







1 概述
人工神经网络是20世纪80年代以来人工智能领域兴起的研究热点。它从信息处理角度对人脑神经元网络进行抽象,建立某种简单模型,按不同的连接方式组成不同的网络。神经网络是一种运算模型,由大量的节点(或称为神经元)之间互相联接构成。如下图(图片来源网络):
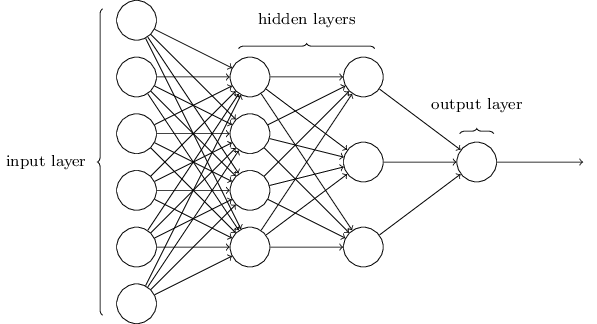
但是只有正向传播的神经网络在如何获取隐藏层的权值的问题上遇到了瓶颈。那能否先通过输出层得到输出结果和期望输出的误差来间接调整隐层的权值呢?BP算法就是采用这样的思想设计出来的算法,它的基本思想是,学习过程由信号的正向传播和误差的反向传播两个过程组成。如下图(图片来源网络):
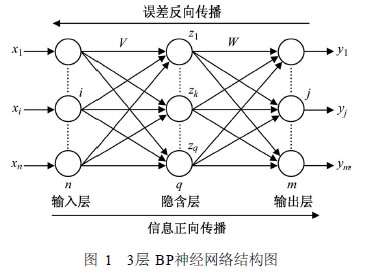
所以说BP神经网络是一种按照误差反向传播算法训练的多层前馈神经网络。参考维基:https://zh.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C
2组成
前向传播:将训练集数据输入到神经网络输入层,经过隐藏层,最后在输出层输出结果。
误差反向传播:由于输出结果和实际结果有误差,我们将误差从输出层向隐藏层反向传播,直到输入层。
迭代:在误差反向传播过程中,根据误差调整各种参数的值,不断迭代前向和反向传播,直至收敛。
3 示例
下面以一个简单的三层神经网络为例来简述前向传播、反向传播。网络结构图如下:
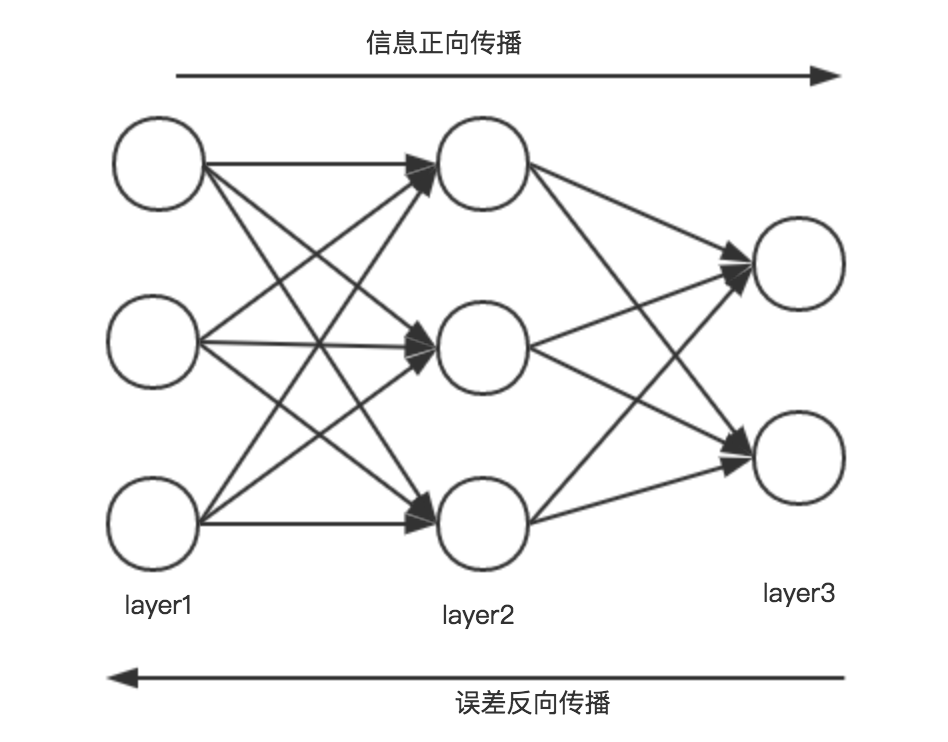
假设条件
- 不考虑偏置
- 激活函数为sigmoid函数 :g(z) = 11+e−z
- 损失函数为:L = 12∑Ni=1(yi−ai)2
- 权值用 w(i)jk 表示,i表示当前是第几层,j表示当前神经元在当前层的索引,k表示前一层神经元的索引。
- 除首层外,神经元输入用 z(i)j 表示,i表示当前是第几层,j表示当前神经元在当前层的索引。
- 除首层外,神经元输出用 a(m)n ,m表示当前是第几层,n表示当前神经元在当前层的索引。
3.1 前向传播:
第一层:
三个神经元为x
1
、x
2
、x
3
。
第二层:
三个神经元的输入,自上而下分别为:
z
(2)1
= w
(2)11
x
1
+ w
(2)12
x
2
+ w
(2)13
x
3
z
(2)2
= w
(2)21
x
1
+ w
(2)22
x
2
+ w
(2)23
x
3
z
(2)3
= w
(2)31
x
1
+ w
(2)32
x
2
+ w
(2)33
x
3
输出,自上而下分别为:
a
(2)1
= g(z
(2)1
)
a
(2)2
= g(z
(2)2
)
a
(2)3
= g(z
(2)3
)
第三层:
两个神经元的输入,自上而下分别为:
z
(3)1
= w
(3)11
a
(2)1
+w
(3)12
a
(2)2
+w
(3)13
a
(2)3
z
(3)2
=
w(3)21a(2)1
+
w(3)22a(2)2
+
w(3)23a(2)3
输出,也是最终的输出,自上而下分别为:
a
(3)1
= g(z
(3)1
)
a
(3)2
= g(z
(3)2
)
误差计算:
E =
12(y−a(3))2
3.2 误差反向传播:
误差反向传播是一种与最优化算法(如梯度下降法)结合使用的,用来训练人工神经网络的常用方法。该方法计算对网络中所有权重计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权重以最小化损失函数。
执行过程:
初始化网络权值(通常是小的随机值)
do
forEach 训练样本 ex
prediction = neural-net-output(network,ex) //正向传递
actual = teacher-output(ex)
计算输出单元的误差(prediction - actual)
计算
Δwh
对于所有隐藏层到输出层的权值 //反向传递
计算
Δwi
对于所有输入层到隐藏层的权值 //继续反向传递
更新网络权值 //输入层不会被误差估计改变
until 所有的样本正确分类或满足其他停止标准
return 该网络
3.3 梯度下降
梯度下降法的计算过程就是沿梯度下降的方向求解极小值(也可以沿梯度上升方向求解极大值)。
重复这个过程直到拟合 {
w(i)jk:=w(i)jk−α∂∂w(i)jkJ
}
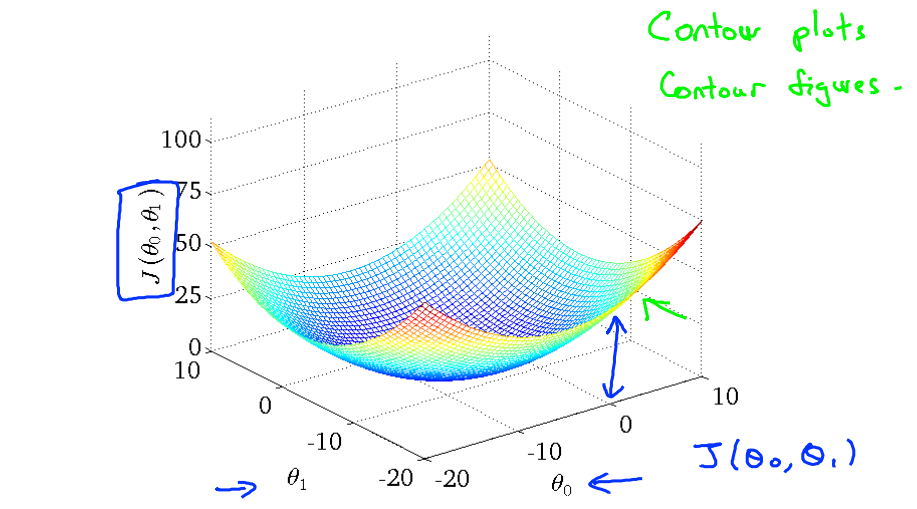
可能遇到的问题:出现局部最优解。如下图中左图含有局部最优解,右图没有局部最优解。
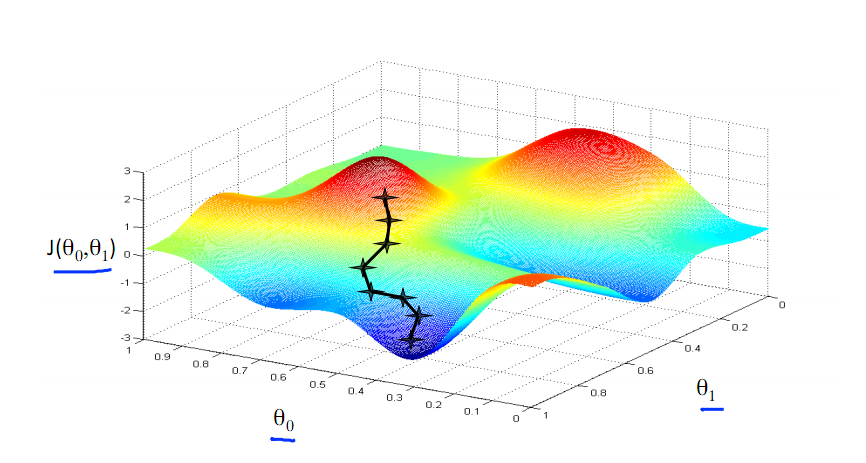
梯度下降的原理:
导数的概念:
f′(x0)=limΔx→0f(x0+Δx)−f(x0)Δx
由公式可以看出,对点 x0 的导数反应了函数在点( x0,y0 )处的瞬时变化速率,或者叫在点 x0 处的斜度。推广到多维函数中,就有了梯度的概念,梯度是一个向量组合,反映了多维图形中变化速率最快的方向。
下图展示了对单个特征w求导的过程,当w增大后,以新的w为基点求导,一直迭代到损失函数J(w)最小为止。
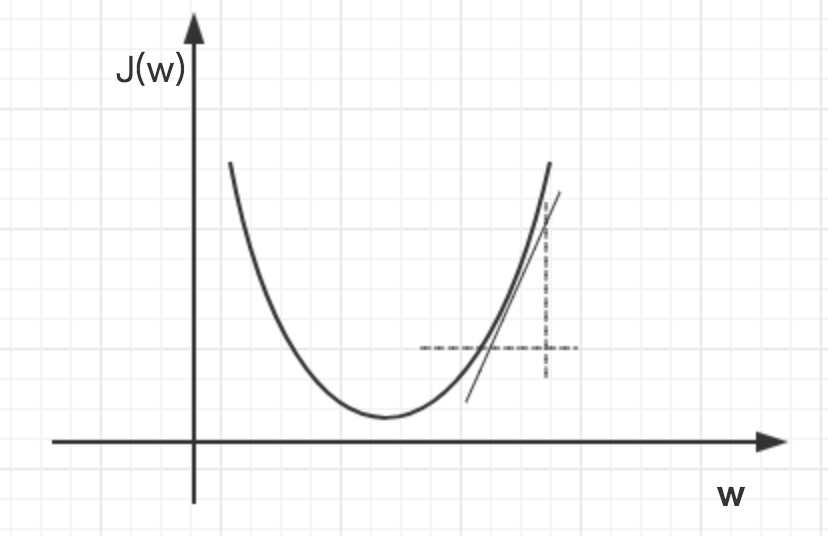
如果步长(学习率)太大,可能跳过最优解,则找不到最优解。如果步长太小,则会迭代很多次才能找到最优解。
在迭代过程中,梯度值会不断变小,w的变化速度也会越来越慢。
当梯度下降到一定数值后,每次迭代J(w)的变化会很小,这是可以设置一个阈值,只要变化小于这个阈值,就停止迭代。
如果J(w)不断变大,有可能是步长(学习率)太大,可适当调整步长。
4 公式推导
在BP神经网络中,误差信号反向传递过程比较复杂,它是基于Widrow-Hoff学习规则的。假设输出层的所有结果为
dj
,则误差函数为:
而BP神经网络的主要目的是反复修正权值和阀值,使得误差函数值达到最小。
Widrow-Hoff学习规则是通过沿着相对误差平方和的最速下降方向,连续调整网络的权值和阈值,根据梯度下降法,权值矢量的修正正比于当前位置上E(w,b)的梯度,对于第j个输出节点有:
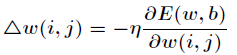
隐含层和输出层中对E求w的偏导:
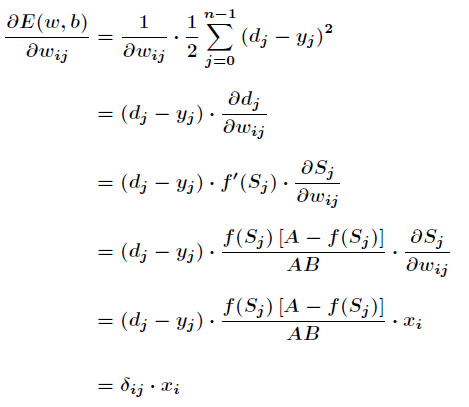
其中有:
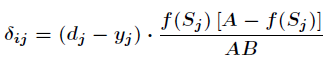
同样对于b有:
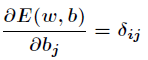
这就是著名的
δ
学习法则,这个规则又叫做Widrow-Hoff
学习规则或者纠错学习规则。
有了上述公式,根据梯度下降法,那么对于隐含层和输出层之间的权值和阀值调整如下:
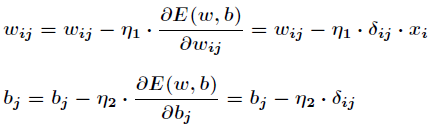
以上是隐藏层和输出层之间的阀值和权值调整,下面是输入层和隐藏层之间的阀值和权值调整。
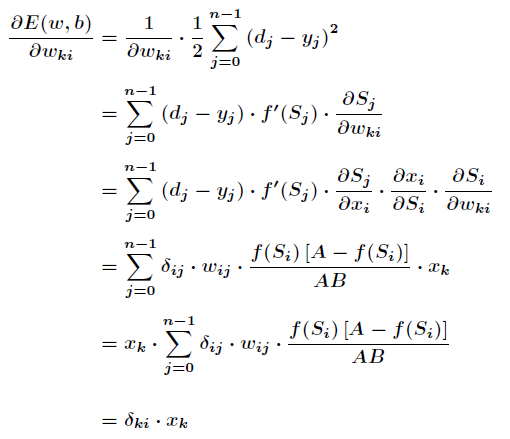
其中有
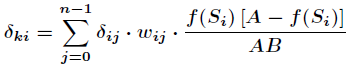
权值和阀值调整为:
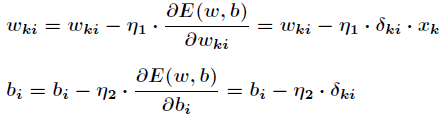














 1875
1875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









