







讲解pandas.core.groupby.GroupBy.apply的一个运用实例,经常结合numpy库和隐函数lamda来使用,官网API看得云里雾里的。如果对博客的数据感兴趣可以在第一届.腾讯社交广告高校算法大赛处下载。
#将DataFrame类型的dfTrain按照key='appID'进行分组,生成GroupBy对象(由每个appID对应的rows组成的对象),然后由apply函数对每个对象进行lambda隐函数对应的函数操作:计算每个appID对应的lable列的平均值。
#dfTrain数据量太多,在后面有少部分数据展示,用于帮助理解。
key = "appID"
dfCvr = dfTrain.groupby(key).apply(lambda df: np.mean(df["label"])).reset_index()
#给DataFrame的columns重新赋值
dfCvr.columns = [key, "avg_cvr"]
print('dfCvr test dfTrain.groupby.apply function.')
print(dfCvr)
#数据太多展示部分输出结果
test dfTrain.groupby.apply function.
appID avg_cvr
0 14 0.002515
1 25 0.006042
2 68 0.000431
3 75 0.000000
4 83 0.106286
5 84 0.018963
6 88 0.081780
7 100 0.030855
#dfTrain数据太多展示小部分
label clickTime conversionTime creativeID userID positionID \
0 0 170000 NaN 3089 2798058 293
1 0 170001 NaN 3089 195578 3659
2 0 170014 NaN 3089 1462213 3659
3 0 170030 NaN 3089 1985880 5581
4 0 170047 NaN 3089 2152167 5581
5 0 170053 NaN 3089 2152167 5581
connectionType telecomsOperator adID camgaignID advertiserID \
0 1 1 1321 83 10
1 0 2 1321 83 10
2 0 3 1321 83 10
3 1 1 1321 83 10
4 1 1 1321 83 10
5 1 1 1321 83 10
appID appPlatform
0 434 1
1 434 1
2 434 1
3 434 1
4 434 1
5 434 1 1、pandas的groupby函数:
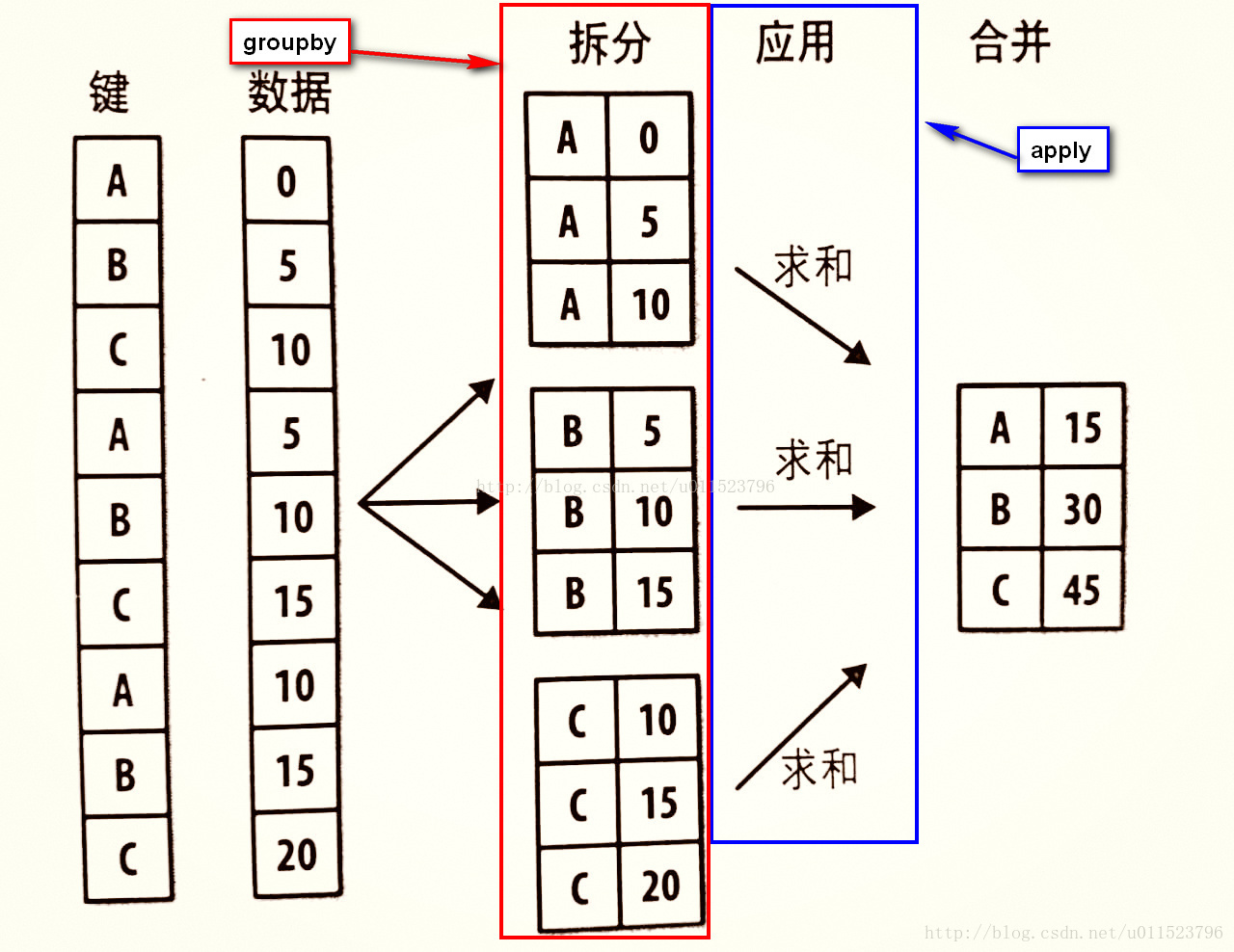
pandas提供了一个灵活高效的groupby函数,它使你能以一种自然的方式对数据集进行切片、切块、摘要等操作。根据一个或多个键(可以是函数、数组或DataFrame列名)拆分pandas对象。计算分组摘要统计,如计数、平均值、标准差,或用户自定义函数。对DataFrame的列应用各种各样的函数。应用组内转换或其他运算,如规格化、线性回归、排名或选取子集等。计算透视表或交叉表。执行分位数分析以及其他分组分析(目前没这么多深刻的体会,先记下来日慢慢领悟~)。
首先来看看下面这个非常简单的表格型数据集(以DataFrame的形式):
df6 = pd.DataFrame({'key1':['a', 'a', 'b', 'b', 'a'],
'key2':['one', 'two', 'one', 'two', 'one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
#输出结果
df6
0 1.006038 2.610016 a one
1 0.499684 1.004764 a two
2 1.056336 0.303721 b one
3 0.088034 0.723217 b two
4 -0.927159 -0.216762 a one
#假设你想要按key1进行分组,并计算data1列的平均值,我们可以访#data1,并根据key1调用groupby:
grouped = df6['data1'].groupby(df6['key1'])
print(grouped)
#输出结果,变量grouped是一个GroupBy对象,它实际上还没有进行任何计算,只是含有一些有关分组键df['key1']的中间数据而已,然后我们可以调用GroupBy的mean方法来计算分组平均值:
<pandas.core.groupby.SeriesGroupBy object at 0x1126b4c18>
grouped.mean()
#输出结果
Out[46]:
key1
a 0.192854
b 0.572185
Name: data1, dtype: float64
df.groupby('key1').mean()
#输出结果
data1 data2
key1
a 0.092027 0.555432
b 0.332136 -0.7157712、pandas的apply函数
apply是pandas库的一个很重要的函数,多和 groupby 函数一起用,也可以直接用于 DataFrame 和 Series 对象。主要用于数据聚合运算,可以很方便的对分组进行现有的运算和自定义的运算。
groupby与apply函数的使用原理图(拆分-应用-合并三部曲):














 3049
3049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









