映射的代价相当巨大。添加或移除server节点时,余数就会产生巨变,这样就无法定位与存储时相同的server节点,从而影响缓存的命中率。
而一致性hash算法则最大限度的减少了server节点变化带来的影响,当节点变化时,只影响一个server节点的部分数据,且hash算法能够保证需要重新分布的缓存数据能映射到新的server节点中。
------至所有正在努力奋斗的程序猿们!加油!!
有码走遍天下 无码寸步难行
1024 - 梦想,永不止步!
爱编程 不爱Bug
爱加班 不爱黑眼圈
固执 但不偏执
疯狂 但不疯癫
生活里的菜鸟
工作中的大神
身怀宝藏,一心憧憬星辰大海
追求极致,目标始于高山之巅
一群怀揣好奇,梦想改变世界的孩子
一群追日逐浪,正在改变世界的极客
你们用最美的语言,诠释着科技的力量
你们用极速的创新,引领着时代的变迁
——乐于分享,共同进步,欢迎补充
——Any comments greatly appreciated
——诚心欢迎各位交流讨论!QQ:1138517609
——GitHub:https://github.com/selfconzrr
















 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











