







数据结构中的有两个比较重要的算法。深度优先搜索和广度优先搜索。
二叉树中的深度搜索就是对一个分支进行遍历,而广搜就是一层一层的搜索。
下面通过代码进行讲解:
#include <iostream>
#include <queue>
using namespace std;
struct Node
{
Node *Left;
int Value;
Node *Right;
Node(int value=0, Node *left=NULL, Node *right=NULL):Value(value) , Left(left), Right(right) {};
};
Node *node[11];
void creat();
void DFS(Node*);
void BFS(Node*);
int main()
{
creat();
Node* Root = node[10];
cout<<"深搜结果为:"<<endl;
DFS(Root);
cout<<endl<<"广搜结果为:"<<endl;
BFS(Root);
return 0;
}
void creat()
{
node[1]=new Node(1);
node[2]=new Node(2);
node[3]=new Node(3);
node[4]=new Node(4);
node[5]=new Node(5, node[1], node[2]);
node[6]=new Node(6, node[3], node[4]);
node[7]=new Node(7);
node[8]=new Node(8,node[5],node[6]);
node[9]=new Node(9,node[7]);
node[10]=new Node(10,node[8],node[9]);
}
void DFS(Node* Root)
{
cout<<Root->Value<<" ";
if (Root->Left!=NULL)
DFS(Root->Left);
if (Root->Right!=NULL)
DFS(Root->Right);
return;
}
void BFS(Node *Root)
{
queue<Node*> Q;
Node * node ;
Q.push(Root);
while(!Q.empty())
{
node = Q.front();
cout<<node->Value<<" ";
if (node->Left!=NULL)
{
Q.push(node->Left);
}
if (node->Right!=NULL)
{
Q.push(node->Right);
}
Q.pop();
}
cout<<endl;
}
注意:其实这代码是不好的,主要是我为了让main函数看着简单一些把创建二叉树的函数写在main函数外面,不过不影响大家理解
首先要创建一棵二叉树主要用了构造函数知识,我想大家既然来看二叉树了,C++至少应该学了一些了(排除一些编程天才。。。)
假设大家已经看懂了二叉树的构造 下 面就是我构造的二叉树
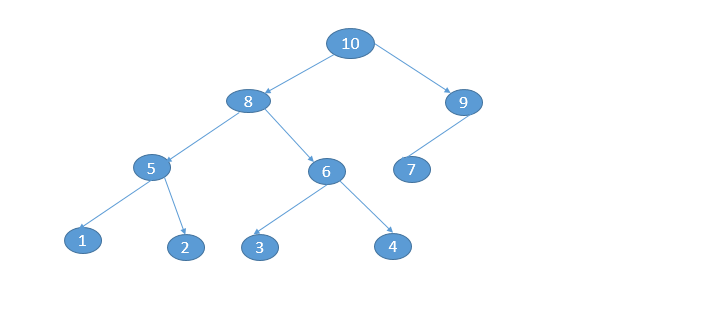
程序运行结果
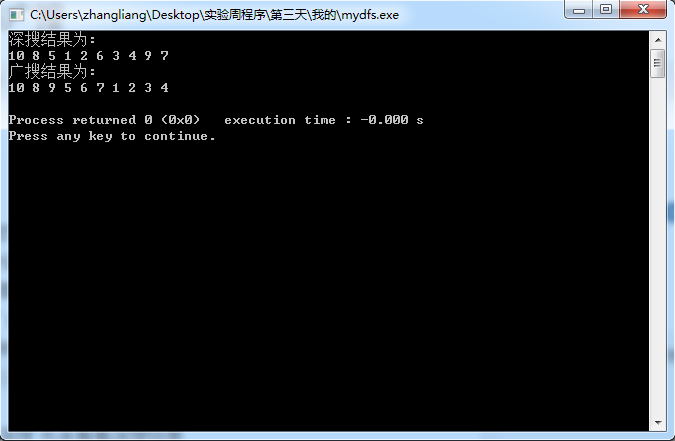
我们来讲解今天的主题之深搜 先来看看深搜
深搜:10 8 5 1 2 6 3 4 9 7
广搜:10 8 9 5 6 7 1 2 3 4
大家对照着图结合开头的几句话来具体感受到底什么是深搜,什么是广搜。
个人认为必须要对广搜和深搜之间的区别和这两种算法的遍历顺序有一个概念,这样看起代码来应该会很容易,大家可以结合我的gdb调试那篇文章来理解深搜。
不要嫌我啰嗦,说这么一大堆是想让大家更好的理解代码,如果上面的过程大家认真做了话,看懂代码是很容易的
深搜
void DFS(Node* Root)
{
cout<<Root->Value<<" ";
if (Root->Left!=NULL)
DFS(Root->Left);
if (Root->Right!=NULL)
DFS(Root->Right);
return;
}PS:请准备草稿纸,笔,在读的时候画一个栈图,极其有帮助
首先main函数入栈,接着DFS函数入栈(参数为node10),显然输出10,接着判断左边的node8,发现满足第一个if,于是DFS函数(node8)又进栈了,于是输出8,又满足第一个if,于是DFS函数(node5)又入栈啦,输出5,又满足第一个if,于是DFS函数(node1)又入栈啦,输出1,额,这次node1的left可不满足第一个if,right也不满足第二个if,啊哦,dfs(node1)就出栈了,于是栈顶变为dfs(node5),刚才dfs(node5)只执行了第一个if便被dfs(node1)压住了,现在终于解脱了,开始判断是否满足第二个if,显然满足,于是dfs(node2)又进栈了,dfs(node5)又被压住了(人家可是还有return没有执行呢,好悲催)。。。 node2进栈后输出2,又开始进行两个if的判断,显然不满足,于是return出栈了。啊啊啊,dfs(node5)终于可以return出栈了。
啊啊啊,想在终于轮到我dfs(node8)的天下了,终于可以开始判断第二个if了,第二个if满足,呃呃呃,dfs(node6)又入栈了。。。dfs(node8)又被压住了(return还没有执行呢)。
过程就是这样,不断地出栈入栈直到最终dfs(node10)出栈。这时候栈里只剩下main函数了(后面详细的进栈入栈过程希望大家可以丝毫不差的推出来,千万不能似懂非懂,模棱两可)
bfs
void BFS(Node *Root)
{
queue<Node*> Q;
Node * node ;
Q.push(Root);
while(!Q.empty())
{
node = Q.front();
cout<<node->Value<<" ";
if (node->Left!=NULL)
{
Q.push(node->Left);
}
if (node->Right!=NULL)
{
Q.push(node->Right);
}
Q.pop();
}
cout<<endl;
}bfs主要是用队列来实现的,如果把栈比作死胡同的话,那么队列就是一条很窄的单行道
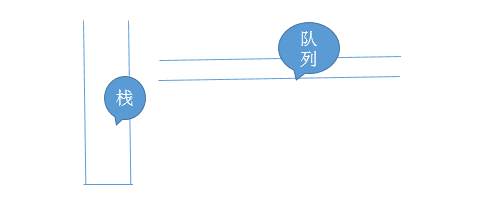
规则是先进先出首先把让node10入队,然后来一个while循环(不得不说程序设计中经常用while循环)只要这个队列不为空,我就循环。
现在进入单行道了(入队了)迎面驶来的的node10,显然先输10,然后执行两个if判断,全部成立,于是node8和node9又入队了
现在队中情况
node10 <- node8<- node9
然后node10驶出了单行道(q.pop();)于是迎面驶来node8,输出8,然后滴滴,node5和node6又进入单行道了现在队中情况
node8<-node9<-node5<-node6
然后node8驶出了单行道(q.pop();)
就这样不断地驶入和驶出,最终完成遍历;
好啦,二叉树就给大家讲解到这里了,如果哪儿又不理解或者我的讲解有错误的地方,欢迎在评论中告知,我会第一时间回复的。














 316
316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









