







基本介绍
信号量是一种用于提供不同进程间或一个给定进程的不同线程间同步手段的原语,我们将会讨论3钟类型的信号量
1、POSIX有名信号量, 可用于进程间或线程间同步
2、POSIX基于内存的信号量:存放在共享内存区中,可用于进程间或线程间同步
3、System V信号量:在内核中维护,可用于进程间或线程间同步
信号量可以被指定为二值信号量, 往往用于互斥的目的, 就好比互斥锁
除了可以像互斥锁那样使用外,信号量还有一个特性:
互斥锁必须总是由锁住它的线程解锁,信号量的挂出(V操作)却不必由执行过它的等待操作(V操作)的同一线程执行。
比如以下拿生产者和消费者例子:
假设缓存区只能容纳一个条目
把信号量get置0 //get指可取条目数
把信号量put置1 //put指可放入条目数
下面列出信号量、互斥锁、条件变量之间的差异:
1、互斥锁必须总是由给它上锁的线程解锁,信号量的V操作却不必由执行过它的P操作的同一线程执行,看上面的生产者消费者就是如此
2、互斥锁要么被锁住,要么被解开(只能对应于二值信号量)
3、既然信号量有一个与之关联的状态(它的计数值),那么信号量的V操作总是被记住, 即不会因为没有人在wait这个信号量而导致此操作失效。然而当向一个条件变量发送信号时,如果没有线程等待在该条件变量上,那么该信号就会丢失了
Posix提供两种信号量, 有名(named)信号量以及基于内存(memory-based / unnamed)的信号量
如下图, 比较这两种信号量使用的函数区别:
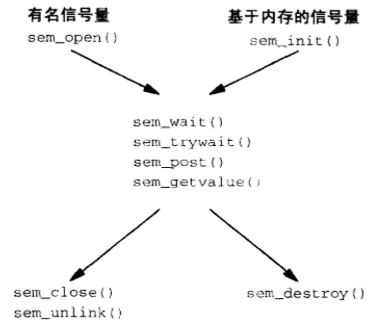
操作函数:
创建或打开一个有名信号量, 有名信号量总是可以既用于线程同步, 也可用于进程间同步
此函数返回的指针指向某个sem_t类型数据, 用于随后的信号量操作
关闭信号量
关闭一个有名信号量并没有将其从系统中删除,即有名信号量是随内核持续的:即使没有进程打开着某个信号量,它的值仍保持
真正删除信号量
P操作, 将信号量减1
当然,sem_wait函数也会因信号而中断从而返回EINTR错误
V操作, 将信号量加1
若该信号量当前已上锁,那么返回值或为0 或为某个负数(看系统的不同实现),其绝对值等于等待该信号量解锁的线程数
最后, 要注意的是, 在各种各样的同步技巧中, (互斥锁, 条件变量, 读写锁, 信号量中), 能在信号处理程序中安全调用(异步安全)的唯一函数是 sem_post
互斥锁往往是为了上锁而优化的, 条件变量往往是为了等待而优化的, 虽然信号量既可以用于上锁,也可以用于等待, 但是它的开销和复杂性则更显著
Posix基于内存的信号量(无名信号量)
sem_init函数地二个参数pshared变量, 如果值为0, 那么等待初始化的信号量是一个进程内各个线程共享的; 不为0则为进程间共享的
若需要无名信号量能构在进程间共享, 那么该信号量必须是被放在共享内存区中的
基于内存的信号量至少具有随进程的持续性, 真正的共享性取决于存放该信号量的内存区. 只要该内存区存在, 信号量就一直存在
又因为共享内存区一般具备随内核的持续性, 这就意味着某进程在一个共享内存区中创建一个信号量,然后终止. 一段时间后, 另一个进程打开共享内存区, 亦然可以访问放在其中的基于内存的信号量
Posix信号量处理消费者生产者问题
当我们的缓冲区是一个共享缓冲区, 必须由代码来维护以下三个条件:
1 当缓冲区为空, 消费者不能取出
2 当缓冲区满了, 生产者不能继续投放
3 生产者和消费者对缓冲区的操作必须被保护起来, 避免竞争(比如两个消费者, 同时发现缓冲区有1个产品, 那么每个消费动作必须被保护. 我们可能会考虑会不会得到同样的产品数量值呢? 这是不会的, 因为P、V操作默认是原子的)
所以, 代码如下:
接着, 继续看多个生产者以及一个消费者如何实现:
进一步, 多个生产者, 多个消费者:
关于多个生产者与多个消费者问题探讨的意义, 作者举了两个实际情况的例子:
1 把IP地址转化为主机名的服务, 每个消费者取出一个IP地址使用gethostbyaddr处理. 由于处理每个IP的时间消耗不同, 所以多线程处理就有优势了
2 读出UDP数据报, 接着操作后写入某数据库程序. 处理的快的数据可以早些放入数据库
于是, 我们更新了全局变量
接下来, 我们利用信号量处理多个缓冲区的问题
当我们使用shell 命令cp的时候, 往往是单进程读写.
我们可能想到使用多线程或多进程来加快速度, 如果有需要的话
此时我们使用两个线程(进程), 一个线程只读, 一个线程只写. 但如果只是这样, 很明显并没有任何加快速度的痕迹. 依旧是读一段内容, 通知另一个线程写一段内容; 写线程可读时再通知读线程继续读
但如果我们使用两个缓冲区, 就可以达到异步读写的作用
当读线程将缓冲区1写满, 于是通知写进程来读取内容写到目的地去. 此时读线程继续向缓冲区2写. 缓冲区2写满后让写线程来读缓冲区2, 而读进程又向缓冲区1写内容...
这就是经典的双缓冲方案.
信号量是一种用于提供不同进程间或一个给定进程的不同线程间同步手段的原语,我们将会讨论3钟类型的信号量
1、POSIX有名信号量, 可用于进程间或线程间同步
2、POSIX基于内存的信号量:存放在共享内存区中,可用于进程间或线程间同步
3、System V信号量:在内核中维护,可用于进程间或线程间同步
信号量可以被指定为二值信号量, 往往用于互斥的目的, 就好比互斥锁
初始化互斥锁 初始化信号量为1
pthread_mutex_lock(&mutex) sem_wait(&sem)
临界区 临界区
pthread_mutex_unlock(&mutex) sem_post(&sem)除了可以像互斥锁那样使用外,信号量还有一个特性:
互斥锁必须总是由锁住它的线程解锁,信号量的挂出(V操作)却不必由执行过它的等待操作(V操作)的同一线程执行。
比如以下拿生产者和消费者例子:
假设缓存区只能容纳一个条目
把信号量get置0 //get指可取条目数
把信号量put置1 //put指可放入条目数
生产者: 与此同时消费者:
for(;;){ for(;;){
sem_wait(&put); sem_wait(&get);
把数据放入缓存区 消耗数据
sem_post(&get); sem_post(&put);
} }下面列出信号量、互斥锁、条件变量之间的差异:
1、互斥锁必须总是由给它上锁的线程解锁,信号量的V操作却不必由执行过它的P操作的同一线程执行,看上面的生产者消费者就是如此
2、互斥锁要么被锁住,要么被解开(只能对应于二值信号量)
3、既然信号量有一个与之关联的状态(它的计数值),那么信号量的V操作总是被记住, 即不会因为没有人在wait这个信号量而导致此操作失效。然而当向一个条件变量发送信号时,如果没有线程等待在该条件变量上,那么该信号就会丢失了
Posix提供两种信号量, 有名(named)信号量以及基于内存(memory-based / unnamed)的信号量
如下图, 比较这两种信号量使用的函数区别:
操作函数:
创建或打开一个有名信号量, 有名信号量总是可以既用于线程同步, 也可用于进程间同步
sem_t *sem_open(const char *name, int oflag, ...
/* mode_t mode, unsigned int value */);此函数返回的指针指向某个sem_t类型数据, 用于随后的信号量操作
关闭信号量
int sem_close(sem_t *sem);关闭一个有名信号量并没有将其从系统中删除,即有名信号量是随内核持续的:即使没有进程打开着某个信号量,它的值仍保持
真正删除信号量
int sem_unlink(char *name);P操作, 将信号量减1
int sem_trywait(sem_t *sem);
int sem_wait(sem_t *sem);当然,sem_wait函数也会因信号而中断从而返回EINTR错误
V操作, 将信号量加1
int sem_post(sem_t *sem);int sem_getvalue(sem_t *sem,int *valp);若该信号量当前已上锁,那么返回值或为0 或为某个负数(看系统的不同实现),其绝对值等于等待该信号量解锁的线程数
最后, 要注意的是, 在各种各样的同步技巧中, (互斥锁, 条件变量, 读写锁, 信号量中), 能在信号处理程序中安全调用(异步安全)的唯一函数是 sem_post
互斥锁往往是为了上锁而优化的, 条件变量往往是为了等待而优化的, 虽然信号量既可以用于上锁,也可以用于等待, 但是它的开销和复杂性则更显著
Posix基于内存的信号量(无名信号量)
int sem_init(sem_t *sem, int pshared, unsigned int value);
nt sem_destroy(sem_t *sem);sem_init函数地二个参数pshared变量, 如果值为0, 那么等待初始化的信号量是一个进程内各个线程共享的; 不为0则为进程间共享的
若需要无名信号量能构在进程间共享, 那么该信号量必须是被放在共享内存区中的
基于内存的信号量至少具有随进程的持续性, 真正的共享性取决于存放该信号量的内存区. 只要该内存区存在, 信号量就一直存在
又因为共享内存区一般具备随内核的持续性, 这就意味着某进程在一个共享内存区中创建一个信号量,然后终止. 一段时间后, 另一个进程打开共享内存区, 亦然可以访问放在其中的基于内存的信号量
Posix信号量处理消费者生产者问题
当我们的缓冲区是一个共享缓冲区, 必须由代码来维护以下三个条件:
1 当缓冲区为空, 消费者不能取出
2 当缓冲区满了, 生产者不能继续投放
3 生产者和消费者对缓冲区的操作必须被保护起来, 避免竞争(比如两个消费者, 同时发现缓冲区有1个产品, 那么每个消费动作必须被保护. 我们可能会考虑会不会得到同样的产品数量值呢? 这是不会的, 因为P、V操作默认是原子的)
所以, 代码如下:
struct {
int buf[BUFSIZE];
sem_t *mutex, *nempty, *nfilled;
}shared;
void *produce(void *arg){
for(int i=0; i<N; i++){
sem_wait(shared.nempty);
sem_wait(shared.mutex);
shared.buf[i % BUFSIZE] = i;
sem_post(shared.mutex);
sem_post(shared.nfilled);
}
return NULL;
}
void *Consume(){
for(int i=0; i<N; i++){
sem_wait(shared.nfilled);
sem_wait(mutex);
if(shared.buf[i % BUFSIZE] == i)
do something...
sem_post(mutex);
sem_post(shared.nempty);
}
return NULL;
}接着, 继续看多个生产者以及一个消费者如何实现:
struct {
int buf[BUFSIZE];
int nput;
int put_value;
sem_t *mutex, *nempty, *nfilled;
}shared;
void *produce(void *arg){
for(;;){
sem_wait(&shared.nempty);
sem_wait(&shared.mutex);
if(shared.nput == items){
sem_post(&shared.mutex);
sem_post(&shared.nempty); //在结束时刻让nempty加一, 是为了唤醒其他阻塞在这个信号量的线程, 让他们能走到这个循环最终退出线程
break;
}
shared.buf[nput % BUFSIZE] = put_value;
shared.nput ++;
shared.put_value ++;
sem_post(&shared.mutex);
sem_post(&shared.nfilled);
}
return NULL;
}
void *Consume(){
for(int i=0; i<items; i++){
sem_wait(&shared.nfilled);
sem_wait(&shared.mutex);
if(shared.buf[i] == i)
do something...
sem_post(&shared.mutex);
sem_post(&shared.nempty);
}
return NULL;
}进一步, 多个生产者, 多个消费者:
关于多个生产者与多个消费者问题探讨的意义, 作者举了两个实际情况的例子:
1 把IP地址转化为主机名的服务, 每个消费者取出一个IP地址使用gethostbyaddr处理. 由于处理每个IP的时间消耗不同, 所以多线程处理就有优势了
2 读出UDP数据报, 接着操作后写入某数据库程序. 处理的快的数据可以早些放入数据库
于是, 我们更新了全局变量
struct {
int buf[BUFSIZE]
int nput;
int nputval;
int nget;
int ngetval;
sem_t mutex, nempty, nstored;
}shared;
只需要简单的修改消费者部分就可以了:
void *Consume(){
for(;;){
sem_wait(&shared.nstored);
sem_wait(&shared.mutex);
if(shared.nget >= items){
sem_post(&shared.nstored);
sem_post(&shared.mutex);
return NULL;
}
i = shared.nget % BUFSIZE;
if(shared.buf[i] == shared.ngetval)
do something...
shared.nget++;
shared.ngetval ++;
sem_post(&shared.mutex);
sem_post(&shared.nempty);
}
return NULL;
}
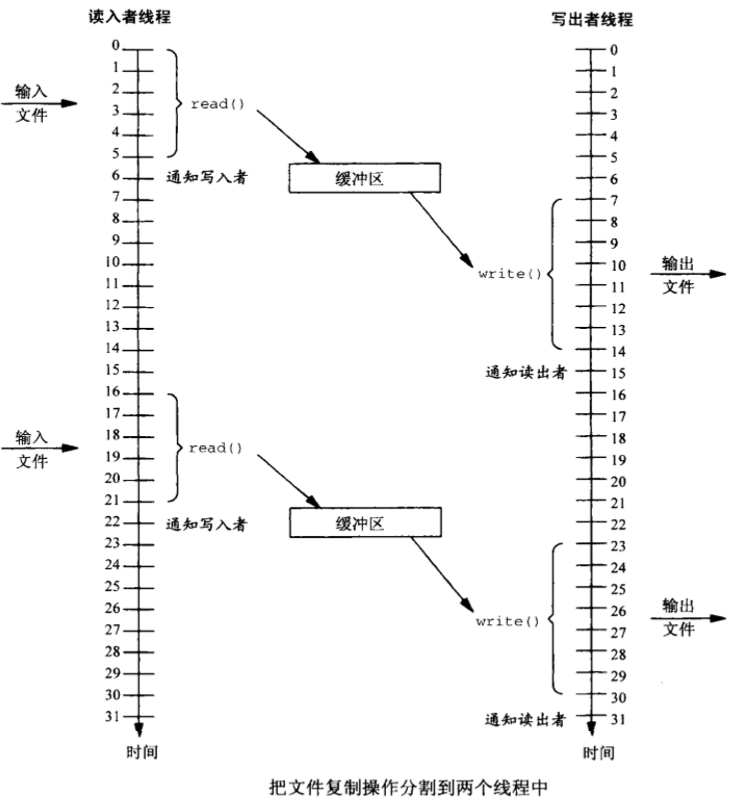
接下来, 我们利用信号量处理多个缓冲区的问题
当我们使用shell 命令cp的时候, 往往是单进程读写.
我们可能想到使用多线程或多进程来加快速度, 如果有需要的话
此时我们使用两个线程(进程), 一个线程只读, 一个线程只写. 但如果只是这样, 很明显并没有任何加快速度的痕迹. 依旧是读一段内容, 通知另一个线程写一段内容; 写线程可读时再通知读线程继续读
但如果我们使用两个缓冲区, 就可以达到异步读写的作用
当读线程将缓冲区1写满, 于是通知写进程来读取内容写到目的地去. 此时读线程继续向缓冲区2写. 缓冲区2写满后让写线程来读缓冲区2, 而读进程又向缓冲区1写内容...
这就是经典的双缓冲方案.
因此,我们可以将多缓冲方案应用到生产者与消费者问题上. 现在, 我们只有一个生产者一个消费者. 当生产者填满一个缓冲区后, 消费者被唤醒. 且生产者开始往另一个缓冲区填数据.














 1840
1840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









