







coursera-斯坦福-机器学习-吴恩达-第9周笔记(下)-推荐系统
1预测电影等级
推荐系统(recommender systems),比如对像 Netflix 这样的公司 ,他们向用户推荐的电影 占了用户观看的电影的 相当大一部分 。
对于机器学习来说 特征量是重要的, 你选择的特征 对你学习算法的表现有很大影响。 在机器学习领域 有这么一个宏大的想法, 就是对于一些问题 存在一些算法, 能试图自动地替你学习到一组优良的特征量。
而推荐系统 就是这种情形的一个例子。还有其他很多例子 但通过学习推荐系统 ,我们将能够 对这种学习特征量的想法 有一点理解。
1.1任务设想
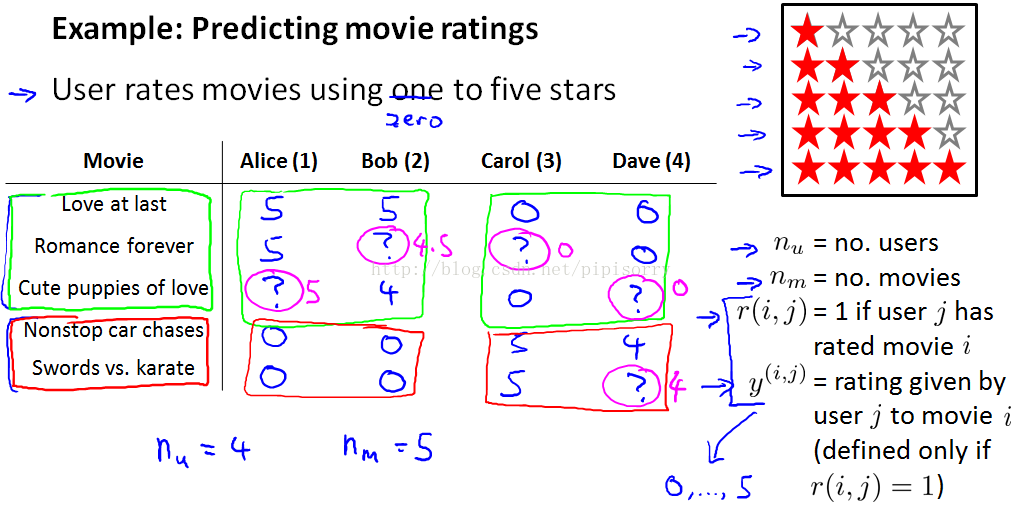
我这里有5部电影 《爱到最后》 《浪漫永远》 《小爱犬》 《无尽狂飙》 还有 《剑与空手道》。 我们有4位用户 名叫 Alice Bob Carol 和 Dave 。首字母为A B C和D 我们称他们用户1 2 3和4 。比方说 ,Alice 她非常喜欢 《爱到最后》 把它评为5颗星。 她还喜欢 《浪漫永远》 也把它评为5颗星。 她没看过 《小爱犬》 也就没评分, 这样我们没有这个评分数据。
我们查看数据并查看所有缺失的电影评级,并试图预测这些问号的值应该是多少。
1.2基于内容的推荐
每个items都有一些features,如果我们知道它们的值是多少,同时每个用户通过θj告诉我们他们有多喜欢romantic或者action movies。这种按照内容的特征来推荐的算法就是——基于内容推荐。

使用梯度下降优化:

如果你觉得这个 梯度下降的更新 看起来跟之前 线性回归差不多的话, 那是因为这其实就是线性回归, 唯一的一点区别 是在线性回归中 我们有1/m项 。
通过这节课 你应该知道了 怎样应用一种 事实上是线性回归的一个变体, 来预测不同用户对不同电影的评分值 ,这种具体的算法叫 ”基于内容的推荐“ 或者”基于内容的方法“。 因为我们假设 我们有不同电影的特征 ,我们有了电影 内容的特征 比如电影的爱情成分有多少?动作成分有多少? 我们就是用电影的这些特征 来进行预测 。
但事实上 对很多电影 我们并没有这些特征 或者说 很难得到 所有电影的特征 很难知道 我们要卖的产品 有什么样的特征 。所以在下一段视频中 我们将谈到一种不基于内容的推荐系统:协同过滤。
2协同过滤
2.1协同过滤
在这段视频中 我们要讲 一种构建推荐系统的方法 叫做协同过滤(collaborative filtering) 。
算法 有一个值得一提的 特点 ,那就是它能实现 对特征的学习。 我的意思是 这种算法能够 自行学习所要使用的特征 。
我们建一个数据集 ,假定是为每一部电影准备的 ,对每一部电影 我们找一些人来 告诉我们这部电影 浪漫指数是多少 动作指数是多少。
但想一下就知道 这样做难度很大, 也很花费时间 。你想想 要让每个人 看完每一部电影 告诉你你每一部电影有多浪漫 多动作 这是一件不容易的事情。
现在我们稍稍改变一下这个假设 ,假设我们采访了每一位用户 而且每一位用户都告诉我们 他们是否喜欢 爱情电影。
总结一下, 这一阶段要做的 就是为所有 为电影评分的 用户 j 选择特征 x(i)。 这一算法同样也预测出一个值 ,表示该用户将会如何评价某部电影。 而这个预测值 在平方误差的形式中 与用户对该电影评分的实际值尽量接近 。
优化目标:
minx(1),...,x(nm)12∑i=1nm∑j:r(i,j)=1((θ(j))Tx(i)−y(i,j))2+λ2∑
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 851
851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









