









众所周知,linux系统中,进程的创建一般由fork( )或者exec( )来实现。然而,理解fork( )背后所做的工作是很有必要的,有助于我们更好地理解进程之间的通信。在此之前,我们先来介绍几种关于进程的结构。
一、任务结构与进程描述符
首先,内核中有一个包括所有进程的列表,叫做任务队列。它是一个双向循环链表,链表中的每一项类型都是task_struct,称为进程描述符的结构。(定义在内核<linux/sched.h>中)
进程描述符所包含的信息有:
① 标识符:唯一,用来区分进程。
② 状态:运行态等;
③ 优先级;
④ 程序计数器:下一条指令的地址;
⑤ 内存指针;
⑥ 上下文数据:程序运行时寄存器中的数据;
⑦ I/O状态信息:包括显式的I/O请求、分配给进程的设备等等;
⑧ 记账信息;
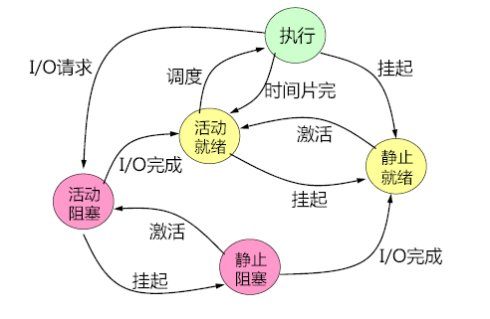
二、进程的状态
进程在运行的过程中会有多次状态切换,总的来说有5种状态:
运行态:进程正在执行;
就绪态:进程准备执行;
阻塞/等待态:进程在某些事件发生之前不能执行;
新建态:刚刚创建,还没执行;(没加载到内存中)
退出态:准备退出,释放内存;
三、回到fork( )
首先,fork( )通过拷贝当前进程来创建一个子进程(写时拷贝技术,后面会介绍)。父子进程的区别仅仅是PID、PPID、以及一些统计量不同而已。exec()函数负责读取可执行文件并将其载入到地址空间开始运行。所以,fork()会返回两次,返回到父进程时返回值等于0,返回到子进程时返回值小于0,编程的时候正是通过返回值来区分父子进程。
接下来介绍写时拷贝。传统的fork()直接把所有的资源复制给子进程,这样过于简单且效率低下,并且拷贝的数据也许不共享。更糟的是,如果子进程打算立即执行一个新的映像(exec),所有的拷贝将前功尽弃。所有,现在的fork( )用写时拷贝来实现。宗旨就是推迟甚至免除拷贝数据。最开始,内核并不复制整个进程地址空间,而是让父子进程共享一个拷贝,在写入之前,以自读的方式共享。当需要写入的时候,数据才会被复制,从而各个进程拥有各自的拷贝。这样使得linux有了进程快速执行的能力,也是最大的优点。
fork()接下来的工作就好理解了。
1、为新进程分配相关资源,如内核栈,进程描述符等。此时的子进程和父进程的描述符是完全相同的。
2、检查进程总数是否超过系统上限。(对于普通用户一般不会)
3、将子进程与父进程区分开来。进程描述符内很多数据将被清0或者改变。
4、将子进程设置为不可中断型,保证它不会投入运行。
5、为新进程分配有效的PID。
6、拷贝或者共享打开的文件,文件系统信息、信号处理函数等等。
值得注意的是,内核会有意让子进程先执行,因为一般子进程会马上调用exec()函数,这样可以避免写时拷贝的额外开销。否则,如果父进程先执行并且写入数据,可能会做一次无用的写时拷贝。
四、线程在linux中的实现
为什么有了进程,还要创建线程机制呢?因为有时候一个进程还是太大了,linux是抢占式的,将一个进程分成多个线程来执行能提高效率。线程机制支持并发程序设计,可以真正的并行处理。
对linux内核来说,并没有线程这个概念。它会把线程当做进程来实现,线程仅仅被视作一个与其他进程共享资源的进程。不过,创建的线程会与父进程共享地址空间、文件系统资源、文件描述符、信号处理程序。
不得不提到一种特殊的线程——内核线程。内核进程需要后再执行一些操作,就由内核线程来完成。它和普通进程的区别在于内核线程没有独立的地址空间。它只在内核空间运行,从不切换到用户空间。不过,他也可以被调度,被抢占。
五、进程的终止与孤儿进程
进程总是要终止的,所有的进程在终止时都会调用do_exit( )来完成终止的一部分操作。(注意只是一部分)执行完do_exit()之后,进程会进入僵死状态,等待父进程来收尾(waitpid)。此时,系统会保留它的进程描述符。这样使得系统可以在子进程终止后仍然能获得它的信息。所以,清理工作和进程描述符的删除是分开进行的。在父进程获得子进程的信息之后,或者通知内核它并不关注那些信息后,子进程的进程描述符才会被释放。
接下来问题就来了,如果父进程在子进程之前就终止了呢?linux给出的解决办法是,给子进程在当前线程组找一个线程当做父亲,如果不行,就把init()当做他的父亲。这样就避免了孤儿进程的僵死状况。














 553
553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









