







昨天看 别人写的一段sql语句,就是下面放出来的这句,前面是可以看的明白,但是里面的这句:start with d.code= '"+orgClassify+"' connect by prior d.id = d.parent_id
,百度了一下总算知道了什么意思,原来这里面涉及到了oracle connect by的用法,我是新手,大家表见笑,说实话以前都没见过,更别说用了。
String sql = "select d.id \"id\",d.code \"code\",d.name \"text\",d.parent_id,d.sort from cendic.d_dictionary_item d where d.d_code='TB_DIC_JGFL' and d.active='1' "
+ "and d.code !='"+orgClassify+"' start with d.code= '"+orgClassify+"' connect by prior d.id = d.parent_id order by d.sort asc";select d.id id,d.code code,d.name text,d.parent_id,d.sort from cendic.d_dictionary_item d where d.d_code='TB_DIC_JGFL' and d.active='1'
and d.code !='1' start with d.code= '1' connect by prior d.id = d.parent_id order by d.sort asc;
给大家解释一下这个语句的整体意思:查询节点 d.code=1以下所有的子孙菜单
1) 首先,执行的是该select语句中的start with子句部分,具体地说,就是执行该select语句的服务器进程先从表cendic.d_dictionary_item中
找出所有 d.code字段的值为 1的数据行.它们两构成了上图中树的第一层,既查出一行:卫计委。
2)接着,执行的是该select语句中的connect by子句部分,具体地说,就是执行该select语句的服务器进程先从表cendic.d_dictionary_item剩下的数据行(即除去了已经被选中的那些数据行)中找出所有parent_id字段的值等于在之前已经找出的树的第一层中各个数据行的id字段的值的数据行。在上述例子中,上图中树的第一层里text字段为卫计委的数据行的id字段值为df754903-5081-4012-92aa-31ab2bf3be1f,所以服务器进程就从表cendic.d_dictionary_item剩下的数据行(即除去了已经被选中的第一层的那一行数据行)中找出所有rparent_ id字段的值等于df754903-5081-4012-92aa-31ab2bf3be1f的数据行,即text字段分别为:直属单位和区(市)县的两条数据行;于是,text字段分别为:直属单位和区(市)县两条数据行,构成了上图中树的第二层,依次类推找以直属单位和区(市)县两条记录的id值为parent_id的数据行共有
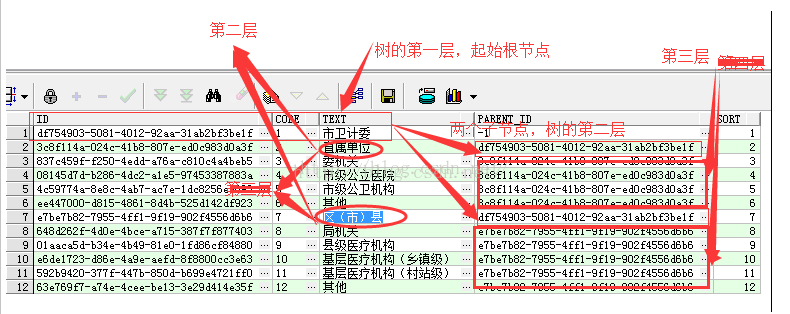
3)再接着,服务器进程还是要重复执行该select语句中的connect by子句部分,直到表中不存在符合prior id = root_id这个条件的数据行为止。
4)执行where子句
5)执行order by子句
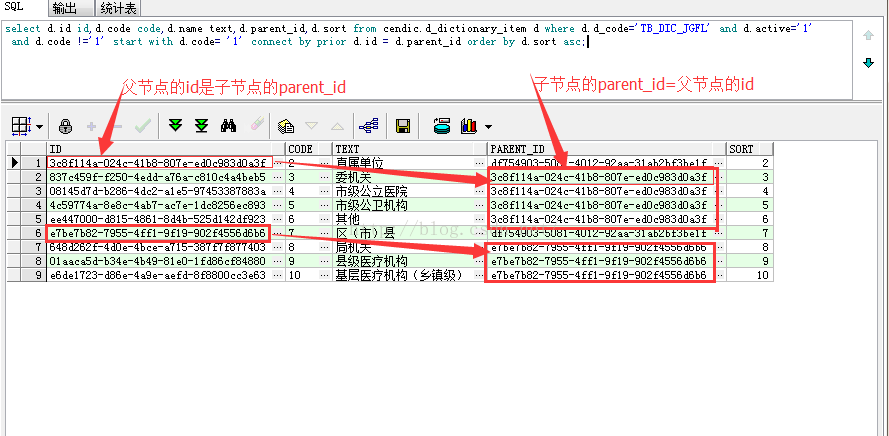
查询结果如下:
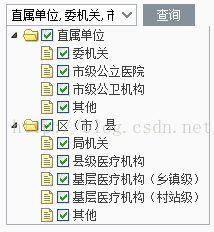
这些数据要显示在combotree里面:
Oracle中connect by...start with...的使用 一、使用范围:connect by可以用于级联查询,常用于对具有树状结构的记录查询某一节点的所有子孙节点或所有祖辈节点。 一、语法 大致写法:select * from some_table [where 条件1] connect by [条件2] start with [条件3]; 其中 connect by 与 start with 语句摆放的先后顺序不影响查询的结果,[where 条件1]可以不需要。 [where 条件1]、[条件2]、[条件3]各自作用的范围都不相同: [where 条件1]是在根据“connect by [条件2] start with [条件3]”选择出来的记录中进行过滤,是针对单条记录的过滤, 不会考虑树的结构; [条件2]指定构造树的条件,以及对树分支的过滤条件,在这里执行的过滤会把符合条件的记录及其下的所有子节点都过滤掉; [条件3]限定作为搜索起始点的条件,如果是自上而下的搜索则是限定作为根节点的条件,如果是自下而上的搜索则是限定作为叶子节点的条件; 示例1: 假如有如下结构的表:some_table(id,p_id,name),其中p_id保存父记录的id。 select * from some_table t where t.id!=123 connect by prior t.p_id=t.id and t.p_id!=321 start with t.p_id=33 or t.p_id=66; 对prior的说明: prior存在于[条件2]中,可以不要,不要的时候只能查找到符合“start with [条件3]”的记录,不会在寻找这些记录的子节点。要的时候有两种写法:connect by prior t.p_id=t.id 或 connect by t.p_id=prior t.id,前一种写法表示采用自上而下的搜索方式(先找父节点然后找子节点),后一种写法表示采用自下而上的搜索方式(先找叶子节点然后找父节点)。
示例2:
来看一个示例,现假设我们拥有一个菜单表t_menu,其中只有三个字段:id、name和parent_id。它们是具有父子关系的,最顶级的菜单对应的parent_id为0。现假设我们拥有如下记录:
| id | name | parent_id |
| 1 | 菜单01 | 0 |
| 2 | 菜单02 | 0 |
| 3 | 菜单03 | 0 |
| 4 | 菜单0101 | 1 |
| 5 | 菜单0102 | 1 |
| 6 | 菜单0103 | 1 |
| 7 | 菜单010101 | 4 |
| 8 | 菜单010201 | 5 |
| 9 | 菜单010301 | 6 |
| 10 | 菜单0201 | 2 |
| 11 | 菜单0202 | 2 |
| 12 | 菜单020101 | 10 |
| 13 | 菜单020102 | 10 |
| 14 | 菜单020103 | 10 |
| 15 | 菜单0301 | 3 |
| 16 | 菜单0302 | 3 |
| 17 | 菜单030201 | 16 |
| 18 | 菜单030202 | 16 |
| 19 | 菜单030203 | 16 |
如果这个时候我们需要查询“菜单01”以及其下所有的子孙菜单应该怎么办呢?如果使用connect by的话这将会非常简单,使用如下SQL语句就可以达到对应的效果。
- select * from t_menu connect by parent_id=prior id start with id=1;
connect by是需要跟start with一起使用的。connect by后跟的是连接条件,在connect by后接的条件通常都需要使用关键字“prior”,可以简单的把它理解为上一级,所以上述例子中“connect by parent_id=prior id”就表示连接条件为parent_id等于上级的id,查找到下一级记录后又会找parent_id等于下一级记录的id的记录,而prior对应的最顶层的记录就是通过start with来确定的,start with后接对应的筛选条件,表示最顶层的记录是哪些,最顶层的记录可以有多个,比如我想查找“菜单01”下的子孙菜单,但是不包括“菜单01”本身,那么我就可以使用如下的SQL语句进行查找,此时“start with parent_id=1”对应的记录就会有多条。
- select * from t_menu connect by parent_id=prior id start with parent_id=1;
对应的结果为:
| id | name | parent_id |
| 4 | 菜单0101 | 1 |
| 5 | 菜单0102 | 1 |
| 6 | 菜单0103 | 1 |
| 7 | 菜单010101 | 4 |
| 8 | 菜单010201 | 5 |
| 9 | 菜单010301 | 6 |
此外,如果我们想查找“菜单010101”对应的祖辈菜单也非常简单,如下SQL就可以实现该功能,即从“菜单010101”的父菜单(对应id为4)开始查找。
- select * from t_menu connect by id=prior parent_id start with id=4;
对应的结果为:
| id | name | parent_id |
| 1 | 菜单01 | 0 |
| 4 | 菜单0101 | 1 |
示例3:
先用scott用户下的emp表做实验. emp表有个字段,一个是empno(员工编号),另一个是mgr(上级经理编号) 下面是表中所有数据
select*fromemp startwithempno=7698connectbymgr=priorempno;执行结果如下:
得到的结果是empno=7698的数据,以及会得到mgr=7698的数据。 它是向下递归的, 即我们从empno=7698开始遍历,去找出mgr=7698的所有数据S(用S代表查出的所有数据.), 然后在从S中的empno的值去匹配查找是否还有满足,mgr in (s.empno)的数据。一直遍历进去到没有数据为止。
下面的这个可以详细的表述效果。
--向下递归遍历select*fromempconnectbymgr=priorempno startwithempno=7839;执行结果如下:
--向上递归遍历select * from emp connect by prior mgr=empno start with empno=7844;执行结果如下:
这样直到没有匹配的数据为止。 以上只是简单的举了个例子。
connect by是结构化查询中用到的,其基本语法是:
select...fromtablenamestartbycond1connectbycond2wherecond3简单说来是将一个树状结构存储在一张表里,比如一个表中存在两个字段(如emp表中的empno和mgr字段):empno, mgr那么通过表示每一条记录的mgr是谁,就可以形成一个树状结构。
用上述语法的查询可以取得这棵树的所有记录。 其中: cond1是根结点的限定语句,当然可以放宽限定条件,以取得多个根结点,实际就是多棵树。 cond2是连接条件,其中用prior表示上一条记录,比如connect by prior id=praentid就是说上一条记录的id是本条记录的praentid,即本记录的父亲是上一条记录。 cond3是过滤条件,用于对返回的所有记录进行过滤。 prior和start with关键字是可选项 prior运算符必须放置在连接关系的两列中某一个的前面。对于节点间的父子关系,prior运算符在一侧表示父节点,在另一侧表示子节点,从而确定查找树结构是的顺序是自顶向下还是自底向上。在连接关系中,除了可以使用列名外,还允许使用列表达式。 start with子句为可选项,用来标识哪个节点作为查找树型结构的根节点。若该子句被省略,则表示所有满足查询条件的行作为根节点。
参考连接:点击打开链接


















 8095
8095











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









