









概要
本篇博客是Spark 任务调度概述详细流程中的最后一部分,介绍Executor执行task并返回result给Driver。
receive task
上一篇博客Spark 任务调度之Driver send Task,最后讲到Executor接收Task,如下
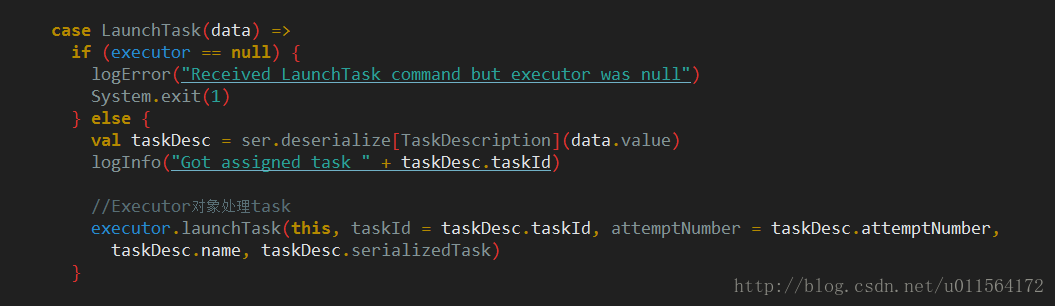
Executor的launchTask方法将收到的信息封装为TaskRunner对象,TaskRunner继承自Runnable,Executor使用线程池threadPool调度TaskRunner,如下
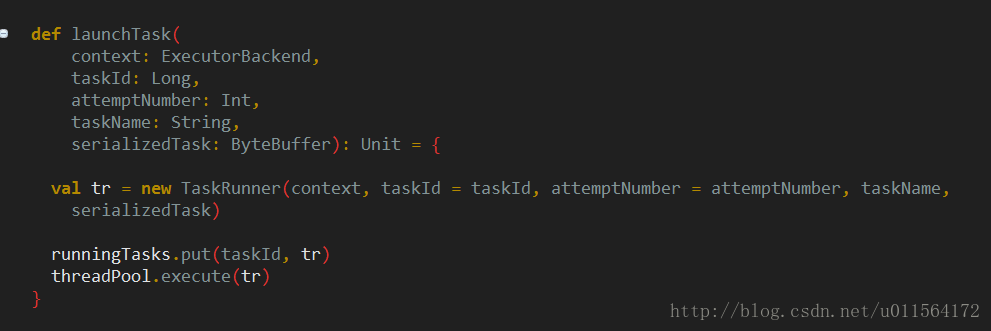
接下来查看TaskRunner中run方法对应的逻辑,我将其分为deserialize task、run task、sendback result三部分。
deserialize task
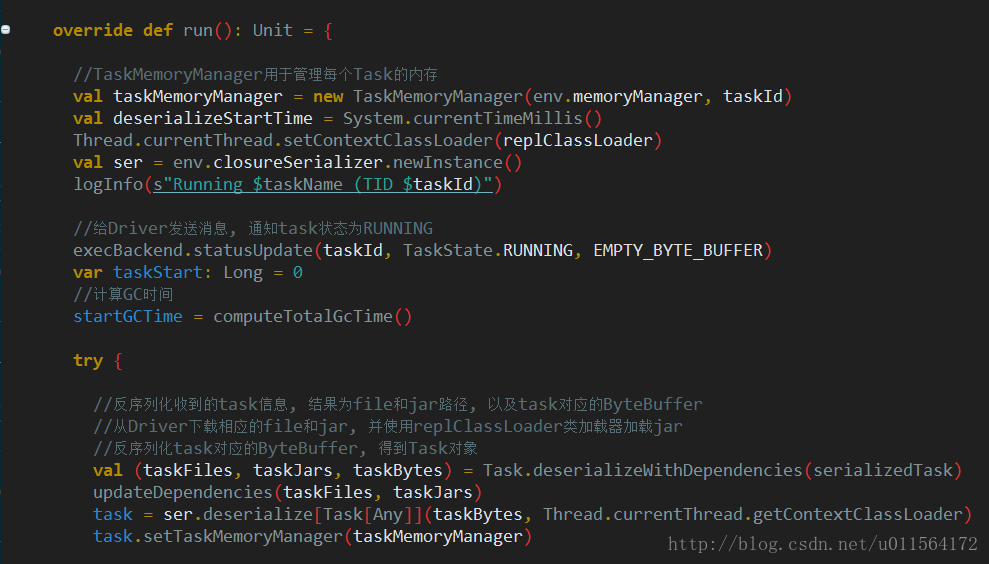
如上图注释,反序列化得到Task对象。
run task
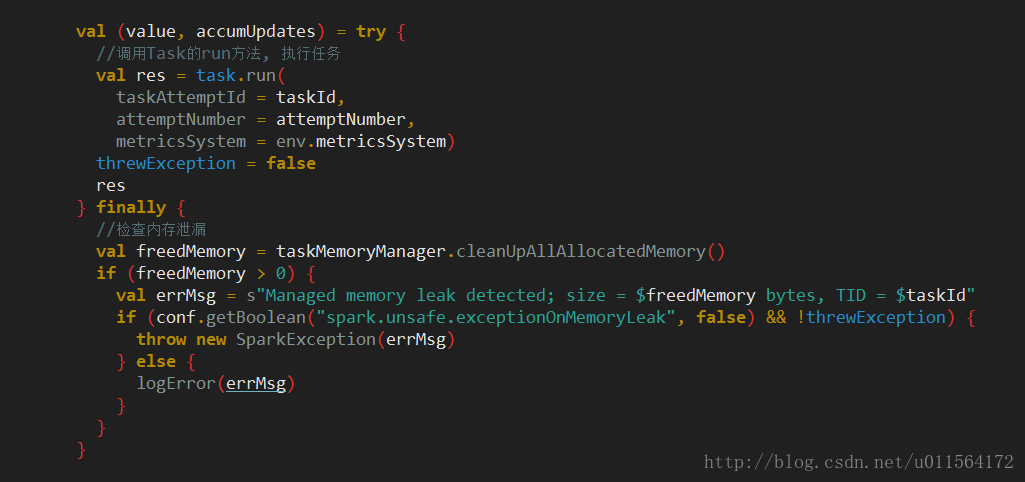
如上图注释,调用Task的run方法执行计算,Task是抽象类,其实现类有两个,ShuffleMapTask和ResultTask,分别对应shuffle和非shuffle任务。
Task的run方法调用其runTask方法执行task,我们以Task的子类ResultTask为例(ShuffleMapTask相比ResultTask多了一个步骤,使用ShuffleWriter将结果写到本地),如下
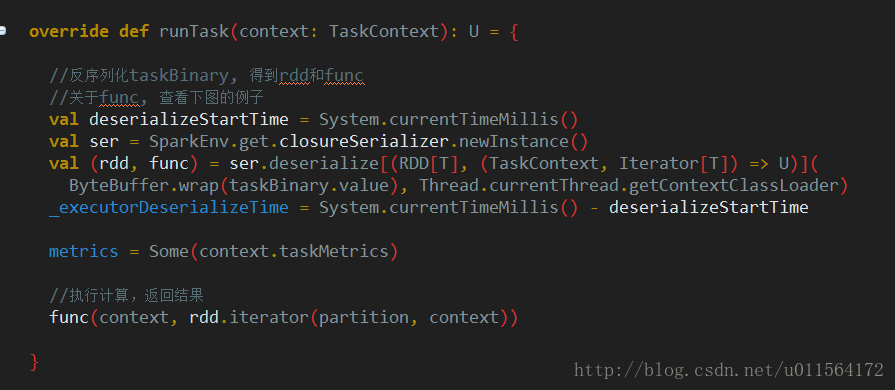
为了说明上图中的func,我们以RDD的map方法为例,如下

至此,task的计算就完成了,task的run方法返回计算结果。
sendback result
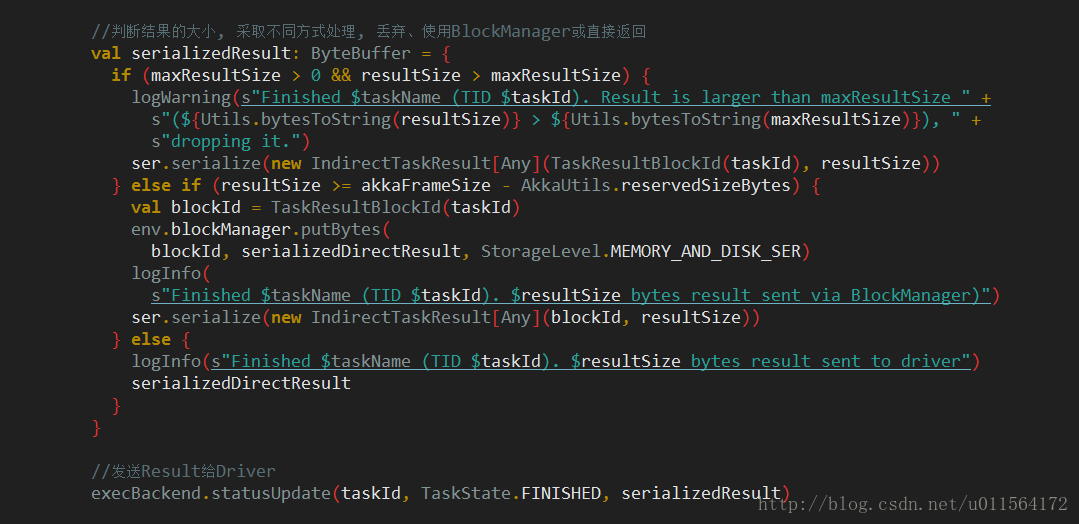
如上图注释,对计算结果进行序列化,再根据其大小采取相应方式处理,最后调用CoarseGrainedExecutorBackend的statusUpdate方法返回result给Driver。
总结
从Executor接收任务,到发送结果给Driver的流程,如下
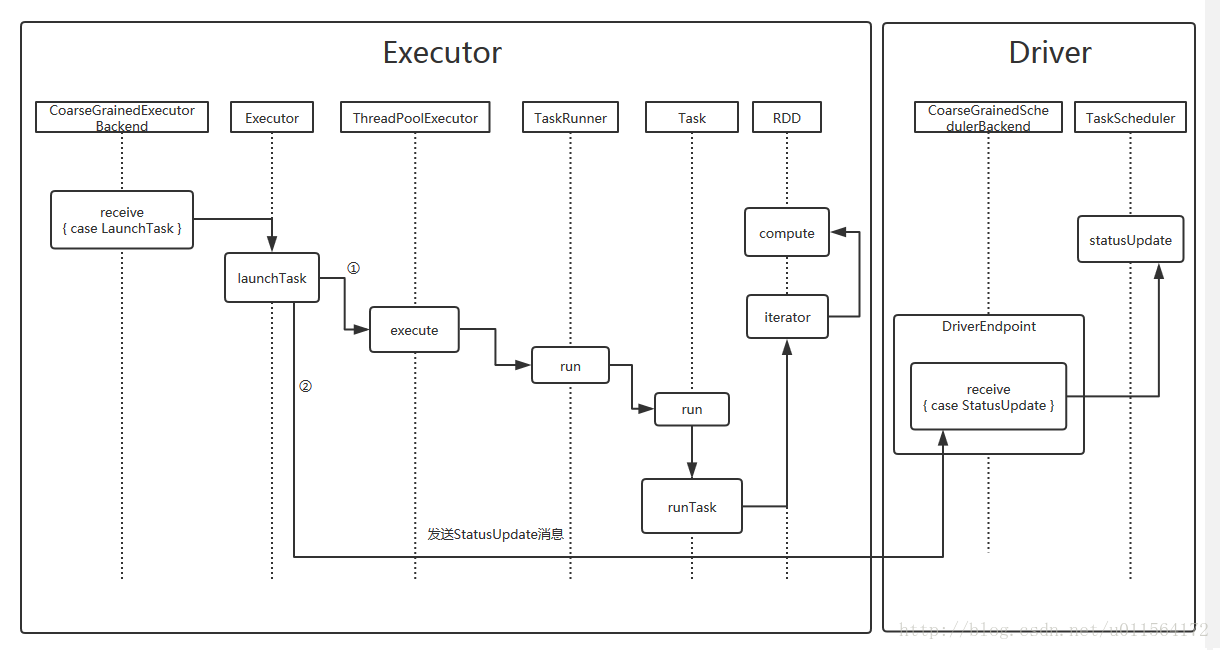
- 上图①所示路径,执行task任务。
- 上图②所示路径,将执行结果返回给Driver,后续Driver调用TaskScheduler处理返回结果,不再介绍。














 2864
2864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









