文本分类是指将一篇文章归到事先定义好的某一类或者某几类,在数据平台的一个典型的应用场景是,通过爬取用户浏览过的页面内容,识别出用户的浏览偏好,从而丰富该用户的画像。
本文介绍使用Spark MLlib提供的朴素贝叶斯(Naive Bayes)算法,完成对中文文本的分类过程。主要包括中文分词、文本表示(TF-IDF)、模型训练、分类预测等。
中文分词
对于中文文本分类而言,需要先对文章进行分词,我使用的是IKAnalyzer中文分析工具,,其中自己可以配置扩展词库来使分词结果更合理,我从搜狗、百度输入法下载了细胞词库,将其作为扩展词库。这里不再介绍分词。
中文词语特征值转换(TF-IDF)
分好词后,每一个词都作为一个特征,但需要将中文词语转换成Double型来表示,通常使用该词语的TF-IDF值作为特征值,Spark提供了全面的特征抽取及转换的API,非常方便,详见http://spark.apache.org/docs/latest/ml-features.html,这里介绍下TF-IDF的API:
比如,训练语料/tmp/lxw1234/1.txt:
0,苹果 官网 苹果 宣布
1,苹果 梨 香蕉
逗号分隔的第一列为分类编号,0为科技,1为水果。
- case class RawDataRecord(category: String, text: String)
-
- val conf = new SparkConf().setMaster("yarn-client")
- val sc = new SparkContext(conf)
- val sqlContext = new org.apache.spark.sql.SQLContext(sc)
- import sqlContext.implicits._
-
- //将原始数据映射到DataFrame中,字段category为分类编号,字段text为分好的词,以空格分隔
- var srcDF = sc.textFile("/tmp/lxw1234/1.txt").map {
- x =>
- var data = x.split(",")
- RawDataRecord(data(0),data(1))
- }.toDF()
-
- srcDF.select("category", "text").take(2).foreach(println)
- [0,苹果 官网 苹果 宣布]
- [1,苹果 梨 香蕉]
- //将分好的词转换为数组
- var tokenizer = new Tokenizer().setInputCol("text").setOutputCol("words")
- var wordsData = tokenizer.transform(srcDF)
-
- wordsData.select($"category",$"text",$"words").take(2).foreach(println)
- [0,苹果 官网 苹果 宣布,WrappedArray(苹果, 官网, 苹果, 宣布)]
- [1,苹果 梨 香蕉,WrappedArray(苹果, 梨, 香蕉)]
-
- //将每个词转换成Int型,并计算其在文档中的词频(TF)
- var hashingTF =
- new HashingTF().setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(100)
- var featurizedData = hashingTF.transform(wordsData)
-
这里将中文词语转换成INT型的Hashing算法,类似于Bloomfilter,上面的setNumFeatures(100)表示将Hash分桶的数量设置为100个,这个值默认为2的20次方,即1048576,可以根据你的词语数量来调整,一般来说,这个值越大,不同的词被计算为一个Hash值的概率就越小,数据也更准确,但需要消耗更大的内存,和Bloomfilter是一个道理。
- featurizedData.select($"category", $"words", $"rawFeatures").take(2).foreach(println)
- [0,WrappedArray(苹果, 官网, 苹果, 宣布),(100,[23,81,96],[2.0,1.0,1.0])]
- [1,WrappedArray(苹果, 梨, 香蕉),(100,[23,72,92],[1.0,1.0,1.0])]
结果中,“苹果”用23来表示,第一个文档中,词频为2,第二个文档中词频为1.
- //计算TF-IDF值
- var idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
- var idfModel = idf.fit(featurizedData)
- var rescaledData = idfModel.transform(featurizedData)
- rescaledData.select($"category", $"words", $"features").take(2).foreach(println)
-
- [0,WrappedArray(苹果, 官网, 苹果, 宣布),(100,[23,81,96],[0.0,0.4054651081081644,0.4054651081081644])]
- [1,WrappedArray(苹果, 梨, 香蕉),(100,[23,72,92],[0.0,0.4054651081081644,0.4054651081081644])]
-
- //因为一共只有两个文档,且都出现了“苹果”,因此该词的TF-IDF值为0.
-
最后一步,将上面的数据转换成Bayes算法需要的格式,如:
https://github.com/apache/spark/blob/branch-1.5/data/mllib/sample_naive_bayes_data.txt
- var trainDataRdd = rescaledData.select($"category",$"features").map {
- case Row(label: String, features: Vector) =>
- LabeledPoint(label.toDouble, Vectors.dense(features.toArray))
- }

每一个LabeledPoint中,特征数组的长度为100(setNumFeatures(100)),”官网”和”宣布”对应的特征索引号分别为81和96,因此,在特征数组中,第81位和第96位分别为它们的TF-IDF值。
到此,中文词语特征表示的工作已经完成,trainDataRdd已经可以作为Bayes算法的输入了。
分类模型训练
训练模型,语料非常重要,我这里使用的是搜狗提供的分类语料库,很早之前的了,这里只作为学习测试使用。
下载地址在:http://www.sogou.com/labs/dl/c.html,语料库一共有10个分类:
C000007 汽车
C000008 财经
C000010 IT
C000013 健康
C000014 体育
C000016 旅游
C000020 教育
C000022 招聘
C000023 文化
C000024 军事
每个分类下有几千个文档,这里将这些语料进行分词,然后每一个分类生成一个文件,在该文件中,每一行数据表示一个文档的分词结果,重新用0-9作为这10个分类的编号:
0 汽车
1 财经
2 IT
3 健康
4 体育
5 旅游
6 教育
7 招聘
8 文化
9 军事
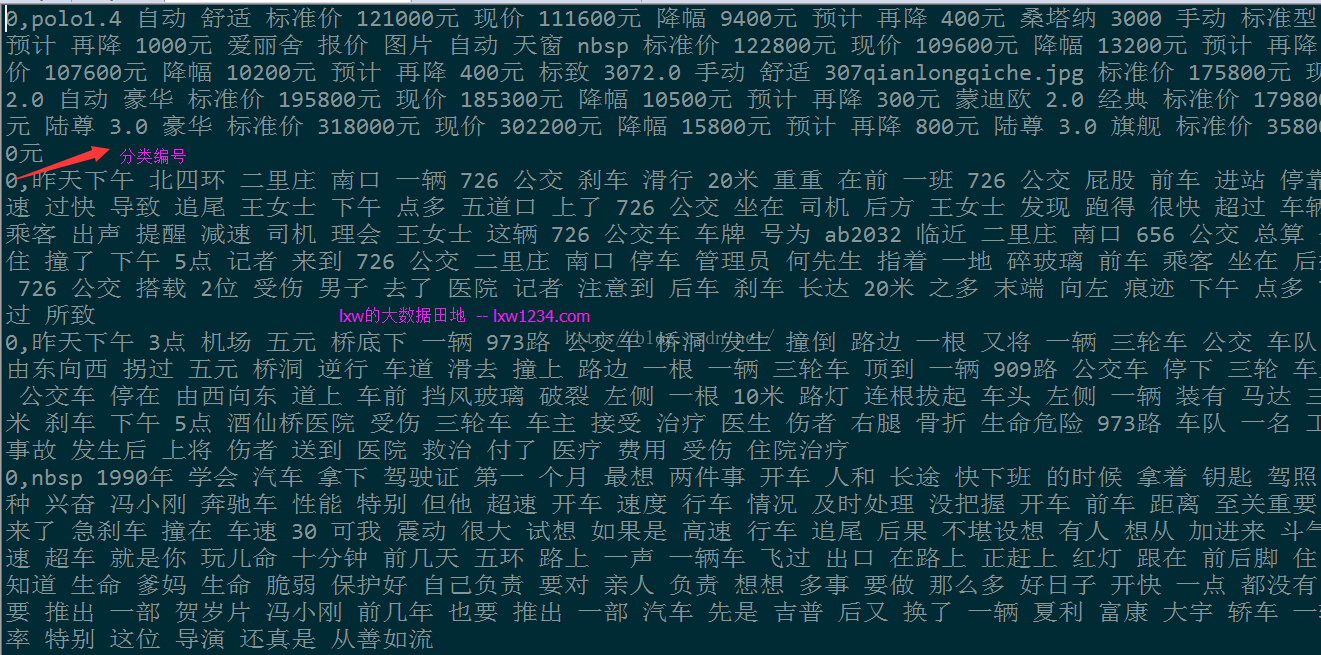
比如,汽车分类下的文件内容为:
数据准备好了,接下来进行模型训练及分类预测,代码:
- package com.lxw1234.textclassification
-
- import scala.reflect.runtime.universe
-
- import org.apache.spark.SparkConf
- import org.apache.spark.SparkContext
- import org.apache.spark.ml.feature.HashingTF
- import org.apache.spark.ml.feature.IDF
- import org.apache.spark.ml.feature.Tokenizer
- import org.apache.spark.mllib.classification.NaiveBayes
- import org.apache.spark.mllib.linalg.Vector
- import org.apache.spark.mllib.linalg.Vectors
- import org.apache.spark.mllib.regression.LabeledPoint
- import org.apache.spark.sql.Row
-
-
- object TestNaiveBayes {
-
- case class RawDataRecord(category: String, text: String)
-
- def main(args : Array[String]) {
-
- val conf = new SparkConf().setMaster("yarn-client")
- val sc = new SparkContext(conf)
-
- val sqlContext = new org.apache.spark.sql.SQLContext(sc)
- import sqlContext.implicits._
-
- var srcRDD = sc.textFile("/tmp/lxw1234/sougou/").map {
- x =>
- var data = x.split(",")
- RawDataRecord(data(0),data(1))
- }
-
- //70%作为训练数据,30%作为测试数据
- val splits = srcRDD.randomSplit(Array(0.7, 0.3))
- var trainingDF = splits(0).toDF()
- var testDF = splits(1).toDF()
-
- //将词语转换成数组
- var tokenizer = new Tokenizer().setInputCol("text").setOutputCol("words")
- var wordsData = tokenizer.transform(trainingDF)
- println("output1:")
- wordsData.select($"category",$"text",$"words").take(1)
-
- //计算每个词在文档中的词频
- var hashingTF = new HashingTF().setNumFeatures(500000).setInputCol("words").setOutputCol("rawFeatures")
- var featurizedData = hashingTF.transform(wordsData)
- println("output2:")
- featurizedData.select($"category", $"words", $"rawFeatures").take(1)
-
-
- //计算每个词的TF-IDF
- var idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
- var idfModel = idf.fit(featurizedData)
- var rescaledData = idfModel.transform(featurizedData)
- println("output3:")
- rescaledData.select($"category", $"features").take(1)
-
- //转换成Bayes的输入格式
- var trainDataRdd = rescaledData.select($"category",$"features").map {
- case Row(label: String, features: Vector) =>
- LabeledPoint(label.toDouble, Vectors.dense(features.toArray))
- }
- println("output4:")
- trainDataRdd.take(1)
-
- //训练模型
- val model = NaiveBayes.train(trainDataRdd, lambda = 1.0, modelType = "multinomial")
-
- //测试数据集,做同样的特征表示及格式转换
- var testwordsData = tokenizer.transform(testDF)
- var testfeaturizedData = hashingTF.transform(testwordsData)
- var testrescaledData = idfModel.transform(testfeaturizedData)
- var testDataRdd = testrescaledData.select($"category",$"features").map {
- case Row(label: String, features: Vector) =>
- LabeledPoint(label.toDouble, Vectors.dense(features.toArray))
- }
-
- //对测试数据集使用训练模型进行分类预测
- val testpredictionAndLabel = testDataRdd.map(p => (model.predict(p.features), p.label))
-
- //统计分类准确率
- var testaccuracy = 1.0 * testpredictionAndLabel.filter(x => x._1 == x._2).count() / testDataRdd.count()
- println("output5:")
- println(testaccuracy)
-
- }
- }
执行后,主要输出如下:
output1:(将词语转换成数组)
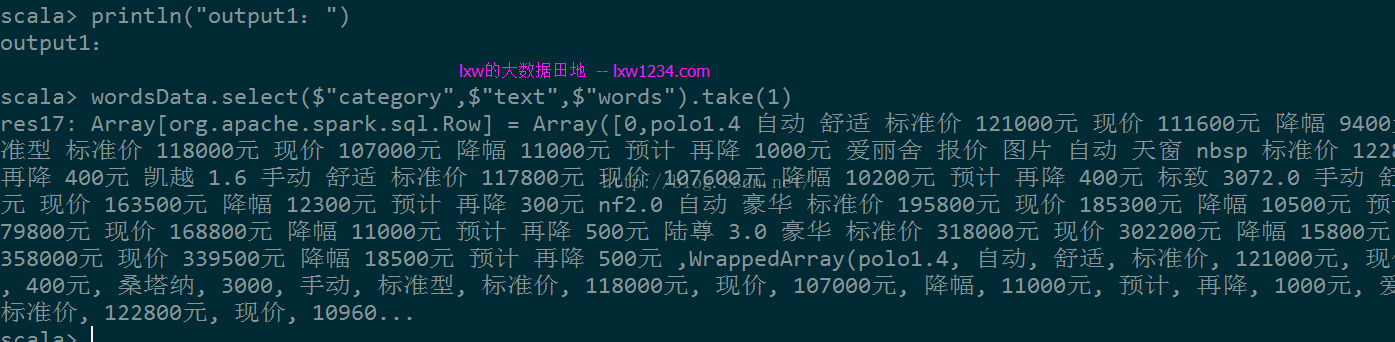
output2:(计算每个词在文档中的词频)
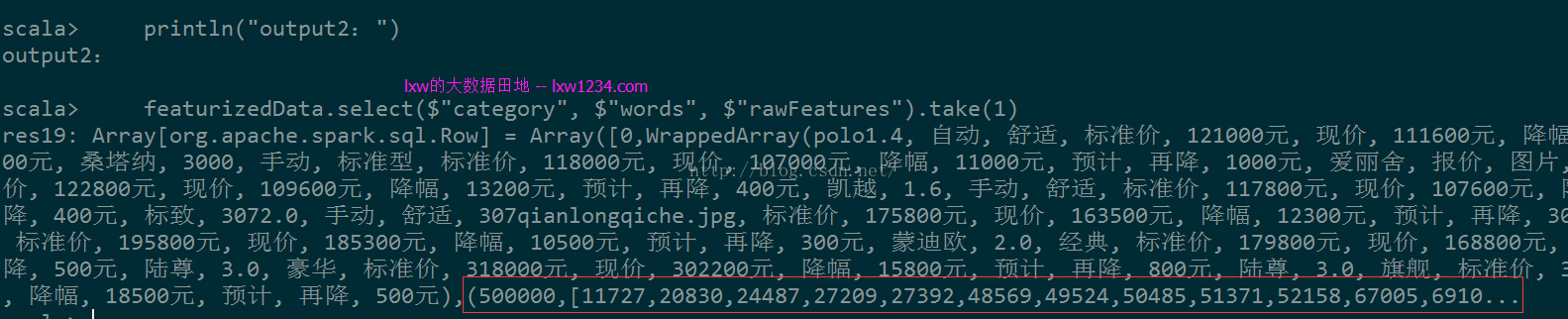
output3:(计算每个词的TF-IDF)

output4:(Bayes算法的输入数据格式)

output5:(测试数据集分类准确率)
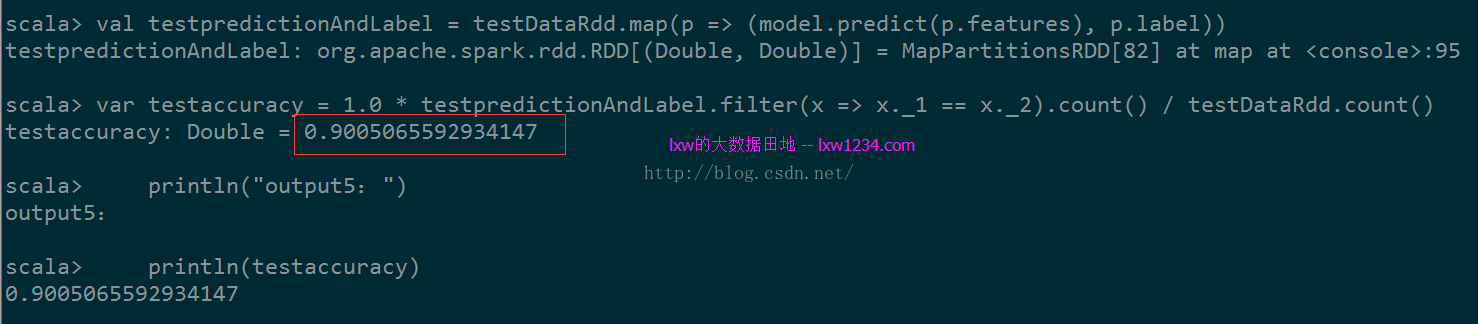
准确率90%,还可以。接下来需要收集分类更细,时间更新的数据来训练和测试了。。
更新:
程序中使用的/tmp/lxw1234/sougou/目录下的文件提供下载:
链接: http://pan.baidu.com/s/1ntUyI9N 密码: i5nj
转载请注明:lxw的大数据田地 » Spark MLlib实现的中文文本分类–Naive Bayes






















 1592
1592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









