







近期读了一篇文章
《Deep Heterogeneous Feature Fusion for Template-Based Face Recognition》
在本文中,通过大量的研究可以知道不同的深度网络会学习到不同的深度特征,并且某些网络能够较好的处理姿态和光照的变化,有的则会提取较多的局部信息。本文,作者提出了一种深度的基于模板的多种特征融合的网络。
本文的主要贡献在于:
- 1.本文提出了一种深度的融合网络,将两种比较流行的网络提取的特征进行融合,以此得到一个判别性较强的特征表示
- 2.当在一个模板中融合特征的时候,本文提出的方法能够将固有的几何信息同时考虑进去,以此得到一个增强型的基于模板的表示。
- 3.本文给了一系列的对实验的分析。
对于传统的特征融合的方法,multiple kernel learning(MKL)是用的最多的一种特征融合的方法。
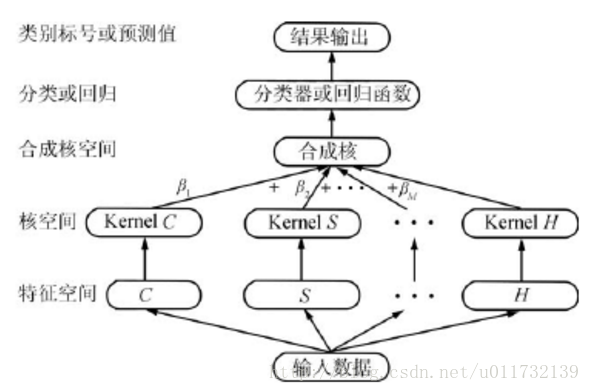
多核学习的核心思想是考录到不同的核可以学习到不同类型的特征信息,为了能够得到最好的预测结果,将多个核下的特征用一定对的方法更加有效的结合起来。除了MKL这种比较常用的方法,关于特征融合的方法还有CCA(Canonical Correlation Analysis),详细的参见《feature fusion method based on canonical correlation analysis and handwritten recognition》。
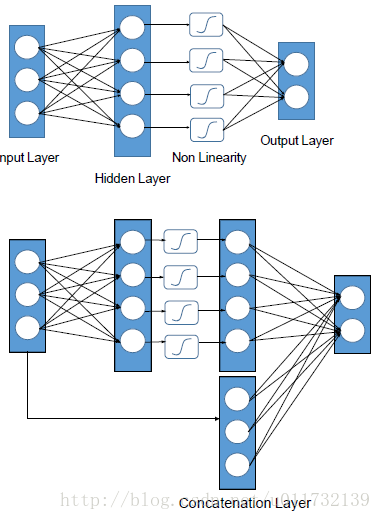
对于以往的大多数的深度特征的融合的方法太多,但是大部分都是用于视频的分类。近期Biliner CNNs的方法被提出来实现识别。本文提出的特征融合的方法不同于前面提到的方法,本文主要是将不同的网络结构和不同的特征维度下学习的特征进行融合。对于两个特征的融合问题可以如下图所示。
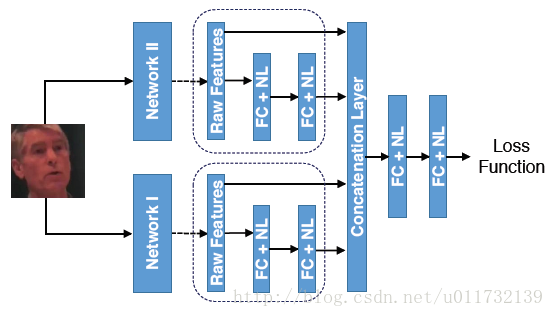
两个网络是两个预训练的DCNNs,学习到的特征称为raw features。两个features的维度分别为d1和d2。网络一是对tight bounding box进行特征学习,网络二是对loose bounding box进行特征学习,然后利用融合网络进行融合。
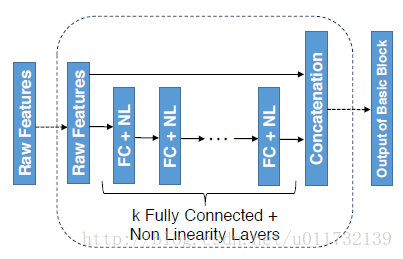
接下来,作者用一个简单的三层网络来说明融合网络。图中的隐藏层中有较多的激活单元,在隐藏层后面紧接着一个非线性激活函数,比如tanh。对于融合网络,输入的raw features经过网络之后,得到特征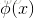
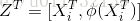
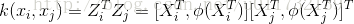
本文提到一个损失函数是hinge loss,即E(z) = max(0,1-z)。Hinge Loss 最常用在 SVM 中的最大化间隔分类中。对可能的输出 t = ±1 和分类器分数 y,预测值 y 的 hinge loss 。
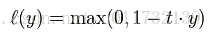
看到 y 应当是分类器决策函数的“原始”输出,而不是最终的类标。
作者在文中提到,本文提出的方法有个优点是,多提取出来的特征可以用于以后的度量学习中,然后计算人脸验证中的相似度。
到此为止,作者只是提到该如何将特征进行融合。后面作者主要是阐述基于模板的特征融合。一般的方法是采用平均pooling的方法,但是这种方法不适用于本文提出的方法,原因在于本文的融合特征中还包括了固有的几何信息,而平均池化会导致这些信息的丢失,因此作者首先将raw特征进行平均池化,然后融合平均raw特征。
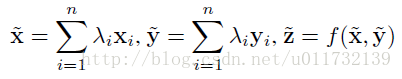
接下来,作者进行了较多的实验,从实验的结果来看,还是比较好的。总结来说有三点原因:1.能够联合学习非线性高维的深度信息。2.生成了一种判别性比较强的特征表示模板,该模板中包括了人脸的固有的几何信息。














 2916
2916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









