







一、综述
恶意网页链接的检测方案有很多
例如http://fsecurify.com/using-machine-learning-detect-malicious-urls/
该文使用了机器学习逻辑回归算法
但是该算法存在一些问题,一个是用TFIDF方法来获取词频,该方法的缺陷就是只能获取单词在整段文字的词频信息,
没办法获取上下文语境的信息
本文从自然语言的角度解析URL链接,恶意链接与文本恰有一些相似之处,所以尝试了自然语言处理的
方法来检测网页
本文将会简单介绍一些算法
二、算法介绍
1)典型的利用CNN进行文本分类的思路
卷积神经网络用于NLP的检测已经有很多实践以及论文支持,
比如http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/
利用CNN横向连接实现文本情感分析,本博文也是基于该原理,实现恶意网页检测。
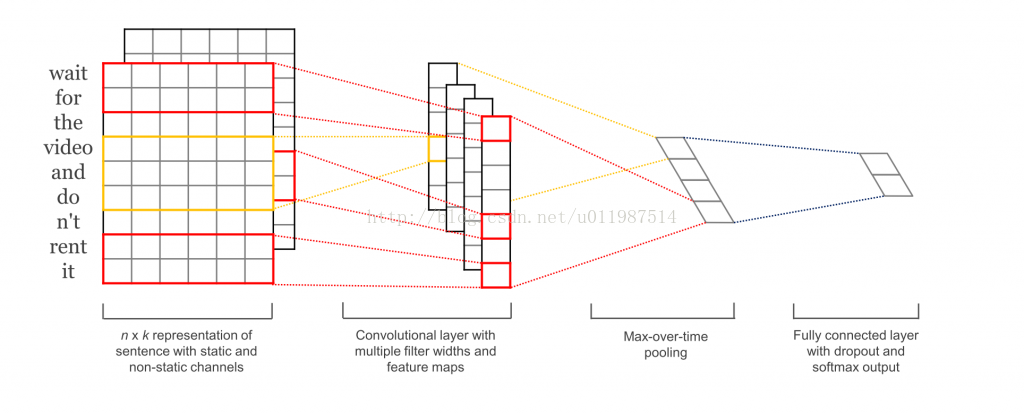
第一层进行一层低维词嵌入,把单词句子表示成向量形式,比较常用的词嵌入手段是word2vec,
第二层在词向量上进行卷积操作,可以多次使用不同尺寸的filter, 这样每次划过的单词数量就不同,
可以利用该特性自动抽取到上下文之间的关系特征。
第三层进行max-pooling。
2)重新思考URL检测问题
从文本分类上获得启发,能否借鉴它的这种想法,利用到URL上来?
博主把借鉴了这套网络,把它迁到url上来,对URL结构进行了分析。
这里以一条链接举例说明url的低维嵌入方法,请看
https://q.taobao.com/?spm=a21bo.50862.201859.7.spjPF3
一般url分成三部分 : 协议//主机
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 126
126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









