






一.推荐系统的总体架构
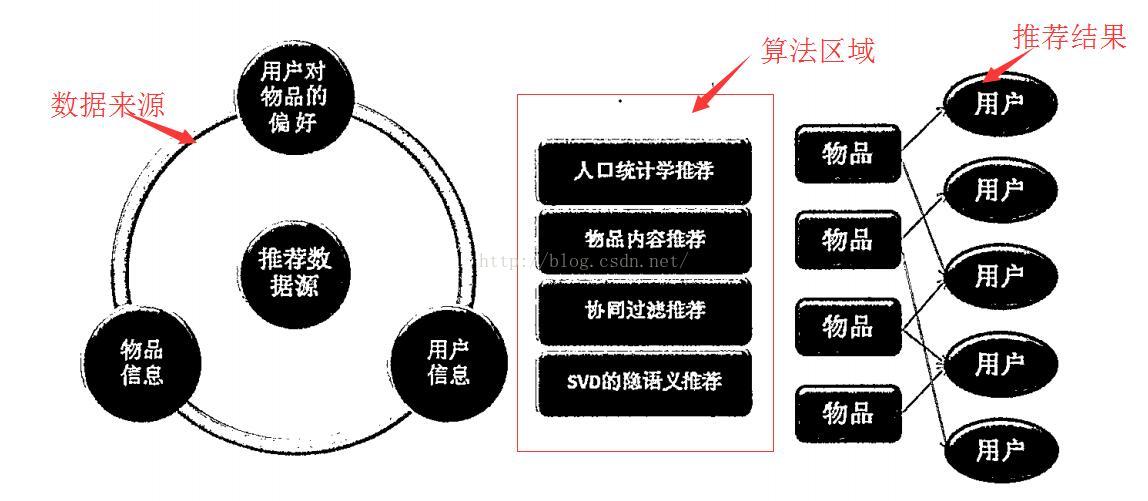
1.1选取用户偏好
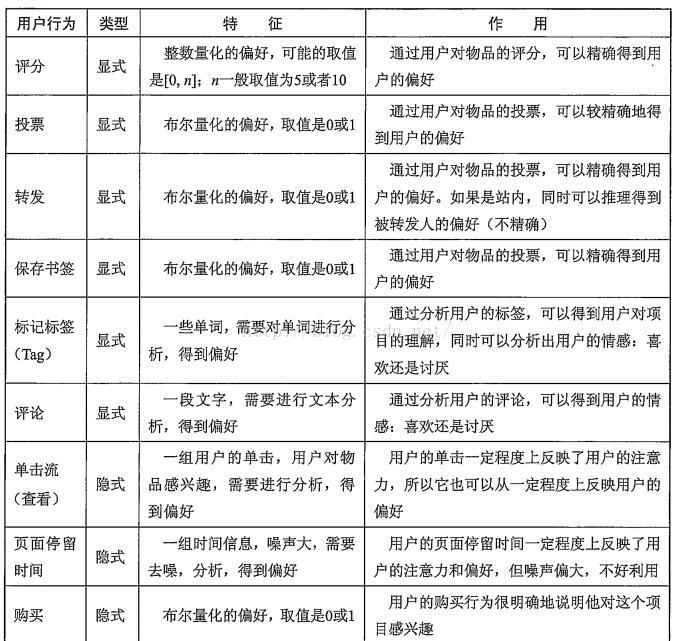
二.开源的推荐系统
2.1协同过滤及其算法
(1)数据预处理与UI矩阵:分组为"查看"和"购买",对数据进行一定的预处理,减噪和归一化
(2)推荐模型:User CF和Item CF:基于物品的协同过滤(Amason,Netfix,Hulu,YouTube等采用)这里使用kNN近邻算法。
(1)User CF
# -*- coding: utf-8 -*-
from numpy import *
import numpy as np
from Recommand_Lib import kNN
dataMat=mat([[0.238,0,0.1905,0.1905,0.1905,0.1905],[0,0.177,0,0.294,0.235,0.294],[0.2,0.16,0.12,0.12,0.2,0.2]])
testSet = [0.2174,0.2174,0.1304,0,0.2174,0.2174]
classLabel = np.array(['B','C','D'])
print kNN(testSet,dataMat,classLabel,3)
# -*- coding: utf-8 -*-
from numpy import *
import numpy as np
from Recommand_Lib import kNN
dataMat=mat([[0.417,0.0,0.25,0.333],[0.3,0.4,0.0,0.3],[0.0,0.0,0.625,0.375],[0.278,0.222,0.222,0.278],[0.263,0.211,0.263,0.263]])
testSet = [0.334,0.333,0.0,0.333]
classLabel = np.array(['B','C','D','E','F'])
print kNN(testSet,dataMat,classLabel,3)运行结果一样:
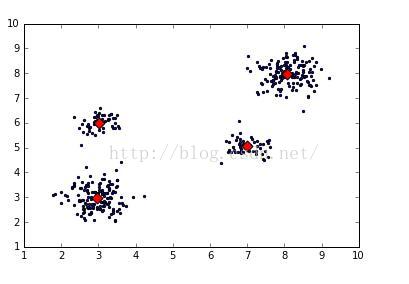
(3)KMeans (Scikit-Learn库中)聚类算法计算相似性:缩减计算量的方法,最优的选择就是对数据进行聚类。算法简单实现代码如下:
# -*- coding: utf-8 -*-
# Filename : 02kMeans1.py
import time
import numpy as np
from Recommand_Lib import *
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
k = 4
dataSet = file2matrix("testData/4k2_far.txt","\t")
dataMat = mat(dataSet[:,1:]) # 转换为矩阵形式
kmeans = KMeans(init='k-means++', n_clusters=4)
kmeans.fit(dataMat)
# 输出生成的ClustDist:对应的聚类中心(列1),到聚类中心的距离(列2),行与dataSet一一对应
drawScatter(plt,dataMat,size=20,color='b',mrkr='.')
# 绘制聚类中心
drawScatter(plt,kmeans.cluster_centers_,size=60,color='red',mrkr='D')
plt.show()
聚类的算法改进:二分KMeans 算法:
# -*- coding: utf-8 -*-
# Filename : 02kMeans1.py
from numpy import *
import numpy as np
from Recommand_Lib import *
import matplotlib.pyplot as plt
# 从文件构建的数据集
dataMat = file2matrix("testData/4k2_far.txt","\t")
dataSet = mat(dataMat[:,1:]) # 转换为矩阵形式
k = 4 # 分类数
m = shape(dataSet)[0]
# 初始化第一个聚类中心: 每一列的均值
centroid0 = mean(dataSet, axis=0).tolist()[0]
centList =[centroid0] # 把均值聚类中心加入中心表中
# 初始化聚类距离表,距离方差:
ClustDist = mat(zeros((m,2)))
for j in range(m):
ClustDist[j,1] = distEclud(centroid0,dataSet[j,:])**2
# 依次生成k个聚类中心
while (len(centList) < k):
lowestSSE = inf # 初始化最小误差平方和。核心参数,这个值越小就说明聚类的效果越好。
# 遍历cenList的每个向量
#----1. 使用ClustDist计算lowestSSE,以此确定:bestCentToSplit、bestNewCents、bestClustAss----#
for i in xrange(len(centList)):
ptsInCurrCluster = dataSet[nonzero(ClustDist[:,0].A==i)[0],:]
# 应用标准kMeans算法(k=2),将ptsInCurrCluster划分出两个聚类中心,以及对应的聚类距离表
centroidMat,splitClustAss = kMeans(ptsInCurrCluster, 2)
# 计算splitClustAss的距离平方和
sseSplit = sum(splitClustAss[:,1])
# 计算ClustDist[ClustDist第1列!=i的距离平方和
sseNotSplit = sum(ClustDist[nonzero(ClustDist[:,0].A!=i)[0],1])
if (sseSplit + sseNotSplit) < lowestSSE: # 算法公式: lowestSSE = sseSplit + sseNotSplit
bestCentToSplit = i # 确定聚类中心的最优分隔点
bestNewCents = centroidMat # 用新的聚类中心更新最优聚类中心
bestClustAss = splitClustAss.copy() # 深拷贝聚类距离表为最优聚类距离表
lowestSSE = sseSplit + sseNotSplit # 更新lowestSSE
# 回到外循环
#----2. 计算新的ClustDist----#
# 计算bestClustAss 分了两部分:
# 第一部分为bestClustAss[bIndx0,0]赋值为聚类中心的索引
bestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList)
# 第二部分 用最优分隔点的指定聚类中心索引
bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit
# 以上为计算bestClustAss
# 更新ClustDist对应最优分隔点下标的距离,使距离值等于最优聚类距离对应的值
#以上为计算ClustDist
#----3. 用最优分隔点来重构聚类中心----#
# 覆盖: bestNewCents[0,:].tolist()[0]附加到原有聚类中心的bestCentToSplit位置
# 增加: 聚类中心增加一个新的bestNewCents[1,:].tolist()[0]向量
centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0]
centList.append(bestNewCents[1,:].tolist()[0])
ClustDist[nonzero(ClustDist[:,0].A == bestCentToSplit)[0],:]= bestClustAss
# 以上为计算centList
color_cluster(ClustDist[:,0:1],dataSet,plt)
print "cenList:",mat(centList)
# print "ClustDist:", ClustDist
# 绘制聚类中心图形
drawScatter(plt,mat(centList),size=60,color='red',mrkr='D')
plt.show()
# -*- coding: utf-8 -*-
# Filename : 02kMeans1.py
from numpy import *
import numpy as np
from Recommand_Lib import *
import matplotlib.pyplot as plt
# 从文件构建的数据集
dataMat = file2matrix("testData/4k2_far.txt","\t")
dataSet = mat(dataMat[:,1:]) # 转换为矩阵形式
k = 4 # 分类数
m = shape(dataSet)[0]
# 初始化第一个聚类中心: 每一列的均值
centroid0 = mean(dataSet, axis=0).tolist()[0]
centList =[centroid0] # 把均值聚类中心加入中心表中
# 初始化聚类距离表,距离方差:
ClustDist = mat(zeros((m,2)))
for j in range(m):
ClustDist[j,1] = distEclud(centroid0,dataSet[j,:])**2
# 依次生成k个聚类中心
while (len(centList) < k):
lowestSSE = inf # 初始化最小误差平方和。核心参数,这个值越小就说明聚类的效果越好。
# 遍历cenList的每个向量
#----1. 使用ClustDist计算lowestSSE,以此确定:bestCentToSplit、bestNewCents、bestClustAss----#
for i in xrange(len(centList)):
ptsInCurrCluster = dataSet[nonzero(ClustDist[:,0].A==i)[0],:]
# 应用标准kMeans算法(k=2),将ptsInCurrCluster划分出两个聚类中心,以及对应的聚类距离表
centroidMat,splitClustAss = kMeans(ptsInCurrCluster, 2)
# 计算splitClustAss的距离平方和
sseSplit = sum(splitClustAss[:,1])
# 计算ClustDist[ClustDist第1列!=i的距离平方和
sseNotSplit = sum(ClustDist[nonzero(ClustDist[:,0].A!=i)[0],1])
if (sseSplit + sseNotSplit) < lowestSSE: # 算法公式: lowestSSE = sseSplit + sseNotSplit
bestCentToSplit = i # 确定聚类中心的最优分隔点
bestNewCents = centroidMat # 用新的聚类中心更新最优聚类中心
bestClustAss = splitClustAss.copy() # 深拷贝聚类距离表为最优聚类距离表
lowestSSE = sseSplit + sseNotSplit # 更新lowestSSE
# 回到外循环
#----2. 计算新的ClustDist----#
# 计算bestClustAss 分了两部分:
# 第一部分为bestClustAss[bIndx0,0]赋值为聚类中心的索引
bestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList)
# 第二部分 用最优分隔点的指定聚类中心索引
bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit
# 以上为计算bestClustAss
# 更新ClustDist对应最优分隔点下标的距离,使距离值等于最优聚类距离对应的值
#以上为计算ClustDist
#----3. 用最优分隔点来重构聚类中心----#
# 覆盖: bestNewCents[0,:].tolist()[0]附加到原有聚类中心的bestCentToSplit位置
# 增加: 聚类中心增加一个新的bestNewCents[1,:].tolist()[0]向量
centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0]
centList.append(bestNewCents[1,:].tolist()[0])
ClustDist[nonzero(ClustDist[:,0].A == bestCentToSplit)[0],:]= bestClustAss
# 以上为计算centList
color_cluster(ClustDist[:,0:1],dataSet,plt)
print "cenList:",mat(centList)
# print "ClustDist:", ClustDist
# 绘制聚类中心图形
drawScatter(plt,mat(centList),size=60,color='red',mrkr='D')
plt.show()
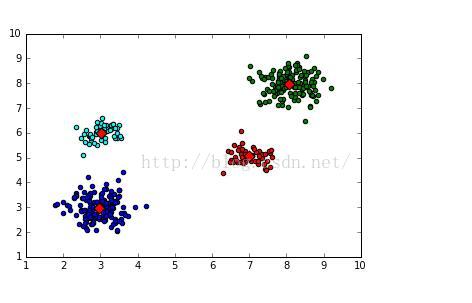
(4)SVD (隐语义模型:奇异值分解)计算相似性
# -*- coding: utf-8 -*-
# Filename : svdRec2.py
'''
Created on Mar 8, 2011
@author: Peter
'''
from numpy import *
from numpy import linalg as la
def loadExData():
return[[0, 0, 0, 2, 2],
[0, 0, 0, 3, 3],
[0, 0, 0, 1, 1],
[1, 1, 1, 0, 0],
[2, 2, 2, 0, 0],
[5, 5, 5, 0, 0],
[1, 1, 1, 0, 0]]
def loadReData():
return[[4, 4, 0, 2, 2],
[4, 0, 0, 3, 3],
[4, 0, 0, 1, 1],
[1, 1, 1, 0, 0],
[2, 2, 2, 0, 0],
[5, 5, 5, 0, 0],
[1, 1, 1, 0, 0]]
def loadExData2():
return[[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5],
[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
[3, 3, 4, 0, 0, 0, 0, 2, 2, 0, 0],
[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]]
# 欧氏距离:
# 二维空间的欧氏距离公式:sqrt((x1-x2)^2+(y1-y2)^2)
def ecludSim(inA,inB):
return 1.0/(1.0 + la.norm(inA - inB))
# 皮尔逊相似度:corrcoef相关系数:衡量X与Y线性相关程度,其绝对值越大,则表明X与Y相关度越高。
# E((X-EX)(Y-EY))/sqrt(D(X)D(Y))
def pearsSim(inA,inB):
if len(inA) < 3 : return 1.0
return 0.5+0.5*corrcoef(inA, inB, rowvar = 0)[0][1]
# 夹角余弦:计算空间内两点之间的夹角余弦
# 两个n维样本点a(x11,x12,…,x1n)和b(x21,x22,…,x2n)的夹角余弦
# cos(theta) = a*b/(|a|*|b|)
def cosSim(inA,inB):
num = float(inA.T*inB)
denom = la.norm(inA)*la.norm(inB)
return 0.5+0.5*(num/denom)
# 标准相似度计算方法下的用户估计值
def standEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1] # 列数
simTotal = 0.0; ratSimTotal = 0.0
for j in range(n):
userRating = dataMat[user,j] # 数据集第user行第j列的元素值
if userRating == 0: continue # 跳过未评估项目
# logical_and:矩阵逐个元素运行逻辑与,返回值为每个元素的True,False
# dataMat[:,item].A>0: 第item列中大于0的元素
# dataMat[:,j].A: 第j列中大于0的元素
# overLap: dataMat[:,item],dataMat[:,j]中同时都大于0的那个元素的行下标
overLap = nonzero(logical_and(dataMat[:,item].A>0,dataMat[:,j].A>0))[0]
# 计算相似度
if len(overLap) == 0: similarity = 0
else: similarity = simMeas(dataMat[overLap,item],dataMat[overLap,j]) # 计算overLap矩阵的相似度
# print "第%d列和第%d列的相似度是: %f" %(item, j, similarity)
# 累计总相似度
simTotal += similarity
# ratSimTotal = 相似度*元素值
ratSimTotal += similarity * userRating
if simTotal == 0: return 0 # 如果总相似度为0,返回0
# 返回相似度*元素值/总相似度
else:
# print "ratSimTotal:",ratSimTotal
# print "simTotal:",simTotal
return ratSimTotal/simTotal
#使用svd进行估计
def svdEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1]
simTotal = 0.0; ratSimTotal = 0.0
# svd相似性计算的核心
U,Sigma,VT = la.svd(dataMat) # 计算矩阵的奇异值分解
# Sig4 = mat(eye(4)*Sigma[:4]) # 取Svd特征值的前4个构成对角阵
# xformedItems = dataMat.T * U[:,:4] * Sig4.I # 创建变换后的项目矩阵create transformed items
V = VT.T # V是dataMat的相似矩阵
xformedItems = V[:,:4]
# print "xformedItems:",xformedItems
# 逐列遍历数据集
for j in range(n):
userRating = dataMat[user,j] # 未评级用户为0,因此不会计算。其他的均有值
# print "userRating:",userRating
# 跳过未评级的项目
if userRating == 0 or j==item: continue
# 使用指定的计算公式计算向量间的相似度
similarity = simMeas(xformedItems[item,:].T,xformedItems[j,:].T) # 相似度计算公式
# print "待评估%d列和第%d列的相似度是: %f" % (item, j, similarity)
simTotal += similarity # 计算累计总相似度
ratSimTotal += similarity * userRating # ratSim = 相似度*项目评估值
if simTotal == 0: return 0
else: return ratSimTotal/simTotal
# 产生推荐结果的主方法
# simMeas取值:cosSim, pearsSim, ecludSim
# estMethod取值:standEst,svdEst
# user 用户项目矩阵中进行评估的行下标
# N=3返回前3项
def recommend(dataMat, user, N=3, simMeas=cosSim, estMethod=svdEst):
unratedItems = nonzero(dataMat[user,:].A==0)[1] # 查找未评级的项目--即用户--项目矩阵中user行对应的零值
# print "unratedItems:",unratedItems
# unratedItems: 未评估的项目--项目矩阵中user行对应零值的列下标
if len(unratedItems) == 0: return "已经对所有项目评级"
# 初始化项目积分数据类型,是一个二维矩阵
# 元素1:item;元素2:评分值
itemScores = []
# 循环进行评估:将每个未评估项目于已评估比较,计算相似度
# 本例中未评估项目取值1,2
for item in unratedItems:
estimatedScore = estMethod(dataMat, user, simMeas, item) # 使用评估方法对数据评估,返回评估积分
itemScores.append((item, estimatedScore)) # 并在项目积分内加入项目和对应的评估积分
# 返回排好序的项目和积分,N=3返回前3项
return sorted(itemScores, key=lambda jj: jj[1], reverse=True)[:N]
# 输出矩阵
def printMat(inMat, thresh=0.8):
for i in range(32):
for k in range(32):
if float(inMat[i,k]) > thresh:
print 1,
else: print 0,
print ''
# 图片压缩
def imgCompress(numSV=3, thresh=0.8,flag=True):
myl = []
for line in open('0_5.txt').readlines():
newRow = []
for i in range(32):
newRow.append(int(line[i]))
myl.append(newRow)
myMat = mat(myl)
print "****original matrix******"
printMat(myMat, thresh)
U,Sigma,VT = la.svd(myMat)
print "U 行列数:",shape(U)[0],",",shape(U)[1]
print "Sigma:",Sigma
print "VT 行列数:",shape(VT)[0],",",shape(VT)[1]
if flag:
SigRecon = mat(zeros((numSV, numSV)))
for k in range(numSV):#construct diagonal matrix from vector
SigRecon[k,k] = Sigma[k]
reconMat = U[:,:numSV]*SigRecon*VT[:numSV,:]
print "****reconstructed matrix using %d singular values******" % numSV
printMat(reconMat, thresh)# -*- coding: utf-8 -*-
# Filename : testRecomm01.py
from numpy import *
import numpy as np
import operator
from svdRec import *
import matplotlib.pyplot as plt
eps = 1.0e-6
# 加载修正后数据
A = mat([[5, 5, 3, 0, 5, 5],[5, 0, 4, 0, 4, 4],[0, 3, 0, 5, 4, 5],[5, 4, 3, 3, 5, 5]])
# 手工分解求矩阵的svd
U = A*A.T
lamda,hU = linalg.eig(U) # hU:U特征向量
VT = A.T*A
eV,hVT = linalg.eig(VT) # hVT:VT特征向量
hV = hVT.T
# print "hU:",hU
# print "hV:",hV
sigma = sqrt(lamda) # 特征值
print "sigma:",sigma
print"svd:验证结果:"
Sigma = np.zeros([shape(A)[0], shape(A)[1]])
U,S,VT = linalg.svd(A)
# Sigma[:shape(A)[0], :shape(A)[0]] = np.diag(S)
# print U
print S
# print VT
# print U*Sigma*VT
运行结果如下:

本章主要介绍了KMeans无监督聚类算法及其python的实现,另外一个讲解了推荐系统最核心的算法-SVD算法,最后用Numpy的库函数实现了SVD算法.














 1436
1436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









