







在旧的API中使用多文件输出,只需要自定义类继承MultipleTextOutputFormat类 重写它下面的generateFileNameForKeyValue 方法即可, 直接上例子。
输入文件 内容:

目的是按照 字母开头的文件输出,并统计单词计数,输出结果为:
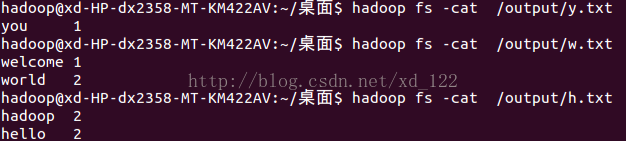
代码如下:
package defined;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.mapred.lib.MultipleTextOutputFormat;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.Iterator;
/**
* User: XD
*/
public class test {
static final String INPUT_PATH = "hdfs://localhost:9000/input";
static final Path OUTPUT_PATH = new Path("hdfs://localhost:9000/output");
public static class MapClass extends MapReduceBase implements Mapper<LongWritable, Text, Text, LongWritable> {
@Override
public void map(LongWritable key, Text value, OutputCollector<Text, LongWritable> output, Reporter reporter) throws IOException {
final String[] splited = value.toString().split(" ");
for(String val : splited){
output.collect(new Text(val), new LongWritable(1));
}
}
}
public static class ReduceClass extends MapReduceBase implements Reducer<Text, LongWritable, Text, LongWritable> {
@Override
public void reduce(Text key, Iterator<LongWritable> values,
OutputCollector<Text, LongWritable> collect, Reporter arg3)
throws IOException {
// TODO Auto-generated method stub
long sum = 0L;
while(values.hasNext()){
sum += values.next().get();
}
collect.collect(key, new LongWritable(sum));
}
}
public static class PartitionFormat extends MultipleTextOutputFormat<Text, LongWritable> {
@Override
protected String generateFileNameForKeyValue(Text key , LongWritable value,String name){
char c = key.toString().toLowerCase().charAt(0);
if(c>='a' && c<='z'){
return c+".txt";
}else{
return "other.txt";
}
}
}
public static void main(String[] args) throws IOException, URISyntaxException {
Configuration conf = new Configuration();
JobConf job = new JobConf(conf, test.class);
final FileSystem filesystem = FileSystem.get(new URI(INPUT_PATH),conf);
final Path outPath = OUTPUT_PATH;
if(filesystem.exists(outPath)){
filesystem.delete(outPath, true);
}
//1.1 读取文件 位置
FileInputFormat.setInputPaths(job, INPUT_PATH);
//输出文件位置
FileOutputFormat.setOutputPath(job, OUTPUT_PATH);
job.setJobName("Multipleoutput");
job.setMapperClass(MapClass.class);
job.setReducerClass(ReduceClass.class);
job.setInputFormat(TextInputFormat.class);
job.setOutputFormat(PartitionFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setNumReduceTasks(1);
JobClient.runJob(job);
}
}
但是在新的api中,就不能像上面那样操作,需要自定义MultipleOutputormat类,在重写generateFileNameForKeyValue 方法,似乎难度较大,在此 给出一个简单的操作,使用 org.apache.hadoop.mapred.lib.MultipleOutputs , 也是直接上例子:
输入:

还是统计输出到不同的文件。
输出结果:
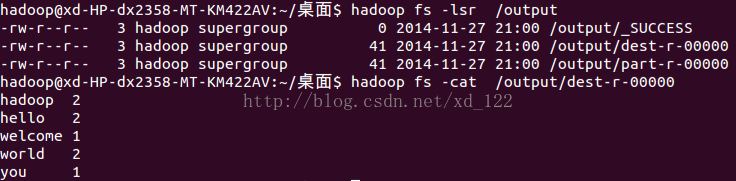
结果是dest-r-00000文件下
代码:
package wordcount;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
public class wordcount {
/**
* @param args
*/
static final String INPUT_PATH = "hdfs://localhost:9000/input";
static final String OUTPUT_PATH = "hdfs://localhost:9000/output";
public static class Map extends Mapper<LongWritable , Text , Text , LongWritable>{
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException{
final String[] splited = value.toString().split(" ");
for(String val : splited){
context.write(new Text(val), new LongWritable(1));
}
}
}
public static class Reduce extends Reducer<Text ,LongWritable, Text , LongWritable>{
private MultipleOutputs<Text,LongWritable> mos;
String dest;
protected void setup(Context context){
mos = new MultipleOutputs<Text, LongWritable>(context);
}
protected void reduce (Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException{
long sum = 0L;
char c = key.toString().toLowerCase().charAt(0);
for(LongWritable val : values){
sum += val.get();
}
if(c>='a' && c<='z'){
mos.write("dest", key, new LongWritable(sum));
}else{
mos.write("other", key, new LongWritable(sum));
}
context.write(key, new LongWritable(sum));
}
protected void cleanup(Context context) throws IOException, InterruptedException{
mos.close();
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException, URISyntaxException {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
final FileSystem filesystem = FileSystem.get(new URI(INPUT_PATH),conf);
final Path outPath = new Path(OUTPUT_PATH);
if(filesystem.exists(outPath)){
filesystem.delete(outPath, true);
}
Job job = new Job(conf,wordcount.class.getSimpleName());
//1.1 读取文件 位置
FileInputFormat.setInputPaths(job, INPUT_PATH);
//1.2指定的map类//1.3 map输出的key value 类型 要是和最终的输出类型是一样的 可以省略
job.setMapperClass(Map.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setJarByClass(wordcount.class);
//1.3 分区
job.setPartitionerClass(HashPartitioner.class);
//1.4分组
//1.5 归约
//2.1 copy 经由网络
//2.2 指定自定义的reduce类
job.setReducerClass(Reduce.class);
//指定 reduce的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//2.3指定写出到什么位置
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
MultipleOutputs.addNamedOutput(job, "dest", TextOutputFormat.class, Text.class, LongWritable.class);
MultipleOutputs.addNamedOutput(job, "other", TextOutputFormat.class, Text.class, LongWritable.class);
//提交到jobtracker执行。 此函数还将会打印出作业执行的详细信息
job.waitForCompletion(true);
}
}
由于懒惰,没有书写更好的例子,只是简单的介绍,并且并没有将路径写成通用的,读者可自行书写,如有更好的解决,还请大家不吝赐教,小弟拜谢!!














 1639
1639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









