






摘要:
考虑多元关系数据得实体和关系在低维向量空间的嵌入问题。我们的目标是提出一个权威的模型,该模型比较容易训练,包含一组简化了的参数,并且能够扩展到非常大的数据库。因此,我们提出了TransE,一个将关系作为低维空间实体嵌入的翻译的方法。尽管它很简单,但是这种假设被证明是强大的,因为大量的实验表明在两个知识库连接预测方面,TransE明显优于目前最新的方法。除此之外,它能够成功地训练一个有1M的实体,25k的关系和超过17M的训练样例的大规模数据集。
1简介
多元关系数据适用于有向图,图的结点和边与元组(head,label,tail)对应(表示为(h,l,t)),每个元组意为在实体head和tail之间存在一个名为label的关系。多元关系数据模型在很多领域扮演着很重要的角色。例如社交网络,实体是成员,边是朋友/社会关系连接,又如推荐系统中的实体是用户和产品,关系为买,评级,检索或搜索一个商品,再或者知识库,如Freebase,Google知识图谱或GeneOntology,这些知识库中的每个实体代表世界中的一个抽象概念或者具体的实体,关系式谓词,代表他们两个之间的事实。我们的工作重点是对知识库的多元关系数据建模,提出一个高效地工具通过自动增加事实,而不需要额外的知识来完成它们。
多元关系数据建模 一般而言,建模过程归结为抽取实体间局部或者总体的连接模式,通过这些模式概括观测的一个特定的实体和其它所有的实体之间的关系来预测。一个局部的单个关系的概念可能是一个纯粹的结构,比如在社交网络中,我的朋友的朋友是我的朋友,但也可以依赖于实体,例如,一些喜欢看Star Wars IV的人也喜欢Star Wars V,但是他们可能喜欢Titanic也可能不喜欢。相比之下,经过一些数据的描述性分析后可以形成单关系数据专门的但是简单地模型假设。关系数据的难点在于局部概念在同一时间可能涉及关系和实体的不同类型,以致对多关系数据建模时要求更一般的方法,这种方法能在考虑所有多样的关系同时选择合适模型。
文献[6]指出,随着基于用户/项目聚类或矩阵分解的协同过滤技术在表示单关系数据的实体连接模型之间极大地相似之处的成功,为了处理多关系数据,大多数的方法都是基于从潜在的特征进行关系学习的框架下进行设计的;也就是说,通过实体和关系的潜在表示来学习和操作。在多关系领域,这些方法的扩展形式例如随机块模型[7][10][11]的非参贝叶斯扩展和基于张量分解[5]或者集体矩阵分解[13][11][12]的模型,在低维空间实体嵌入学习方面,这些最近的方法很多都致力于增加模型的表达性和一般性,不管是贝叶斯聚类框架还是能量模型。这些方法的表达性虽然有较大的提高,但是也大幅增加了模型的复杂性,以致模型假设很难解释,且计算成本更高。除此之外,这样的方法可能受限于过拟合,因为对如此复杂的模型进行适当的正则化是很难的,或者受限于欠拟合,因为非凸优化问题有很多的局部极小值,这些是需要解决和训练的。事实上,文献[2]指出了一个简单的模型(线性代替双线性)在一个具有相对较多数量的不同关系的几个多元关系数据集上取得了与大多数表达性好的模型同样好的性能。这说明,即使在复杂和异质的多元关系领域,简单但是恰当的模型假设能够在精度和扩展性之间实现较好的折中。
关系在嵌入空间上的翻译 本文,我们介绍TransE,一个基于能量的模型,用于低维实体嵌入学习。在TransE中,关系表示为嵌入空间上的翻译:如果有(h, l,t),那么尾实体t的嵌入应该与头实体的嵌入h加上一些依赖于关系l的向量接近。我们的方法依赖于一组简化了的参数集学习每个实体和关系一个低维向量。
我们提出的基于翻译的参数化模型的主要动机是层次关系在知识库中是极常见的,而翻译是为了解释它们的一个自然变换。考虑树的自然表示(比如,二叉树),兄弟结点互相挨着,并且这些节点在x轴上以一定的高度排列,父亲-孩子关系与在y轴上的一个翻译对应。因为一个空的翻译向量与两个实体之间的关系等价是对应的,所以,这个模型同样能够表示兄弟关系。因此,我们选择使用每个关系的参数预算(一个低维向量)来表示在知识库中我们所考虑的关键关系。我们的第二个动机来源于文献[8],作者从自由文本中学习词嵌入,并且不同实体之间有1对1的关系,例如国家和城市之间的省会关系,表示为嵌入空间上的翻译。这说明可能存在这样一个嵌入空间,不同类型实体之间存在1对1关系,且被表示为翻译。我们的模型的目的是加强嵌入空间中的这样的结构。
第4节的实验证明这是一个新模型,尽管它很简单且主要是为层次结构模型的问题建模,但是它在大多数的各种各样的关系下被证明是是很有效的,并且在realworld知识库中的连接预测方面,明显优于目前最新的方法。除此之外,较少的参数使得它能够成功训练从包含1M实体和25k的关系并且超过17M的训练样例分割的Freebase大规模数据集。
在第2节我们描述我们的模型并且在第3节讨论它和相关方法的联系。第4节我们详述基于Wordnet和Freebase相关的大量实验,并拿TransE和文献中的很多方法做比较。在第5节里,阐述结论并指出未来的研究方向。

2transE模型

3相关工作

4实验
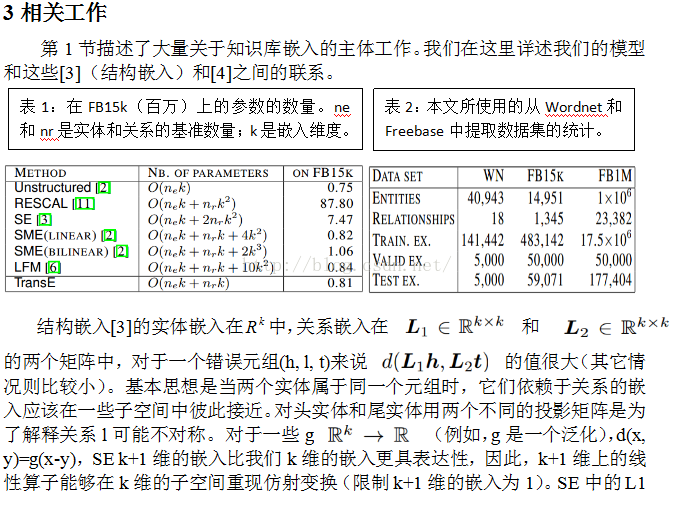
TransE的实验数据是从Wordnet和Freebase中抽取的(它们的统计分布已经在表2中给出),并以各种各样的标准和扩展到相对较大的数据集上与文献中几个已经证明是现在最好的几个方法比较。
4.1数据集
Wordnet 这个知识库用于产生直觉上可用的字典和辞典,并且支持自动文本分析。它的实体对应着词义,关系定义它们之间的词汇关系。我们使用了文献[2]中使用的数据版本,我们在下面表示WN。元组的样例为(score NN 1, hypernym, evaluation NN 1)或者(score NN 2, has part, musical notation NN 1)。
Freebase Freebase是一个一般事实很大并且不断增长的知识库;目前有大约12亿的元组和超过8千万的实体。我们用Freebase构造两个数据集,做一个小的数据集在我们所选择的实体子集上做实验,这个数据集也在Wikilinks数据库中,并且至少有100个在Freebase中(包含实体和关系)。我们移除像’!/people/person/nationality’的关系,与关系’/people/person/nationality’相比仅仅把头和尾互换。结果是含有14951个实体和1345个关系的592,213个元组被随机分割,如表2。在本节的剩余部分这个数据集表示为FB15k。我们也想用一个大规模的数据在规模上去测试TransE。因此,我们从Freebase构造了另一个数据集,通过选择最频繁出现的1百万个实体。这个分割大约有25k的关系和超过170万的训练元组,称为FB1M。
4.2实验设置
评价方案 我们使用跟文献[3]一样的排名过程。对每个测试元组,头部被移去或者被字典中的每个实体轮流替换。首先通过模型计算这些错误元组的相似性(或者能量),然后按升序排列;最后,正确的实体排名被存储。重复这个过程,把移去头部用移去尾部代替。我们报告这些预测排名的平均值和hits@10,也就是,排在前10的正确实体的比例。
这些度量有一定的参考性但是当一些错误元组在验证集上时也有缺陷。在这种情况下,这些可能排在测试元组之上,但是这不应该被作为一个错误计算,因为这两者都是正确的。为了避免这样一个误导的行为,我们移除所有的错误元组,不管是出现在训练集和验证集或者测试集中的。这保证了所有的错误元组不属于数据集。在下文中,我们报告这两种设置下的平均排名和hits@10:原始的数据在论文中为raw,新的为filt。在FB1M的实验上,我们仅提供了原始数据的结果。
标准 第一个方法是无结构的,TransE的一个版本,只考虑了数据的单一关系并且置所有的翻译为0(文献[2]也将它作为标准使用)。我们也和RESCAL作比较,RESCAL是文献[11][12]提出的集体矩阵分解模型,同时也和文献[3]的能量模型SE、文献[2]中的SME(线性)/SME(双线性)以及文献[6]的LFM作比较。RESCAL通过交替最小二乘法训练,其它的与TransE一样通过随机梯度下降训练。表1比较了模型的理论参数数量,并且在FB15k上给出了数量级。SME(线性), SME(双线性), LFM和TransE作为无结构的低维嵌入的参数数量几乎一样,对于SE和RESCAL算法,每个关系要学习至少k*k维的矩阵,因此需要学习更多的参数。在FB15k上,RESCAL大约需要87倍多的参数,因为它比其它模型需要一个较大的嵌入空间以取得较好的性能。因为参数的规模和训练时间原因我们没有在FB1M上做关于RESCAL,SME和LFM的实验。
我们所有的训练方法得代码都是由提出这些方法的作者提供的。对于RESCAL,由于规模原因,我们必须设置正则化参数为0,这一点在文献[11]中已经表明,并且在{50,250,500,1000,2000}中选择隐藏维数k,这可以导致在验证集上取得较低的平均预测排名(使用原始数据)。对于无结构的SE, SME(线性)和SME(双线性),在{0.001,0.01,0.1}中选择学习率,在{20,50}中选择k,并且使用在验证集上的平均排名来选择最好的模型(在训练数据上最多执行1000次)。对于LFM,我们也是用平均验证排名来选择模型,并在{25,50,75}中选择隐藏维数,在{50,100,200,500}中选择因素的数量,在{0.01,0.1,0.5}中选择学习率。
实现 关于TransE的实验,对于随机梯度下降的学习率λ从{0.001,0.01,0.1}中选择,边际值γ从{1,2,10}中选择,k从{20,50}中选择。相似性度量d根据验证的性能选择L1选择L2。优化配置为:在Wordnet上k=20,λ=0.01,γ=1,d=L1;在FB15k上,k=50,λ=0.01,γ=1,d=L1;在FB1M上,k=50,λ=0.01,γ=1,d=L2。对所有的训练集,训练时间最多为1000次。最好的模型通过验证集(原始数据)上的平均排名来选取。在注释6的网页上公开了TransE的实现资源。
4.3链接预测
表3:链接预测结果。不同方法的性能。
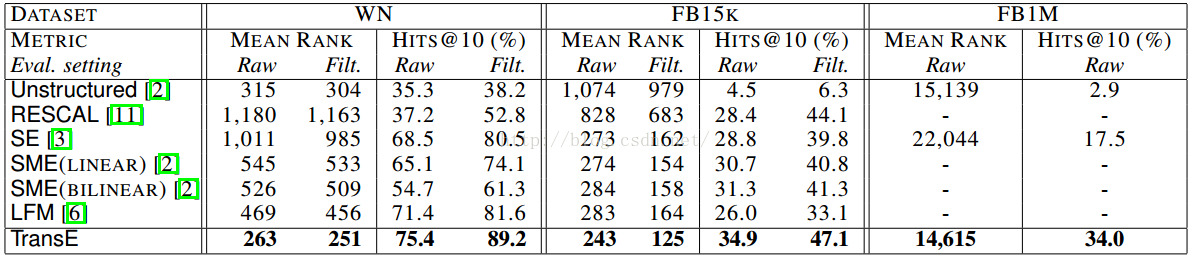
总体结果 表3显示了所有数据集所有方法的比较。与预期结果一致,经过过滤设置的结果具有较低的平均排名和较高的hits@10,相信在链接预测方面对各种方法有一个清晰地性能评估。然而,raw和filtered的趋势是一样的。
我们的方法TransE在所有度量上面通常很大程度上优于所有进行比较的方法,并且取得了一些绝对好的性能例如WN上89%的hits@10(超过40k的实体)和在FB1M上的34%的hits@10(超过1M的实体)。TransE和这些第二好的方法之间的不同之处是很重要的。
我们相信TransE良好的性能是由于对数据恰当的建模,但也是由于模型相对简单。这意味着它能够用随机梯度有效的优化。第3节我们已经说明SE比我们的模型更具表达性。然而,它的复杂性可能使它学习起来十分困难,导致性能很差。在FB15k上,在训练集的一个有50k的元组的子集上SE取得了165的平均排名和35.5%的hits@10,TransE则分别取得了127和42.7%,这表明事实上TransE欠拟合的程度更小,这可能能解释它比较好的性能。SME(双线性)和LFM有同样的训练问题:我们从来都没有成功的把它们训练的足够好来开发出它们所有的功能。通过我们的评价设置–基于实体排名,LFM较差的结果也可以解释,因为LFM最初是为了预测关系提出来的。在FB15k上,RESCAL能够取得十分好的hits@10,但是平均排名方面比较差,尤其在WN上,即使我们用很大的隐藏维度(2000 on Wordnet)。
翻译的影响是巨大的。当比较TransE和非结构的方法(也就是缺少翻译的TransE),非结构化的平均排名相对较好,但是hits@10非常差。非结构化的方法简单的把所有出现的实体聚类,不依赖所涉及的关系,因此仅仅靠猜想来判断实体相关。在FB1M上,TransE和非结构化方法的平均排名几乎一样,但是TransE的预测排在前10位的数目是非结构化方法的10倍之多。
表4:关系聚类的详细结果。我们比较了在FB15k上以过滤数据为评价比较TransE和参考方法的hits@10。

详细结果 表4展示了在FB15k上依据关系的几种类别的分类结果,并依此对几种方法进行预测。我们根据头和尾的基数参数把关系分为4类:1-1,1-多,多-1,多-多。如果一个头部至多对应一个尾部,那么它们的关系是1-1,如果一个头部对应多个尾部,那么它们的关系是1-多,如果很多头部对应同一个尾部,那么它们的关系是多-1,如果多个头部对应多个尾部,那么它们是多-多关系。通过下面的处理我们把关系分成这四类,给定一个序对(l,t)(同样地,序对(h,l),对每个关系l,计算头部h(同样地,尾部t)出现在FB15k数据集上的平均数。如果这个平均数小于1.5就被标记为1-多等等。例如,每个尾部平均有1.2个实体并且每个头部平均有3.2个尾部的关系被分类为1-多。我们得到在FB15k上有26.2%的1-1关系,22.7%的1-多关系,28.3%的多-1关系和22.8%的多-多关系。
表4中的详细结果考虑了一个更精确的评估并且了解了这些方法的行为。首先,它出现了期望的结果,它能够很容易的预测实体一方只有一个对应关系的元组的实体(也就是预测在关系1-多下预测头部,在多-1关系下预测尾部),也就是有多个实体指向它的时候。这些是有很好指向的例子。SME(双线性)被证明在处理这样的例子时时很精确的,因为这些例子是它们训练最多的样例。非结构化的方法在1-1关系上显示了良好的性能:这表明这样的关系的参数必须共享相同的隐藏类型,而非结构化的方法在嵌入空间上通过聚类把实体连接在一起能够发现这样的隐藏类型。但是这种策略在其它关系类型上是失败的。在嵌入空间增加翻译,通过其后的关系从一个实体聚类到另一个实体聚类。对这些指向性很好的例子这一点是非常惊人的。
表5:TransE在FB15k测试集上的样例预测。粗体是测试元组正确的尾部,斜体是训练集上其它正确的尾部。
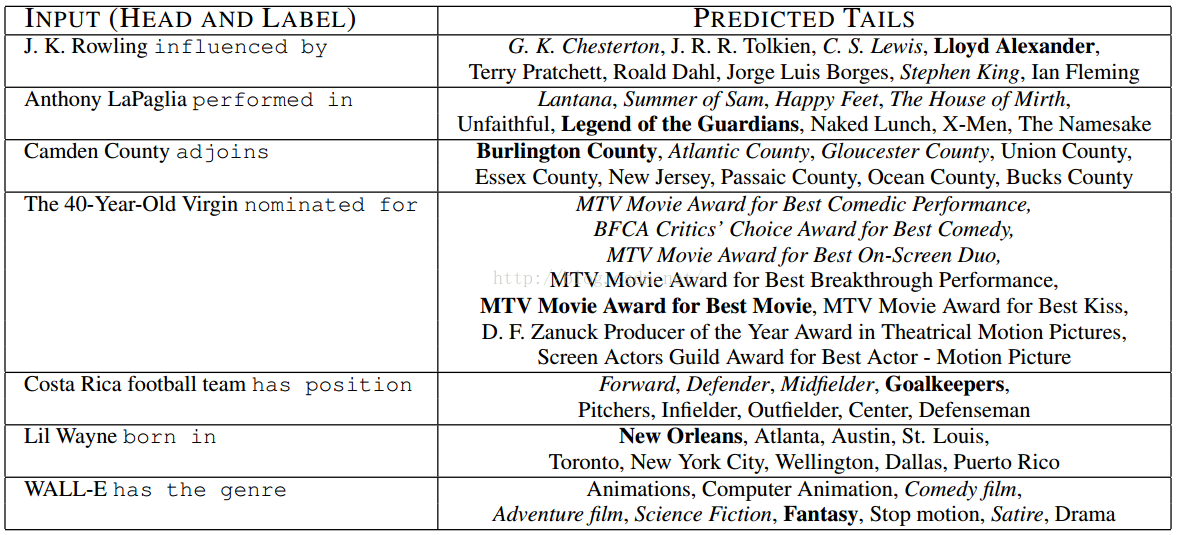
举例说明 表5给出了TransE在FB15k测试集上的样例链接预测的结果。这举例说明了我们模型的能力。给定一个头部和一个标签,排在最高位的尾部被描述出来。这些样例来自FB15k的测试集。即使排在最高位的不总是最好的答案,但这个预测也反映了一般的常识。
4.4用几个例子学习预测新关系
用FB15k,通过检查这些方法在学习新关系时的速度有多快来测试他们在泛化新的事实方面有多好。为了那个目的,我们随机选择40个关系并且分割成两个数据集:一个数据集(命名为FB15k-40rel)包含所有40个元组,另一个数据集(FB15k-rest)包含剩余的数据。我们确保它们包含所有的实体。FB15k-rest被分割成一个包含353,788个元组的训练集和一个包含53,266个元组的验证集。FB15-rel分成40,000元组的训练集和45,159的测试集。利用这些数据集,我们分析如下实验:(1)利用FB15k-rest的训练集和验证集训练和选择最好的模型,(2)随后在FB15k-40rel的训练集上训练并且只学习和新的40个关系相关的参数,(3)在FB15k-40rel的测试集(只包含(1)期间没有见过的关系)上进行连接预测评估。在(2)阶段,对每个关系我们用0,10,100和1000个样例重复这个过程。
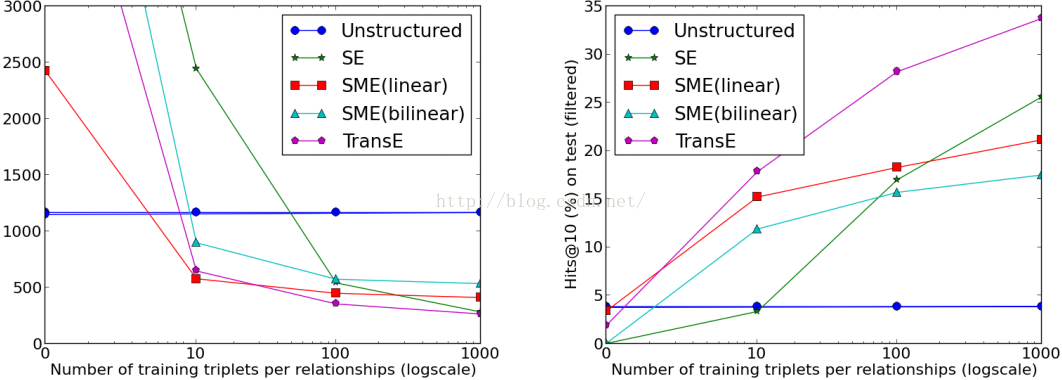
图1:用几个样例学习心关系。比较试验数据是FB15k数据集,使用平均排名(左)和hits@10(右)作为评价标准。更多细节参见下文。
图1展示了非结构化方法,SE,SME(线性),SME(双线性)和TransE的结果。但不提供已知关系时,非结构化方法取得的性能最好,因为它并不使用这些信息去预测。但是,当提供关系的例子时这种性能并没有得到提升。TransE是学习最快的方法:只有一个新关系的10个样子时,它的hits@10仍然有18%,并且随着提供样例的增加这个数据单调递增。我们相信TransE模型的简单性使它能够有较好的泛化能力,而不必修改任何已经训练好的嵌入。
5总结和展望
我们提出了一种新的学习知识库嵌入的方法,主要是最小化模型的参数,主要表示层次关系。通过与两个不同且规模很大的知识库上和其它方法比较,我们的模型效果很好,借此我们把它应用到了大规模知识库数据块上。尽管还不清楚用我们的方法是否能够充分地对所有的关系类型建模,但是通过关系分类评价与其他方法相比在所有的设置条件下它似乎有很好的性能。
后面会进一步分析这个模型,并且把它应用到更多的任务中,特别是应用到如文献[8]提到的学习词表示。结合知识库和文本[2]是另一个重要的方向,我们的方法对此可能是有用的。因此,最近我们把TransE插入到一个框架中从文本[16]中进行关系抽取。














 1190
1190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









