









YOLO2
YOLO2是YOLO的升级版本,在YOLO的基础上用到了很多trick,尤其是结合了anchor box。 论文:YOLO9000:Better, Faster, Stronger
我个人觉得YOLO2是在YOLO的基础上,把多种物体检测网络(例:Faster R-CNN)和分类网络(ResNet,GoogleNet)的优点揉入进去,并且很酷炫的使用例如ImageNet一样的分类数据集训练了最终物体分类部分,使用例如COCO一样的检测数据集训练检测定位部分,这种联合训练方式感觉很有搞头。
Introduction
论文主要工作有两部分:
- 改进YOLO的多个部分,整出一个YOLOv2
- 提出了一种层次性联合训练方法,可以使用ImageNet分类数据集和COCO检测数据集同时对模型训练,最终整出来个YOLO9000,可以识别9000多种物体.
正如标题一样,论文从Better,Faster,Stronger三个方面介绍了对YOLO的改进,我们也就从这三个方面总结YOLO2。
Better
Batch Normalization
Batch Normalization来自论文Batch Normalization: Accelerating Deep Network Training b
y Reducing Internal Covariate Shift。使用BN的好处对数据分布做了修正,这样网络可以更快更好的学习。
在网络的每个卷积层后增加Batch Norm,同时弃用了dropout,网络的上升了2%mAP.
High Resolution Classifier
原本的所有的state-of-the-art检测模型都是使用ImageNet预训练的模型,比方说AlexNet训练时输入小于 256×256 ,原本的YOLO是在 224×224 上预训练,在后面训练时候提升到 448×448 ,这样模型需要去适应新的分辨率。
YOLO2是直接使用 448×448 的输入,在ImageNet上跑了10个epochs.让模型时间去适应更高分辨率的输入。这使得模型提高了4%的mAP.
Convolutional With Anchor Boxes
Anchor Boxes在Faster R-CNN里面已经介绍了,Faster R-CNN里anchor。
我们简单对比一下这个网络的特性:
| 对比项 | YOLO | Faster RCNN | YOLO2 |
|---|---|---|---|
| 结构上 | 预测bbox值是使用FC层来整的,gird cell负责预测种类,同一个grid cell下bbox没得选。 | 在feature map的基础上,使用不同形状的anchor boxes,然后计算出Proposal。 | 去掉YOLO的FC层,同时去掉YOLO的最后一个pool层,增加feature map的分辨率,修改网络的输入,保证feature map有一个中心点,这样可提高效率。并且是以每个anchor box来预测物体种类的 |
| 预测框 | 将图片分成 7×7 个grid cell,每个grid cell预测2个bbox,一共也就98个。对于物体数量多且密集的图片很无力啊 | 在 M×N feature map上每个位置使用9种anchor boxes,一共得到 9MN 个高级的特征 | 将网络的输入调整到 416×416 ,保证为多次卷积后,下采样factor为32,得到 13×13 的feature map。在这上面使用9种anchor boxes,得到 13×13×9=1521 个,这比YOLO大多了。 |
| 指标 | 69.5mAP recall:81% | 我速度慢,不凑热闹了 | 69.2mAP recall:88% 精度下降一点点,召回率上了7%,还是很有效果的 |
Dimension Clusters
在Faster R-CNN里我们介绍过,9种不同的anchor boxes是三种面积和三种不同的长宽比组合而成的,为什么要选这样的anchor?
这是人工选择出来的,如果我们能用一个先验条件,找出大部分bbox的形状,设置anchor也为如此,那么模型学习起来会容易很多。
所以在YOLO2中,使用了K-means聚类对数据集的ground truth聚类。一般的聚类是使用欧式距离,这会导致ground truth大的比ground truth小的更受误差的影响,而且我们在实际的评价中是使用IoU的,很自然的想到用IoU来做聚类尺度。实际的度量尺度:
对数据集的聚类结果如下:
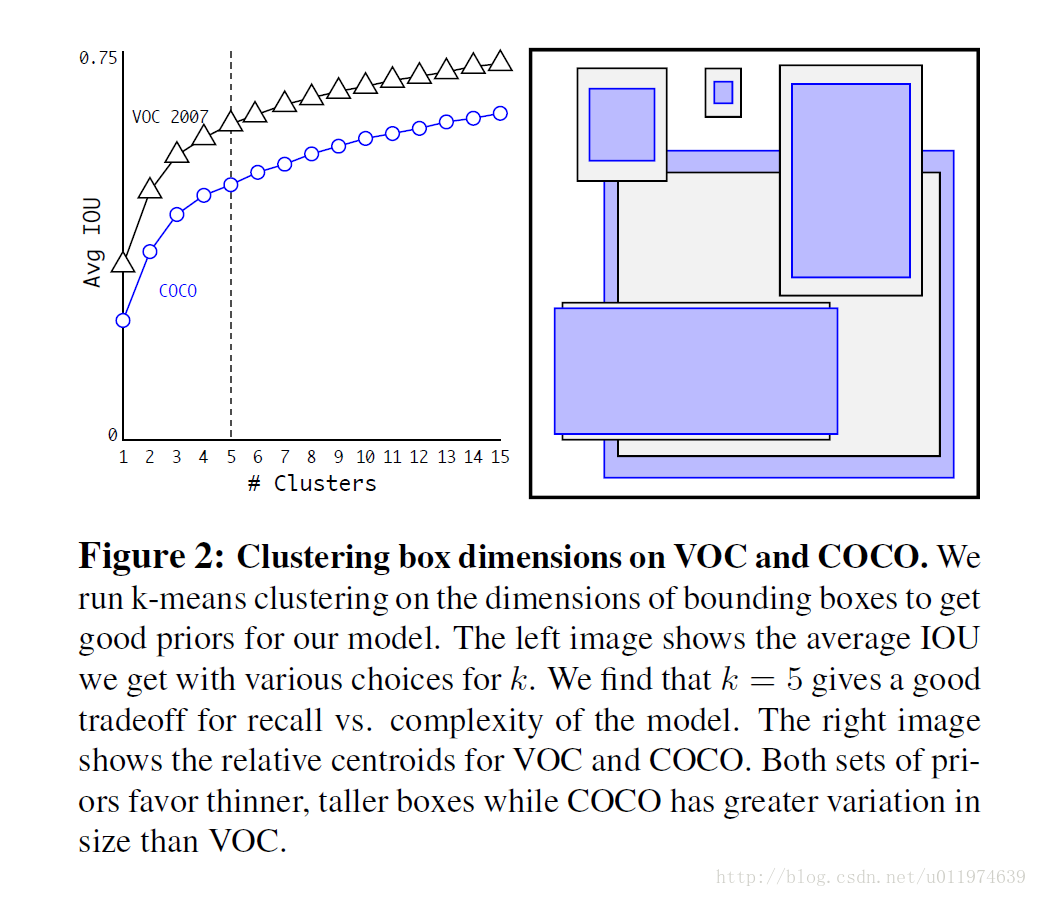
左图是聚类数目与Avg IoU的关系,论文选择是
k=5
,在模型复杂度与召回率之间取一个折中值。右图是
k=5
下的anchor boxes的形状。
同时,论文简单的比较了一下不同方法选出来的anchor的Avg IoU对比:
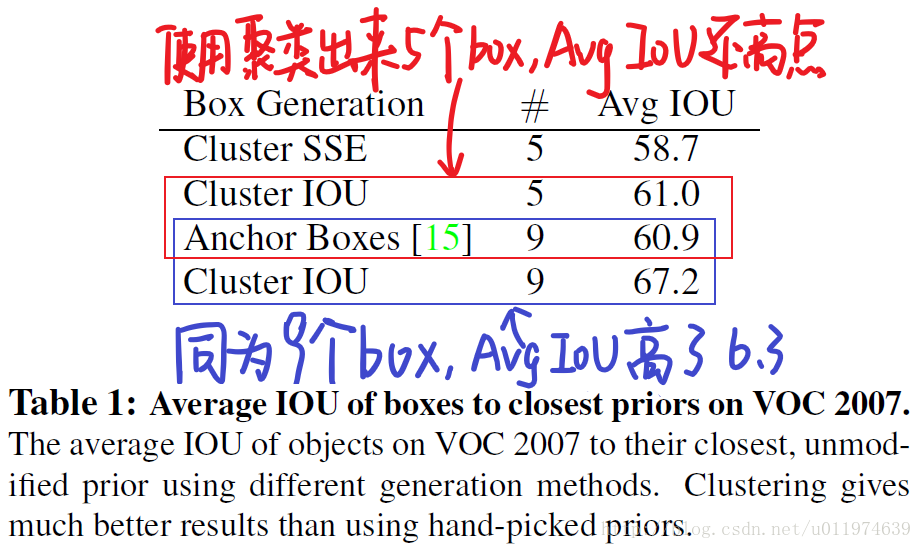
无论是 k=5 ,还是 k=9 ,使用聚类选出来的anchor在Avg IoU指标上都要要比手动的好。使用聚类来算anchor好处还是很明显的。
Direct location prediction
在YOLO上使用anchor boxes会遇到一个问题:模型不稳定。尤其是在早期迭代中。论文认为模型不稳定的原因来自于预测bbox的 (x,y) 。如下:
在Faster R-CNN的inference时,偏移因子
tx,ty
是没有限制的,模型预测的是offset,我们想让每个模型预测它附近的一个部分,在不加限制的情况下,收敛会比较慢。故论文对采用了和YOLO一样的方法,直接预测中心点,并使用Sigmoid函数将偏移量限制在0-1(这里的尺度是针对grid cell)。计算公式如下:
bx,by,bw,bh 是预测的bbox的中心点坐标和宽高,中心点坐标的尺度是相对于grid cell。如下图:
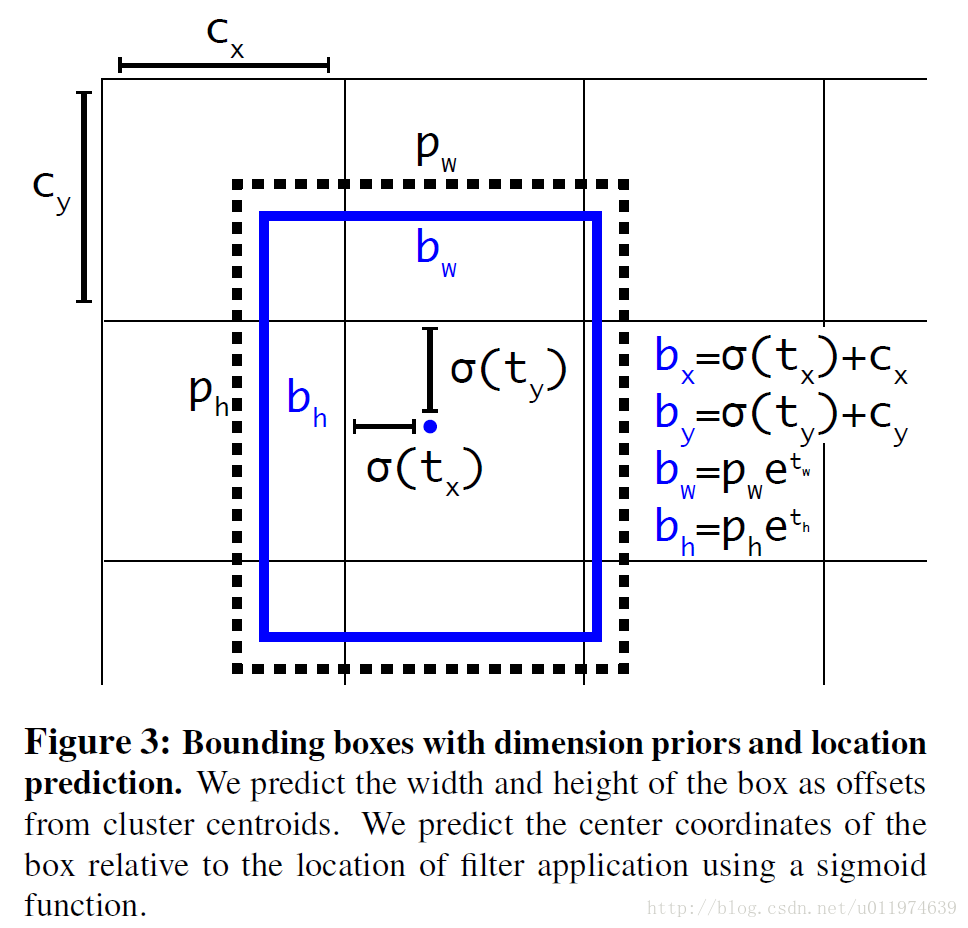
经过Dimension Clusters 和Direct location prediction操作,在原有的anchor boxes版本上又提升了5%的mAP。
Fine-Grained Features
网络最后的feature map尺寸为 13×13 ,对于检测大尺寸的目标是够的了。如果是要检测小尺寸细粒度的东西,感觉上有点勉强了。那该怎么办?
- 论文琢磨着Faster R-CNN和SSD的想法,在不同层次的特征图上获取不同分辨率的Proposal。
- 在ResNet上,是通过一个identity mapping,直接把上一层传到下一层。
论文整出一个passthrough layer,就是把上面层的(前面
26×26
)高分辨率的feature map直接连到
13×13
的feature map上。论文中把
26×26×512
转为
13×13×2048
,这样就能接到一起了。这么整让整体性能提升1%。
Multi-Scale Training
和GoogleNet训练时一样,为了提高模型的robust,使用多尺度的输入训练。因为网络的卷积层降采样因子是32,故输入尺寸选择32的倍数 {320,352,...,608} 。论文给出了实验数据:
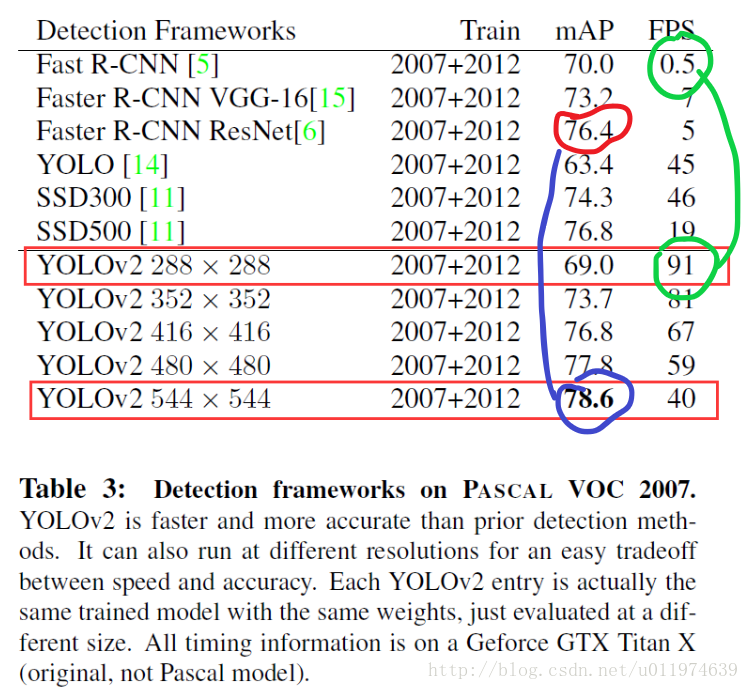
当网络在小尺度输入时,速度能达到90FPS,mAP也能达到Faster R-CNN的水平。使用大尺寸输入时,速度降到了40FPS,mAP上升到了78.6%.达到了state-of-the-art的水准。
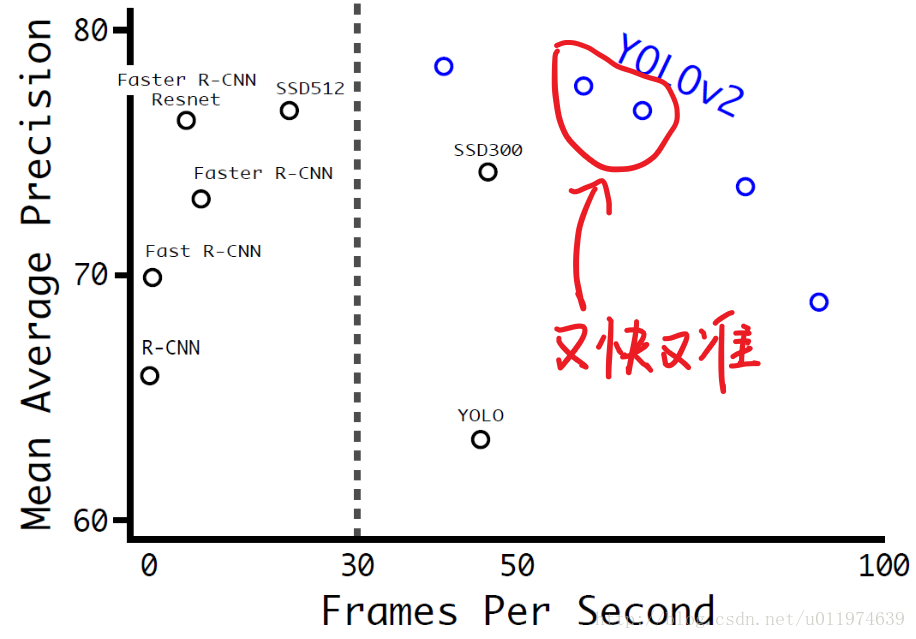
各个模型之间性能的对比图。
Faster
DarkNet-19
大多数detection的框架是建立在VGG-16上的,VGG-16在ImageNet上能达到90%的top-5,但是单张图片需要30.69 billion 浮点运算,YOLO2是依赖于DarkNet-19的结构,这个模型在ImageNet上能达到91%的top-5,并且单张图片只需要5.58 billion 浮点运算。DarkNet的结构图如下:
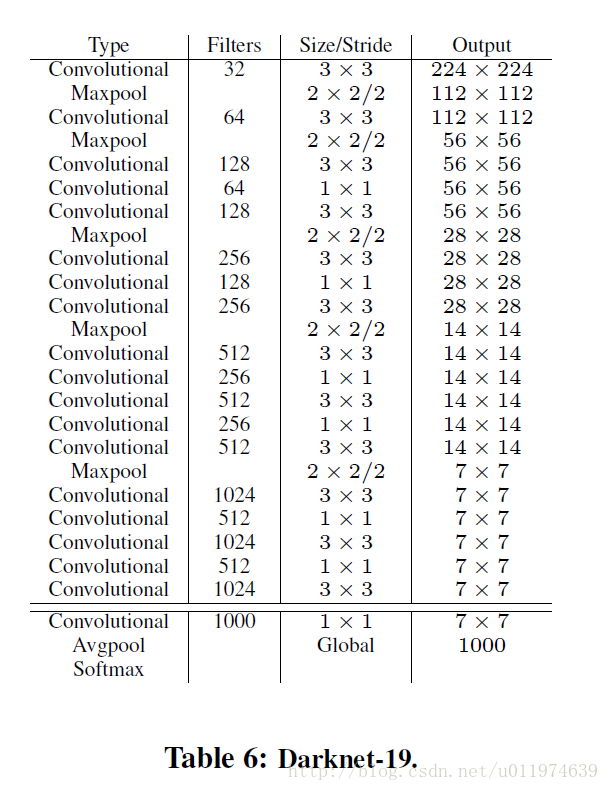
可以看到DarkNet也是大量使用了 3×3 和 1×1 的小卷积核,YOLO2在DarkNet的基础上添加了Batch Norm保证模型稳定,加速了模型收敛。
Training for classification
论文以Darknet-19为模型在ImageNet上用SGD跑了160epochs。
| 参数 | 数值 |
|---|---|
| learning rate | 0.1 |
| polynomial rate decay | 4 |
| weight decay | 0.00005 |
| momentum | 0.9 |
| data augmentation数据增强 | random crops, rotations等tricks |
跑完了160 epochs后,把输入尺寸从 224×224 上调为 448×448 ,这时候lr调到0.001,再跑了10 epochs,这时候DarkNet达到了top-1准确率76.5%,top-5准确率93.3%。
Training for dectection
在上面训练好的DarkNet-19的基础上,把分类网络改成detect网络,去掉原先网络的最后一个卷积层,取而代之的是使用3个 3×3x1024 的卷积层,并且每个新增的卷积层后面接 1×1 的卷积层,数量是我们要detection的数量。
定义新的detectin模型,该训练了:
| 参数 | 数值 |
|---|---|
| 训练次数 | 160 epochs |
| learning rate | 起始0.001,在60和90 epochs时衰减10倍 |
| weight decay | 0.0005 |
| momentum | 0.9 |
| data augmentation | random crops,color shifting,etc |
Stronger
论文提出了一种联合训练的机制:使用detection数据集训练模型detection相关parts,使用classification数据集训练模型classification相关parts。
这样训练会有一些问题:detection datasets的标签更为“上层”,例如狗,船啊啥的。而对应的classification datasets的标签就“下层”了很多,比如狗就有很多种,例如“Norfolk terrier”, “Yorkshire terrier”, and “Bedlington terrier”等等。
而我们一般在模型中分类使用的是softmax,softmax计算所有种类的最终的概率分布。softmax会假设所有种类之间是互斥的,但是,实际过程中,“上层”和“下层”之间是有对应的关系的。(例如中华田园犬,博美都属于狗),照着这样的思路,论文整出了一个层次性的标签结构。
Hierarchical classification
ImageNet的标签的来源是WordNet(一个语言数据库)。WordNet是由directed struct组成,但是directed struct较为复杂,这里采用另一个方式表示WordTree。
WordTree是一种多层级的Tree结构,数据来源于WordNet。在ImageNet中一个类别的标签在WordNet中到根节点的路径,如果存在多条则选择最短的一条。遍历将所有的类别标签都提取,最终得到WordTree,使用链式法则计算任意节点的概率值。
创建层次树的步骤是:
- 遍历ImageNet的所有视觉名词
- 对每一个名词,在WordNet上找到从它所在位置到根节点(“physical object”)的路径。 许多同义词集只有一条路径。所以先把这些路径加入层次树结构。
- 然后迭代检查剩下的名词,得到路径,逐个加入到层次树。路径选择办法是:如果一个名词有两条路径到根节点,其中一条需要添加3个边到层次树,另一条仅需添加一条边,那么就选择添加边数少的那条路径。
最终结果是一颗 WordTree (视觉名词组成的层次结构模型)。用WordTree执行分类时,预测每个节点的条件概率。例如: 在“terrier”节点会预测:
分类时假设图片包含物体:Pr(physical object) = 1.
为了验证这种方法作者在WordTree(用1000类别的ImageNet创建)上训练了Darknet-19模型。为了创建WordTree1k作者添加了很多中间节点,把标签由1000扩展到1369。
训练过程中ground truth标签要顺着向根节点的路径传播。例如:如果一张图片被标记为“Norfolk terrier”它也被标记为“dog” 和“mammal”等。为了计算条件概率,模型预测了一个包含1369个元素的向量,并基于所有“同义词集”计算softmax,其中“同义词集”是同一概念的下位词。
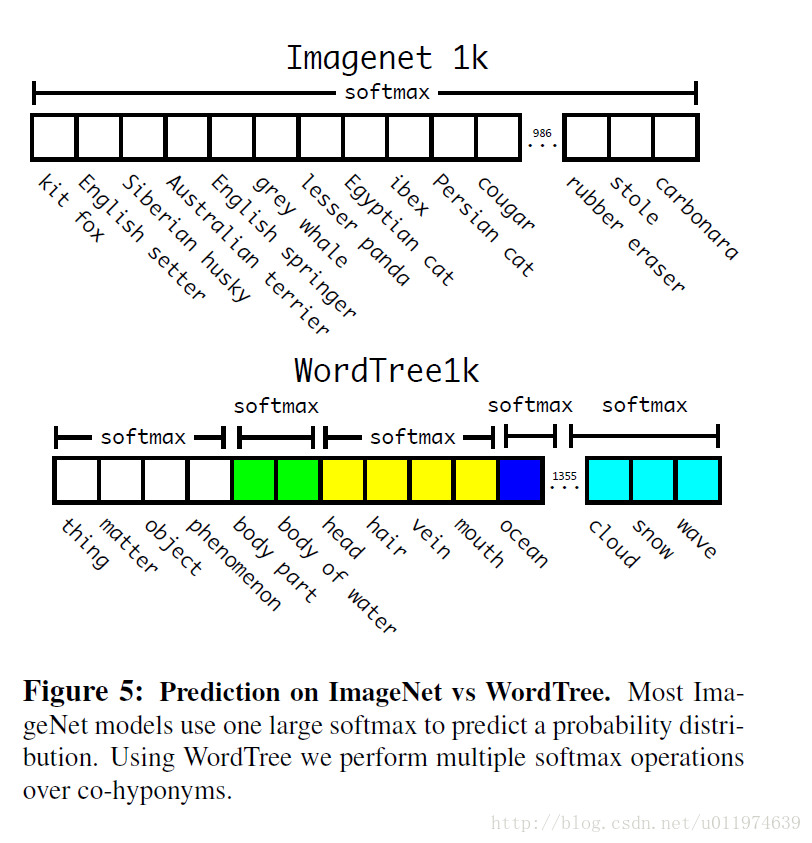
使用相同的训练参数,层次式Darknet-19获得71.9%的top-1精度和90.4%top-5精度。尽管添加了369个额外概念,且让网络去预测树形结构,精度只有略微降低。按照这种方式执行分类有一些好处,当遇到新的或未知物体类别 这种方法的好处是在对未知或者新的物体进行分类时,性能降低的很优雅(gracefully)。例如:如果网络看到一张狗的图片,但是不确定狗的类别,网络预测为狗的置信度依然很高,但是,狗的下位词(哈士奇/金毛)的置信度就比较低。
有了这种映射机制,WordTree就可以将不同的数据集结合起来,由于WordTree本身变化多端,所以可以将大多数的数据集结合起来。
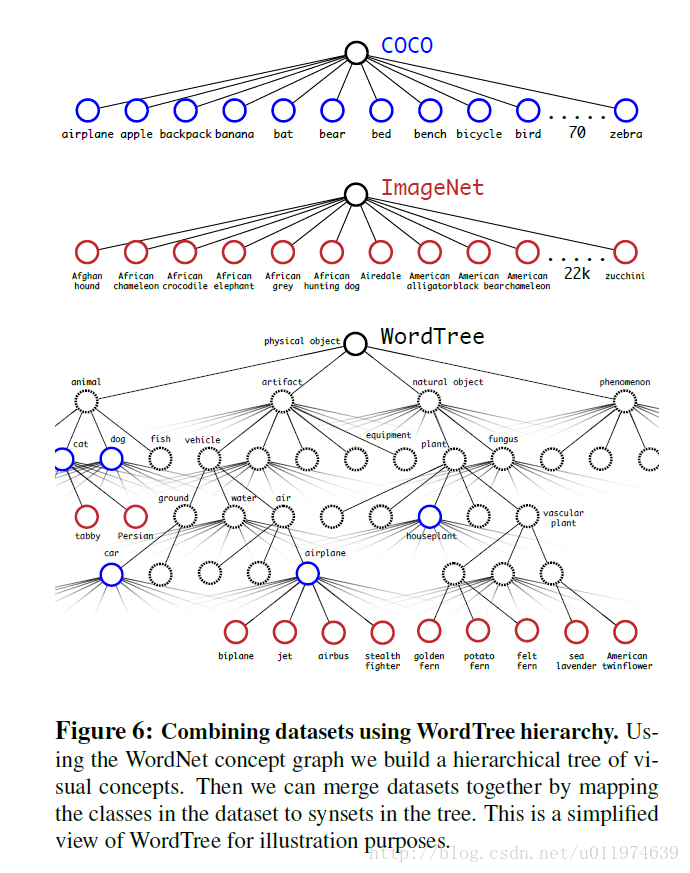
Joint classification and detection
| 细节 | 方法 |
|---|---|
| 样本 | 使用WordTree混合了COCO与ImageNet数据集后,混合数据集对应的WordTree包含9418类。由于ImageNet数据集跟COCO比太大了,产生了样本倾斜的问题,因此作者将COCO过采样,使得COCO与ImageNet的比例为1: 4。 |
| anchor box | YOLO9000的训练基于YOLO v2的架构。anchor box数量由5调整为3用以限制输出大小。 |
| 训练时遇到检测数据集样本 | 正常地反方向传播 |
| 训练时遇到分类数据集样本 | 在该类别对应的所有bounding box中找到一个置信度最高的(作为预测坐标),同样只反向传播该类及其路径以上对应节点的类别损失。反向传播objectness损失基于如下假设:预测box与ground truth box的重叠度至少0.3 IOU。 |
采用这种联合训练,YOLO9000从COCO检测数据集中学习如何在图片中寻找物体,从ImageNet数据集中学习更广泛的物体分类。
总结
YOLO2在YOLO的基础上提出了许多改进,比如Convolutional With Anchor Boxes, Dimension Clusters, Direct location prediction等等。YOLOv2/YOLO9000是现目标检测领域的state-of-the-art。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









