







新建一个Maven项目、在pom文件中加入WebMagic必须的一些jar包.
测试类:
public class App implements PageProcessor
{
private Site site = Site.me().setSleepTime(1);
int temp=1;
//执行这个main方法,即可在控制台看到抓取结果。webmagic默认有3秒抓取间隔,请耐心等待。
public static void main( String[] args )
{
//Spider是爬虫的入口类,addurl为入口url
Spider oschinaSpider = Spider.create(new App()).addUrl("http://blog.csdn.net/CHENYUFENG1991/article/list/1")
//Pipeline是结果输出和持久化的接口,这里ConsolePipeline表示结果输出到控制台
.addPipeline(new ConsolePipeline());
try {
//添加到JMT监控中
SpiderMonitor.instance().register(oschinaSpider);
//设置线程数
//oschinaSpider.thread(5);
oschinaSpider.run();
} catch (JMException e) {
e.printStackTrace();
}
}
//process(过程)
public void process(Page page) {
//通过page.putField()来保存抽取结果
//page.getHtml().xpath()则是按照某个规则对结果进行抽取,这里抽取支持链式调用
List<String> pages=page.getHtml().xpath("[@class='pagelist']").links().all();
if (pages.size()>5) {
pages.remove(pages.size()-1);
}
page.addTargetRequests(pages);//用于获取所有满足"(http://blog\\.csdn\\.net/u012012240/article/month/2016/08/\\d+)"这个正则表达式的链接
//区分是列表页面还是信息页面
if (page.getUrl().regex("article/list").match()) {
List<String> links = page.getHtml().xpath("[@class='link_title']").links().regex("http://blog\\.csdn\\.net/chenyufeng1991/article/details/\\d+").all();
//通过page.addTargetRequests()方法来增加要抓取的URL
page.addTargetRequests(links);
}else {
System.out.println("记录数:"+temp++);
page.putField("title", page.getHtml().xpath("//[@class='link_title']/a/text()").toString());
}
}
public Site getSite() {
return site;
}
}
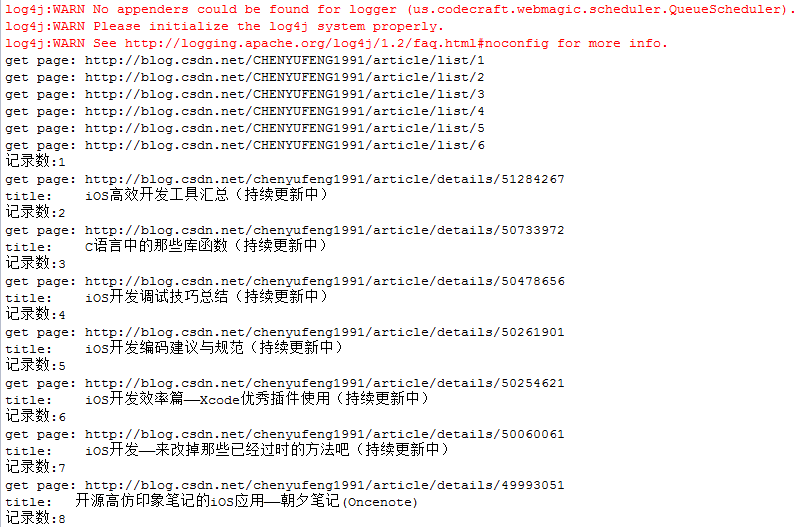
运行结果为:

















 1626
1626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









