







一、提取方式
从网页中提取数据有很多方法,概况起来大概有这么三种方式,首先是正则,然后是流行的Beautiful Soup模块,最后是强大的Lxml模块。
1、正则表达式:最原始的方法,通过编写一些正则表达式,然后从HTML/XML中提取数据。
2、Beautiful Soup模块:Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据的 Python 库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup 会帮你节省数小时甚至数天的工作时间。
3、Lxml模块:lxml是基于libxm12这一XML解析库的Python封装,该模块使用C语言编写,解析速读比Beautiful Soup模块快,不过安装更为复杂。
Scrapy使用了一种基于 XPath 和 CSS 表达式机制: Scrapy Selectors。 关于selector和其他提取机制的信息请参考 Selector文档
这里给出XPath表达式的例子及对应的含义:
/html/head/title: 选择HTML文档中<head>标签内的<title>元素/html/head/title/text(): 选择上面提到的<title>元素的文字//td: 选择所有的<td>元素//div[@class="mine"]: 选择所有具有class="mine"属性的div元素
上边仅仅是几个简单的XPath例子,XPath实际上要比这远远强大的多。 如果您想了解的更多,我们推荐 这篇XPath教程 。
为了配合XPath,Scrapy除了提供了 Selector 之外,还提供了方法来避免每次从response中提取数据时生成selector的麻烦。
Selector有四个基本的方法(点击相应的方法可以看到详细的API文档):
xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表 。css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表.extract(): 序列化该节点为unicode字符串并返回list。re(): 根据传入的正则表达式对数据进行提取,返回unicode字符串list列表。
为了介绍Selector的使用方法,接下来我们将要使用内置的 Scrapy shell 。Scrapy Shell需要您预装好IPython(一个扩展的Python终端,可通过命令安装: pip install ipython)。
您需要进入项目的根目录,执行下列命令来启动shell:
scrapy shell "http://blog.csdn.net/u011781521/article/details/70182815"注意:当您在终端运行Scrapy时,请一定记得给url地址加上引号,否则包含参数的url(例如 & 字符)会导致Scrapy运行失败。
shell的输出:
G:\Scrapy_work\myfendo>scrapy shell "http://blog.csdn.net/u011781521/article/details/70182815"
2017-04-15 21:01:18 [scrapy.utils.log] INFO: Scrapy 1.3.3 started (bot: myfendo)
2017-04-15 21:01:18 [scrapy.utils.log] INFO: Overridden settings: {'BOT_NAME': 'myfendo', 'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0, 'NEWSPIDER_MODULE': 'myfendo.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['myfendo.spiders']}
2017-04-15 21:01:18 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole']
2017-04-15 21:01:19 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-04-15 21:01:19 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-04-15 21:01:19 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2017-04-15 21:01:19 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2017-04-15 21:01:19 [scrapy.core.engine] INFO: Spider opened
2017-04-15 21:01:19 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://blog.csdn.net/robots.txt> (referer: None)
2017-04-15 21:01:19 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://blog.csdn.net/u011781521/article/details/70182815> (referer: None)
2017-04-15 21:01:20 [traitlets] DEBUG: Using default logger
2017-04-15 21:01:20 [traitlets] DEBUG: Using default logger
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x000002B5B7E512E8>
[s] item {}
[s] request <GET http://blog.csdn.net/u011781521/article/details/70182815>
[s] response <200 http://blog.csdn.net/u011781521/article/details/70182815>
[s] settings <scrapy.settings.Settings object at 0x000002B5B8E1DB38>
[s] spider <DefaultSpider 'default' at 0x2b5b909f358>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
In [1]:当shell载入后,您将得到一个包含response数据的本地 response 变量。输入 response.body 将输出response的包体
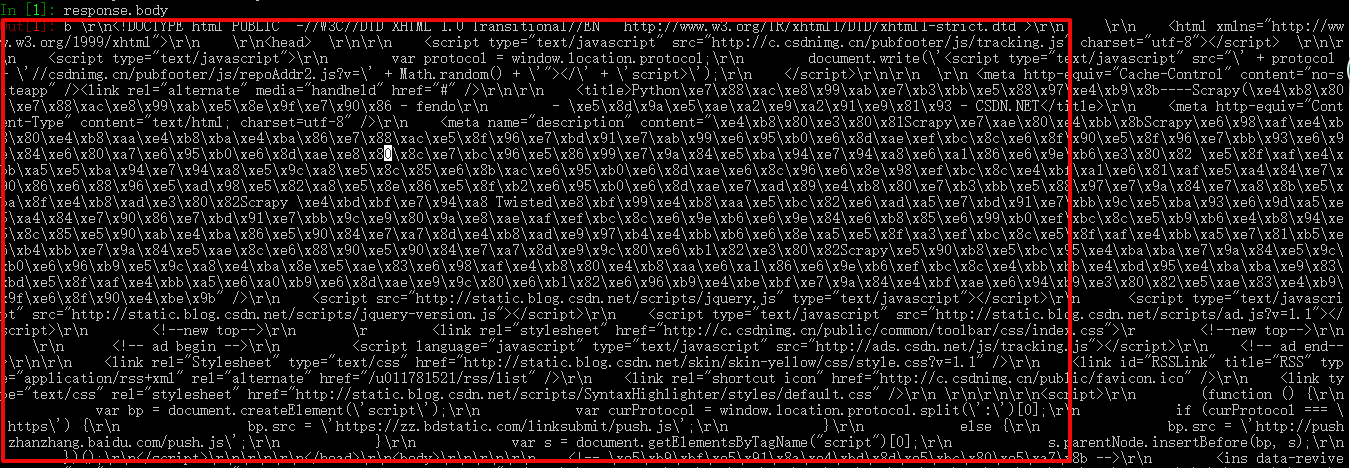
输入 response.headers 可以看到response的包头。
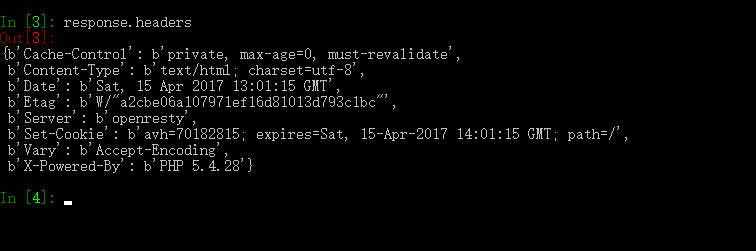
更为重要的是,当输入 response.selector 时, 您将获取到一个可以用于查询返回数据的selector(选择器), 以及映射到 response.selector.xpath() 、 response.selector.css() 的快捷方法(shortcut): response.xpath() 和 response.css() 。
同时,shell根据response提前初始化了变量 sel 。该selector根据response的类型自动选择最合适的分析规则(XML vs HTML)。
让我们来试试:
In [4]: response.xpath('//title')
Out[4]: [<Selector xpath='//title' data='<title>Python爬虫系列之----Scrapy(一)爬虫原理 - fe'>]
In [5]: response.xpath('//title').extract()
Out[5]: ['<title>Python爬虫系列之----Scrapy(一)爬虫原理 - fendo\r\n - 博客频道 - CSDN.NET</title>']
In [6]: response.xpath('//title/text()')
Out[6]: [<Selector xpath='//title/text()' data='Python爬虫系列之----Scrapy(一)爬虫原理 - fendo\r\n '>]
In [7]: response.xpath('//title/text()').extract()
Out[7]: ['Python爬虫系列之----Scrapy(一)爬虫原理 - fendo\r\n - 博客频道 - CSDN.NET']
二、提取数据
让我们从返回的response中提取数据,可以结合Firebug来观察HTML源码并确定合适的XPath表达式
文章的标题:
response.xpath('//h1/span/a/text()').extract()
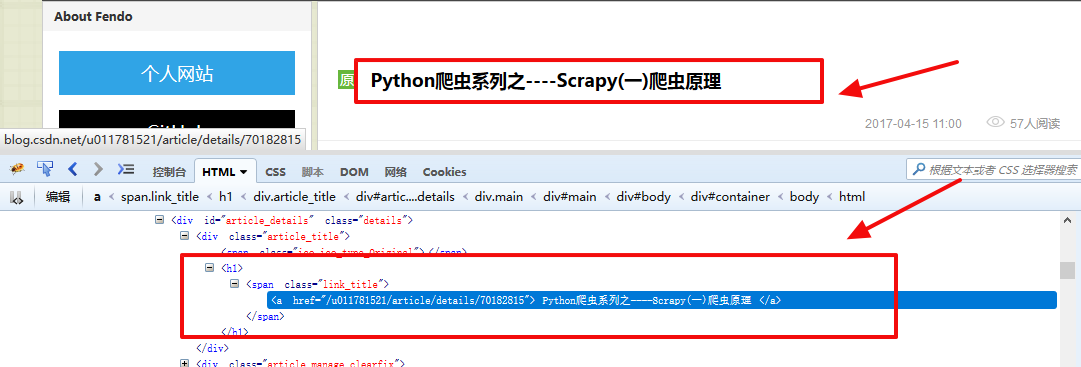
输出的结果为:

网页中的链接:
response.xpath("//span/a[@href='https://scrapy.org/']/text()").extract()
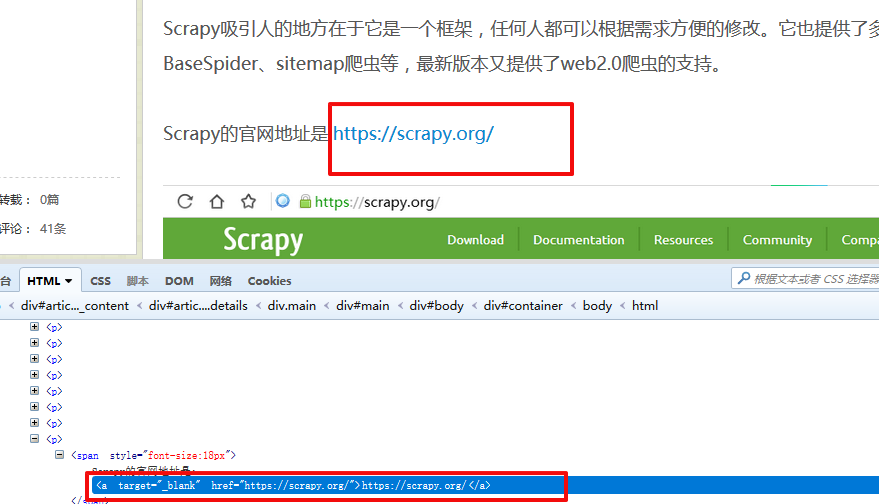
输出结果为:

网页的描述:
response.xpath("//meta[@name='description']").extract()
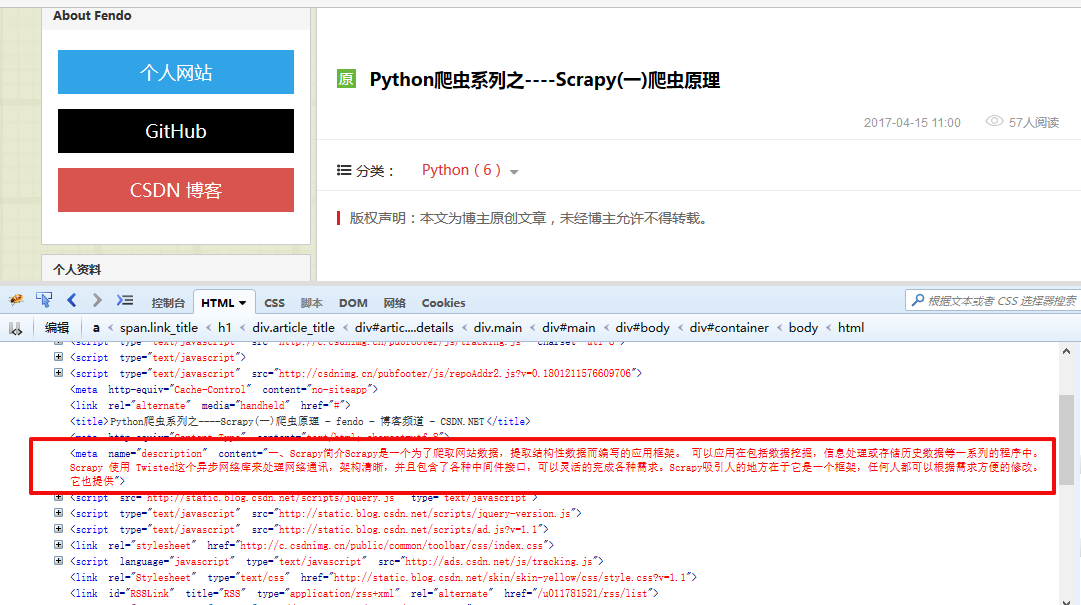
输出结果为:

三、使用Item
Item 对象是自定义的python字典。 您可以使用标准的字典语法来获取到其每个字段的值。(字段即是我们之前用Field赋值的属性):
一般来说,Spider将会将爬取到的数据以 Item 对象返回。所以为了将爬取的数据返回,我们最终的代码将是:
# -*- coding: utf-8 -*-
import scrapy
from myfendo.items import MyfendoItem
class MyfendosSpider(scrapy.Spider):
name = "myfendos"
allowed_domains = ["csdn.net"]
start_urls = [
"http://blog.csdn.net/u011781521/article/details/70182815",
]
def parse(self, response):
item=MyfendoItem()
item['title']=response.xpath('//h1/span/a/text()')
item['link']=response.xpath("//span/a[@href='https://scrapy.org/']/text()")
item['desc']=response.xpath("//meta[@name='description']")
yield item
现在运行爬虫将会产生 MyfendoItem对象:
G:\Scrapy_work\myfendo>scrapy crawl myfendos
2017-04-15 21:50:54 [scrapy.utils.log] INFO: Scrapy 1.3.3 started (bot: myfendo)
2017-04-15 21:50:54 [scrapy.utils.log] INFO: Overridden settings: {'BOT_NAME': 'myfendo', 'NEWSPIDER_MODULE': 'myfendo.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['myfendo.spiders']}
2017-04-15 21:50:54 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2017-04-15 21:50:54 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-04-15 21:50:54 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-04-15 21:50:54 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2017-04-15 21:50:54 [scrapy.core.engine] INFO: Spider opened
2017-04-15 21:50:54 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-04-15 21:50:54 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6024
2017-04-15 21:50:55 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://blog.csdn.net/robots.txt> (referer: None)
2017-04-15 21:50:55 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://blog.csdn.net/u011781521/article/details/70182815> (referer: None)
2017-04-15 21:50:55 [scrapy.core.scraper] DEBUG: Scraped from <200 http://blog.csdn.net/u011781521/article/details/70182815>
{'desc': [<Selector xpath="//meta[@name='description']" data='<meta name="description" content="一、Scra'>],
'link': [<Selector xpath="//span/a[@href='https://scrapy.org/']/text()" data='https://scrapy.org/'>],
'title': [<Selector xpath='//h1/span/a/text()' data='\r\n Python爬虫系列之----Scrapy(一)爬虫原理 '>]}
2017-04-15 21:50:55 [scrapy.core.engine] INFO: Closing spider (finished)
2017-04-15 21:50:55 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 467,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 17315,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2017, 4, 15, 13, 50, 55, 392037),
'item_scraped_count': 1,
'log_count/DEBUG': 4,
'log_count/INFO': 7,
'response_received_count': 2,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2017, 4, 15, 13, 50, 54, 786607)}
2017-04-15 21:50:55 [scrapy.core.engine] INFO: Spider closed (finished)
G:\Scrapy_work\myfendo>四、保存爬取到的数据
最简单存储爬取的数据的方式是使用 Feed exports:
scrapy crawl myfendos -o items.json
G:\Scrapy_work\myfendo>scrapy crawl myfendos -o items.json
2017-04-15 22:19:02 [scrapy.utils.log] INFO: Scrapy 1.3.3 started (bot: myfendo)
2017-04-15 22:19:02 [scrapy.utils.log] INFO: Overridden settings: {'BOT_NAME': 'myfendo', 'FEED_FORMAT': 'json', 'FEED_URI': 'items.json', 'NEWSPIDER_MODULE': 'myfendo.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['myfendo.spiders']}
2017-04-15 22:19:02 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.feedexport.FeedExporter',
'scrapy.extensions.logstats.LogStats']
2017-04-15 22:19:03 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-04-15 22:19:03 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-04-15 22:19:03 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2017-04-15 22:19:03 [scrapy.core.engine] INFO: Spider opened
2017-04-15 22:19:03 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-04-15 22:19:03 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6024
2017-04-15 22:19:03 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://blog.csdn.net/robots.txt> (referer: None)
2017-04-15 22:19:04 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://blog.csdn.net/u011781521/article/details/70182815> (referer: None)
2017-04-15 22:19:04 [scrapy.core.scraper] DEBUG: Scraped from <200 http://blog.csdn.net/u011781521/article/details/70182815>
{'desc': ['<meta name="description" '
'content="一、Scrapy简介Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 '
'可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。Scrapy 使用 '
'Twisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供">'],
'link': ['https://scrapy.org/'],
'title': ['\r\n Python爬虫系列之----Scrapy(一)爬虫原理 \r\n ']}
2017-04-15 22:19:04 [scrapy.core.engine] INFO: Closing spider (finished)
2017-04-15 22:19:04 [scrapy.extensions.feedexport] INFO: Stored json feed (1 items) in: items.json
2017-04-15 22:19:04 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 467,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 17313,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2017, 4, 15, 14, 19, 4, 130548),
'item_scraped_count': 1,
'log_count/DEBUG': 4,
'log_count/INFO': 8,
'response_received_count': 2,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2017, 4, 15, 14, 19, 3, 323475)}
2017-04-15 22:19:04 [scrapy.core.engine] INFO: Spider closed (finished)
G:\Scrapy_work\myfendo>该命令将采用 JSON 格式对爬取的数据进行序列化,生成 items.json 文件。
也可以采用下面的方法保存JSON数据:
1.修改pipelines.py文件
from scrapy import signals
import json
import codecs
class JsonWithEncodingCnblogsPipeline(object):
def __init__(self):
self.file = codecs.open('myitems.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()注意类名为JsonWithEncodingCnblogsPipeline哦!settings.py中会用到
2.修改settings.py,添加以下两个配置项
ITEM_PIPELINES = {
'myfendo.pipelines.JsonWithEncodingCnblogsPipeline': 300,
}
LOG_LEVEL = 'INFO'
scrapy crawl myfendos
输出结果为:
G:\Scrapy_work\myfendo>scrapy crawl myfendos
2017-04-15 22:24:42 [scrapy.utils.log] INFO: Scrapy 1.3.3 started (bot: myfendo)
2017-04-15 22:24:42 [scrapy.utils.log] INFO: Overridden settings: {'BOT_NAME': 'myfendo', 'LOG_LEVEL': 'INFO', 'NEWSPIDER_MODULE': 'myfendo.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['myfendo.spiders']}
2017-04-15 22:24:42 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2017-04-15 22:24:42 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-04-15 22:24:42 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-04-15 22:24:42 [scrapy.middleware] INFO: Enabled item pipelines:
['myfendo.pipelines.JsonWithEncodingCnblogsPipeline']
2017-04-15 22:24:42 [scrapy.core.engine] INFO: Spider opened
2017-04-15 22:24:42 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-04-15 22:24:43 [scrapy.core.engine] INFO: Closing spider (finished)
2017-04-15 22:24:43 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 467,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 17315,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2017, 4, 15, 14, 24, 43, 434983),
'item_scraped_count': 1,
'log_count/INFO': 7,
'response_received_count': 2,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2017, 4, 15, 14, 24, 42, 660934)}
2017-04-15 22:24:43 [scrapy.core.engine] INFO: Spider closed (finished)
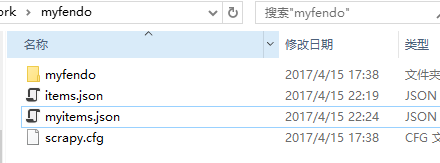
G:\Scrapy_work\myfendo>会生成一个myitems.json的文件














 430
430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









