







算法原理
LR
logistic(逻辑回归)是一种广义线性回归分析模型,是一种分类算法。
通过函数L将w‘x+b对应一个隐状态p,p =L(w‘x+b),然后根据p 与1-p的大小决定因变量的值。L是logistic函数.
该模型是典型的数学模型,它服从逻辑斯蒂分布。
二项逻辑斯蒂回归模型是如下的条件概率分布:
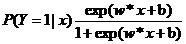
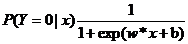
在这里,x是输入,y是输出,w是权值向量参数,b是偏置参数。
对于给定的输入实例x,按照以上两个公式可以求得P(Y=1|x)和P(Y=0|x)。逻辑斯蒂回归比较两个条件概率值的大小,将实例x分到概率值较大的那一类。
将权值向量和输入向量加以扩充,仍记作w,x,即w=(x1,x2,…,wn,b),x=(x1,x2,…,xn,1)。这时,逻辑斯蒂回归模型如下:
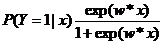
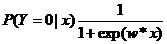
线性函数的值越接近正无穷,概率值就越接近1;线性函数的值越接近负无穷,概率值就越接近0.如下图:
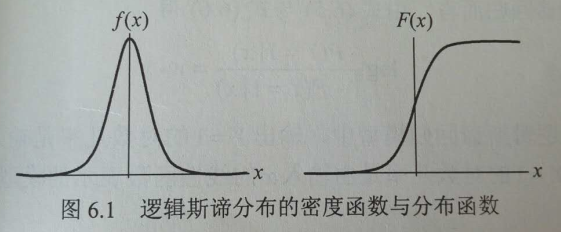
逻辑斯蒂回归模型学习时,对于给定的训练数据集可以应用极大似然估计法估计模型参数,这样,问题就变成了以对数似然函数为目标函数的最优化问题,逻辑斯蒂回归模型学习中通常采用的方法是梯度下降法及拟牛顿法。得到w的极大似然估计值w’,就可以得到逻辑斯蒂回归模型。
二项逻辑斯蒂回归模型可以推广到多项逻辑斯蒂回归模型:
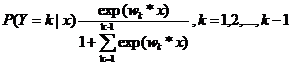
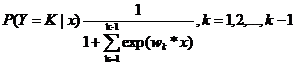
二项逻辑斯蒂回归的参数估计法也可以推广到多维逻辑斯蒂回归。
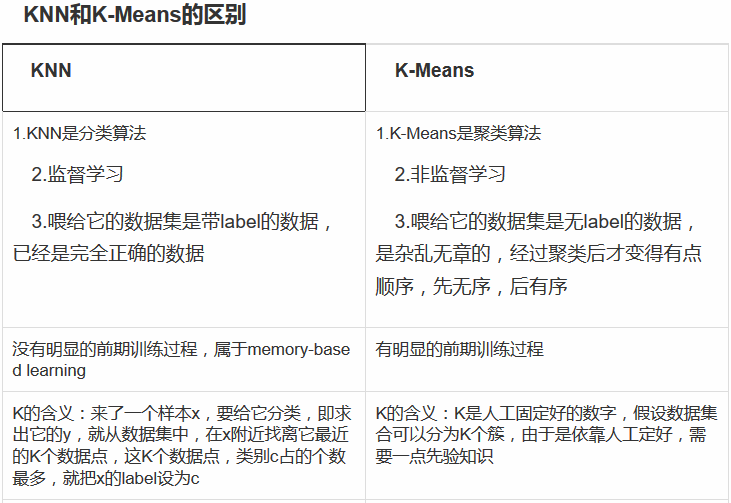
k-NN
k-NN(k近邻法)是一种基本分类和回归方法。
k近邻模型的三个基本要素:距离度量,k值的选择,分类决策规则。常用的距离度量是欧式距离及更一般的Lp距离。k值小时,k近邻模型更复杂;k值大时,k近邻模型更简单。k值的选择反映了对近似误差与估计误差之间的权衡,通常由交叉验证选择最优的k。常用的分类决策规则是多数表决,对应于经验风险最小化。
k近邻模型对应于训练数据集对特征空间的一个划分。k近邻法中,当三个基本要素确定后,其结果唯一确定。
k近邻法的基本做法:
对给定的训练实例点和输入实例点,首先确定输入实例点的k个最近邻训练实例点,然后利用这k个训练实例点的类的多数来预测输入实例的类。
k近邻法的实现需要考虑如何快速搜索k个最近邻点。kd树是一种便于对k维空间中的数据进行快速检索的数据结构。kd树是二叉树,表示对k维空间的一个划分,其每个节点对应于k维空间划分中的一个超矩形区域。利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
K-Means
K-Means算法是一种聚类算法。
以欧式距离作为相似度测度,它是求对应某一初始聚类中心向量V最优分类,使得评价指标J最小。算法采用误差平方和准则函数作为聚类准则函数。
基本思想:从n个对象中任意选择k个对象为中心进行聚类,而对于剩下的其他对象,则根据它们与这些聚类中心(距离均值所对应的对象)的相似度(距离),按照最小距离分别将它们分配给与其最相似的(距离聚类中心所代表的聚类是最小的)聚类,然后再计算每个所获新聚类的聚类中心(该聚类中的中心对象)结果将n个对象划分为k个聚类,且这些聚类满足:同一聚类中的对象相似度较高,不同聚类中的对象相似度较小。
算法流程:
首先从n个数据对象中任意选择k个对象作为初始聚类中心,将剩下的其他对象分别计算它们到这k个聚类中心的距离,归到距离最小的聚类中,每聚一次类,都要重新计算一次聚类中心,规则是将所有对象的距离均值所对应的对象作为聚类中心。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









