










Deep TEN: Texture Encoding Network
原文地址:Deep TEN
备注:这篇文章中提到的Encoding Layer 是语义分割–(EncNet)Context Encoding for Semantic Segmentation的前部分工作,面向是纹理识别任务。
收录:CVPR2017(IEEE Conference on Computer Vision and Pattern Recognition)
代码:
论文提出了一个新的深度学习模型,推广了传统的字典学习(dictionary learning)和残差编码(Residual Encoders)(例如 VLAD 和 Fisher Vector)。提出的编码层(Encoding Layer)可结合现有的深度学习框架,实现了端对端的深度学习框架,在材料识别任务上取得了不错的效果。
核心思想
传统方法
对于输入图片,传统图像识别方案:
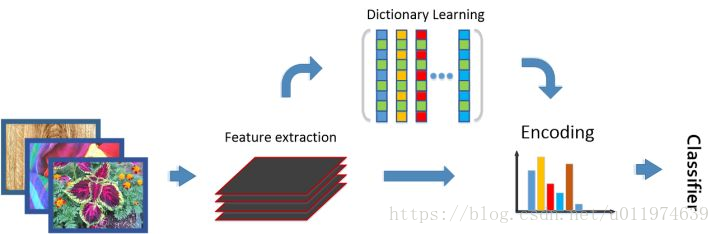
即分为如下步骤:
- 通常先提取图像特征(SIFT、filterbank responses等)
- 通过聚类等非监督方式得到一个字典(dictionary)
- 对图片特征编码(材料识别中通常使用无序编码器,比如BoWs,VLAD)
- 使用分类器进行分类
传统方法有以下两个特点:
- 输入图片可以为任意大小,使用编码器转化为一个固定长度的表达。
- 特征本身是通用的(domain-independent),字典和编码表达通常携带域信息(domain-specific information)。 即图像特征部分对多数任务都是有效的,这和深度学习预训练是一个道理,字典和编码是针对特定任务的,即深度学习里面的finetune。
相关工作
对比于传统方法(左图),已有的深度学习方法Cimpoiet. al. CVPR 2015 做了如下尝试(右图):
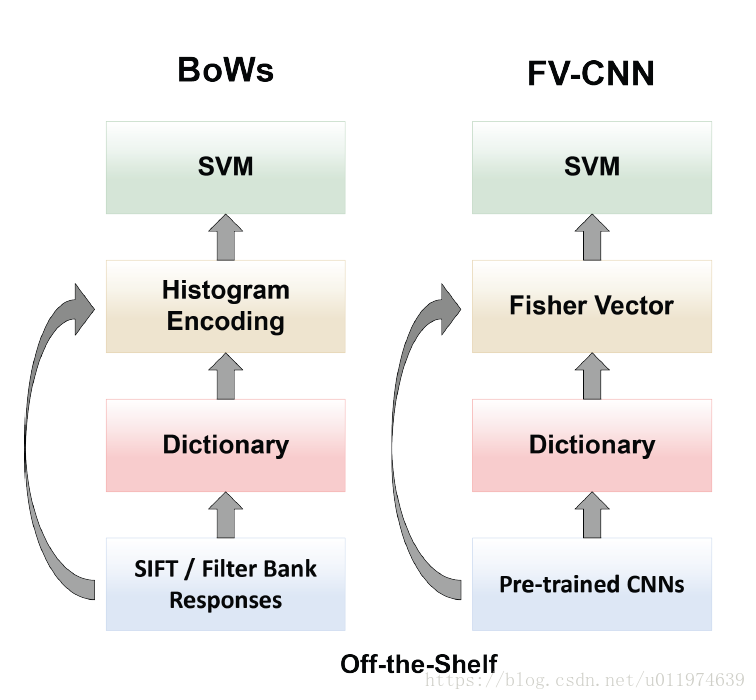
总结一下:
- 将特征提取换成了Pre-trained CNN,因为CNN的特征提取能力强
- 编码使用强大的Fisher Vector编码器
CNN强大的特征提取让整个框架得到了当时的state-of-the-art。但这种方法将整个系统分成多步再优化。 即整个系统形成不了端对端学习,特征提取,字典学习和编码器不能够从标识的数据(labeled data)中得到进一步优化。 这可以类比目标检测中的Fast R-CNN工作,先使用传统方法找出侯选区域。使用CNN来提取特征,使用RoI pooling将特征映射为固定长度表示,然后用分类器。最终版的Faster R-CNN通过RPN联立学习。*
论文方案
理想的方案如右图,即论文的思路:
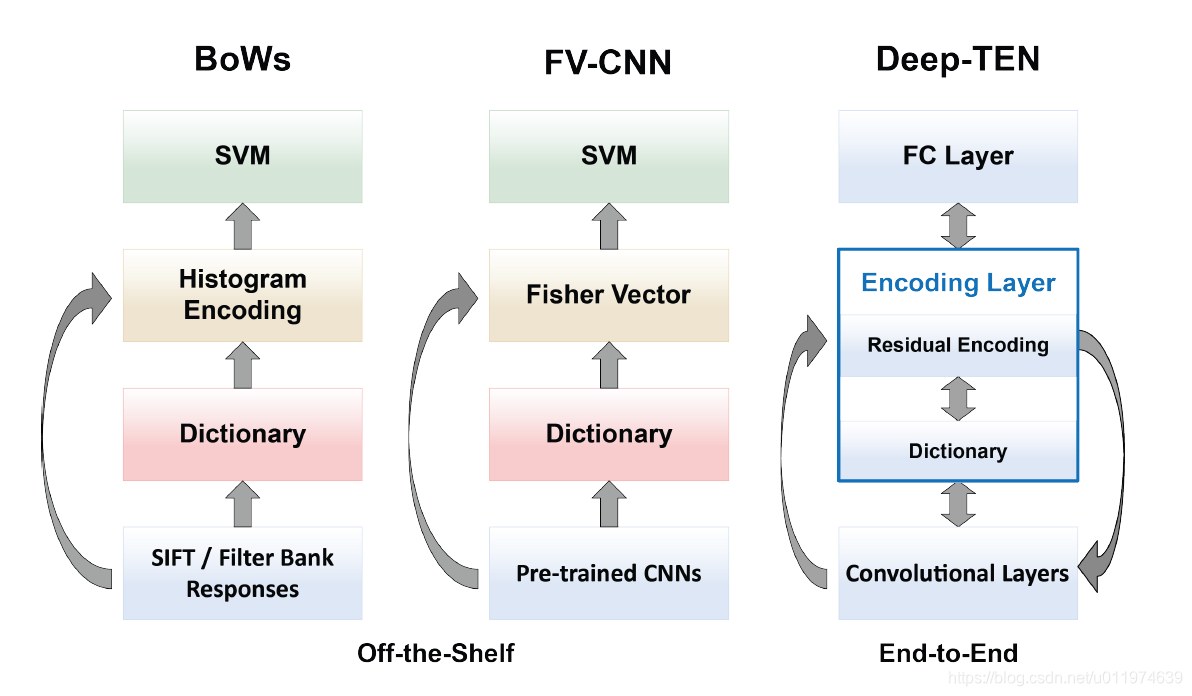
思路也很直接:设法将字典学习和编码整合到一个CNN网络层中,实现了端对端的学习优化。
论文提出了一个数学模型(Residual Encoding Model),推广已有的编码器 (VLAD, Fisher Vector),使得整个系统是可微分的,让所有部分从loss 中学习。实现了全监督式的字典学习(supervised dictionary learning)。 同时模型具备传统方法的特性:如CNN网络可以接受任意大小的图片;字典学习和编码容易携带domain信息,这样学习到的深度特征就更容易应用于其他domain。
模型推广了VLAD和Fisher Vector,故除了应用的于材料/纹理识别,还可以应用到其他地方(今年的scene understanding的EncNet, image retrieval等等)。
论文介绍
Abstract
论文提出了一个新颖的编码层(Encoding Layer)集成可集成现有的CNN中,论文称为深度纹理编码网络(Texture Encoding Network,Deep-TEN),编码层将整个字典学习(dictionary learning)和编码集成到一个单独的模型,提供了一个端对端的学习框架,分类器的feature,dictionaries和encoding representation都可以同时从loss上学习。
其中编码层泛化成鲁棒残差编码器(例如VLAD和Fish Vectors)。实验证明新的模型在多个数据集达到了先进的表现。
Introduction
Motivation
CNN在多个计算机视觉任务上成为了标准方法。在纹理和材料识别和目标识别中有一些独特的挑战,需要捕获一些空间重复无序度量(apturing an orderless measure encompassing some spatial repetition)。
在传统的方法上,使用兴趣点检测方法提取手工特征(例如SIFT或filterbank responses)。字典通常是离线学习,再编码特征分布(例如BoW),后面再使用分类器(例如SVM)得到预测结果。
在最近的工作中,手工提取特征被预训练的CNN代替,BoWs被鲁棒残差编码器代替(例如VLAD和Fisher Vector),例如Cimpoi等人使用不同的编码器(VLAD,FV)组成不同的特征(SIFT,CNN),这取得了当时的先进的结果。
但是,这些方法是堆叠self-contained 组件(特征提取,字典学习,编码,分类器训练),如下图左边和中间:
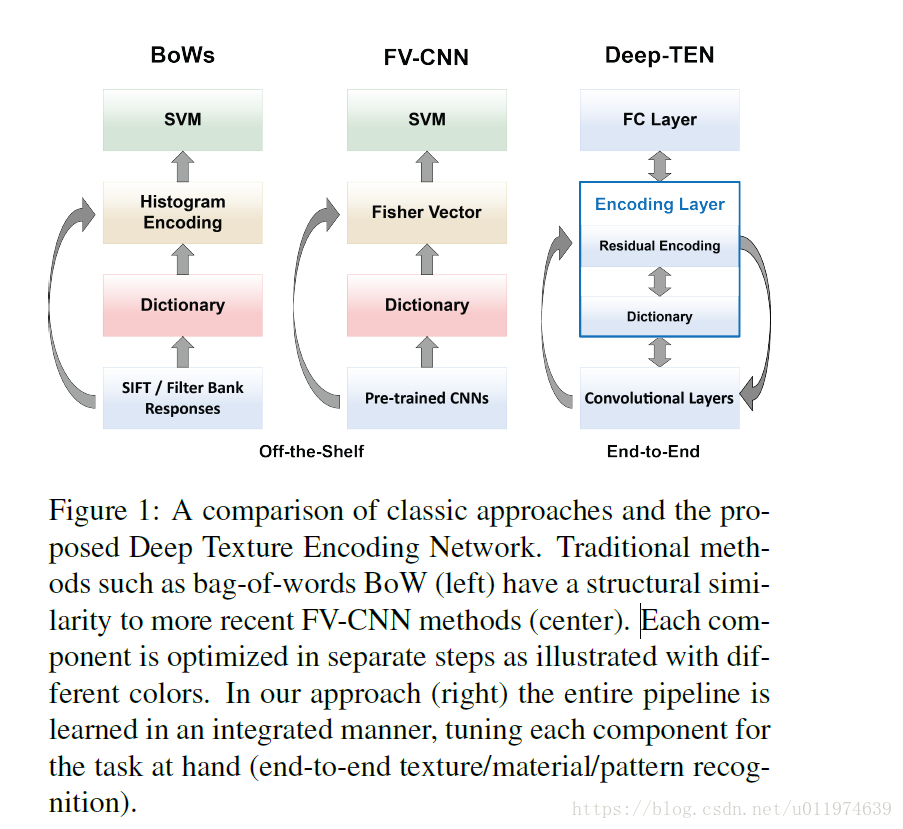
这些算法的缺点在于特征提取和编码一旦构建完成就是固定的,这样特征学习(CNN和字典)无法从标签数据中获益。
如何实现端对端学习?
CNN的卷积操作是以滑窗方式操作,充当局部特征提取器。输出的特征图保存了输入图片的相对的空间排列。再将得到的全局有序的特征级联送到FC层做分类, 这样的框架在图像分类,目标识别等获得巨大成功。但是这不适用于纹理识别,因为纹理识别需要描述特征分布的空间不变表示而不是级联。
因此,一个无序的特征池化层对于端对端训练是很有用的,而问题在于loss的梯度传递,论文在附录A给出了新的BP推导,实现了无序表示的编码集成到深度学习框架中。
Contribution
论文的第一个贡献
引入了一个新的可学习残差编码层(Encoding Layer),能够将整个字典学习和残差编码集成到单一的CNN模型中,编码层具有三个主要属性:
-
编码层推广鲁棒残差编码器,如VLAD和Fisher Vector,这种表示是无序的,描述了特征空间,适用于纹理和材质识别。
-
编码层在卷积层顶端充当池化层,接收不同尺寸大小并提供固定长度的表示输出。因为可接收不同尺寸的输出,模型更为灵活并且实现证明多尺度输入能够提升模型性能。
-
编码层学习固定字典并编码表示,这可能会携带特定域的信息,因此适合迁移预训练特征。在论文中,CNN是从对象分类迁移到纹理识别,因为网络作为回归过程实现端对端训练,因此卷积特征与顶端的编码层一起更容易迁移。
论文的第二个贡献
给出了一个端对端的框架Texture Encoding Network - Deep TEN。其中特征提取、字典学习和编码集成于单个网络中, 每个组件受益于BP中的梯度流动,都可以做学习调整。
模型在多个数据集上获得了先进的结果。论文进一步探索了通过对两个数据集联合训练来传输和编码层一起学习的卷积特征。
Learnable Residual Encoding Layer
对于传统方法不太了解,这里只是贴一个大概翻译~
Residual Encoding Model:
给定一组
N
N
N个视觉描述符
X
=
{
x
1
,
.
.
,
x
N
}
X=\{x_1,..,x_N\}
X={x1,..,xN},和一组学习codebook
C
=
{
c
1
,
.
.
,
c
K
}
C=\{c_1,..,c_K\}
C={c1,..,cK}包含了
K
K
K个
D
D
D维的codewords. 为每个描述符
x
i
x_i
xi,针对每个codeword
c
k
c_k
ck分配权重
α
i
k
\alpha_{ik}
αik,对应的残差向量记为
r
i
k
=
x
i
−
c
k
r_{ik}=x_i-c_k
rik=xi−ck,其中
i
=
1
,
.
.
,
N
i=1,..,N
i=1,..,N和
k
=
1
,
.
.
K
k=1,..K
k=1,..K. 给定分配和残差向量,残差编码模块对每个单独的codeword
c
k
c_k
ck做聚合操作:
e
k
=
∑
i
=
1
N
e
i
k
=
∑
i
=
1
N
α
i
k
r
i
k
e_k=\sum_{i=1}^{N}e_{ik}=\sum_{i=1}^{N}\alpha_{ik}r_{ik}
ek=i=1∑Neik=i=1∑Nαikrik
结果编码输出是一个固定长度表示 E = { e 1 , . . , e K } E=\{e_1,..,e_K\} E={e1,..,eK}(独立于输入描述符 N N N的)。
Encoding Layer:
传统的识别方法分成特征提取,字典学习,特征池化(编码),分类器学习。 论文的方案将字典学习和残差编码结合到单个CNN模型中,称之为Encoding Layer 。 编码层以全监督方式学习同时学习编码参数和固有字典。固有字典通过分配权重传递的梯度从描述符的分布中学习。在训练过程中,提取的卷积特征也可以从编码表示中受益。
对于描述符的权重原本使用的时 Hard-assignment,论文改进使用的Soft-weight应对不可分问题,受GMM的启发,最终的权重为:
α
i
k
=
exp
(
−
s
k
∣
∣
r
i
k
∣
∣
2
)
∑
j
=
1
K
exp
(
−
s
j
∣
∣
r
i
j
∣
∣
2
)
\alpha_{ik}=\frac{\exp(-s_k||r_{ik}||^2)}{\sum_{j=1}^{K}\exp(-s_j||r_{ij}||^2)}
αik=∑j=1Kexp(−sj∣∣rij∣∣2)exp(−sk∣∣rik∣∣2)
这对描述符提供了一个更为精确的建模,编码层通过分配的权重聚合残差向量,最终再用 L 2 − n o r m L2-norm L2−norm做标准化。
End-to-end Learning:
编码层是一个有向无环图,如下所示:
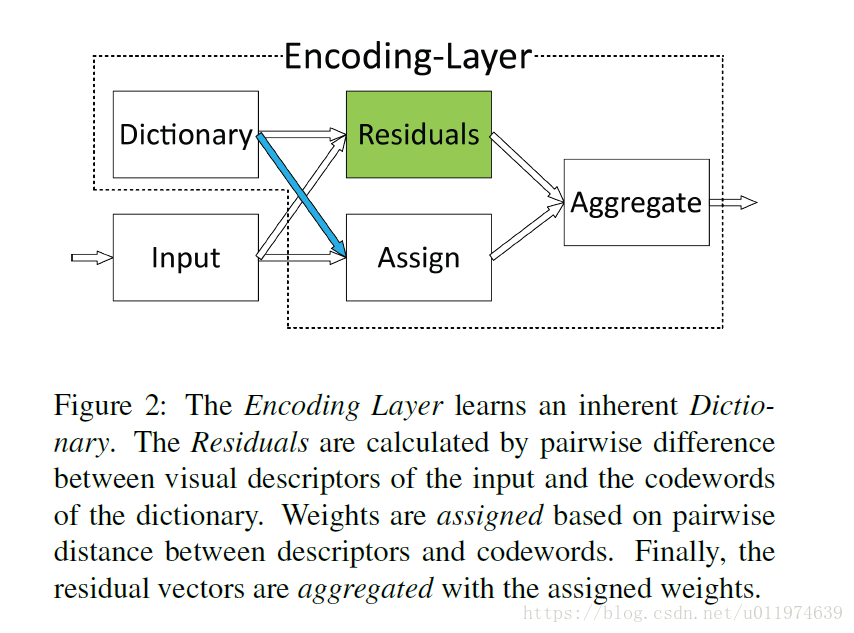
所有的参数都是可微分的。
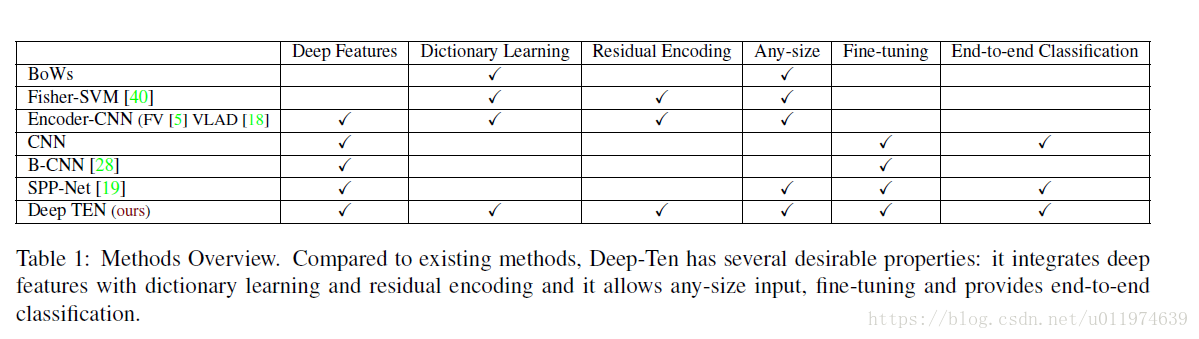
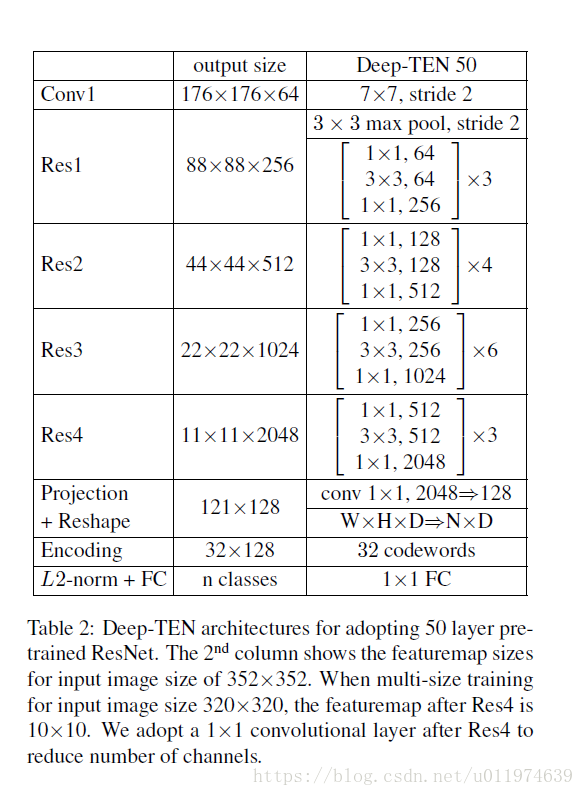
Relation to Other Methods
对比图如下:
Experimental Results
纹理识别任务上:
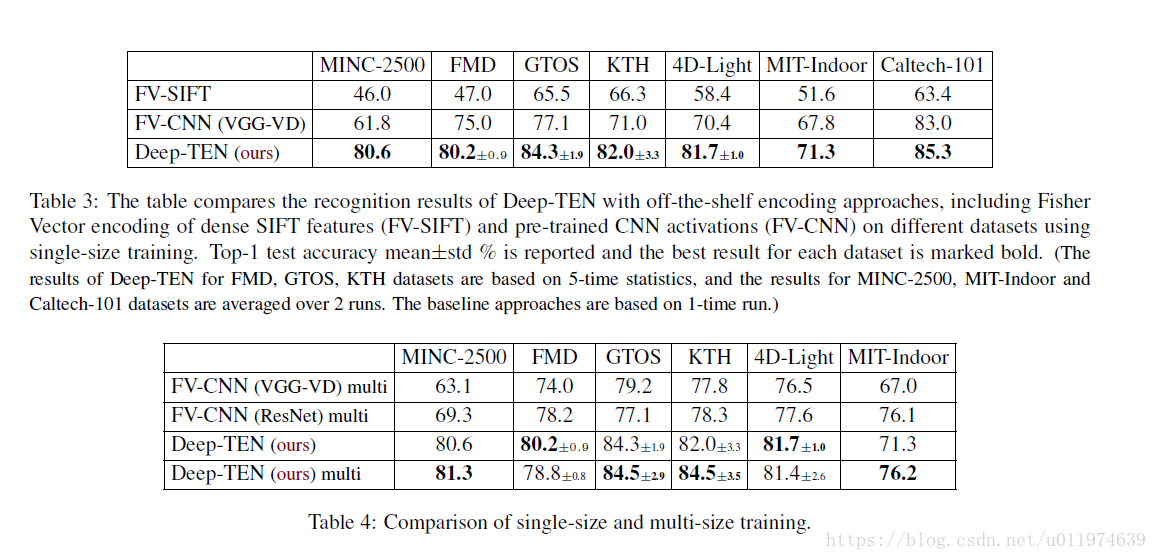
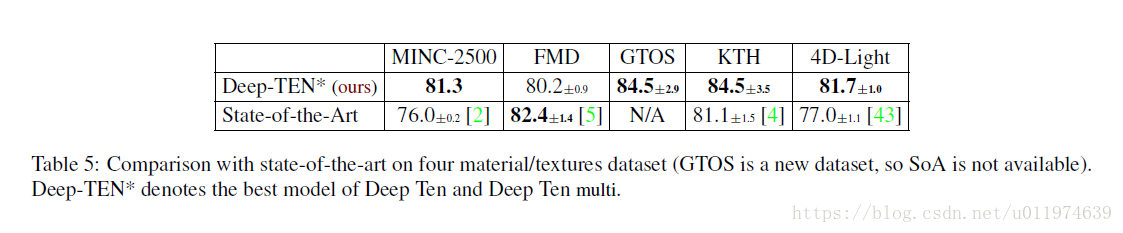
在分类任务上测试:
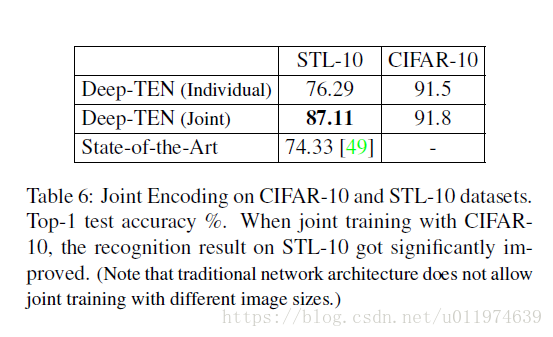
Conclusion
论文的主要贡献在于将传统的编码部分和现CNN架构集成到一起,弥补了传统计算机视觉方法和深度学习方法之间的差距。具体来说,提出了个数学模型 (Residual Encoding Model),推广了已有的编码器 (VLAD, Fisher Vector),并且使得整个系统是可微分的,每个部分都可从loss function中学习。 论文提出了一个针对纹理识别任务的框架Deep TEN,在多个纹理数据集上表现优异。
此外,新的模型有很多传统方法的特性:如CNN网络可以接受任意大小的图片,字典学习和表达容易携带Domain信息,这样学习到的深度特征就更加容易应用于其他domain。














 1553
1553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









