







激活层定义
typedef enum{
LOGISTIC, RELU, RELIE, LINEAR, RAMP, TANH, PLSE, LEAKY, ELU, LOGGY
}ACTIVATION;
大家一开始看这些激活函数看起来很奇怪,下面我们会给出这几个类型的表达式CPU 端的代码
激活函数对应的代码:
static inline float linear_activate(float x){return x;}
static inline float logistic_activate(float x){return 1./(1. + exp(-x));}
static inline float loggy_activate(float x){return 2./(1. + exp(-x)) - 1;}
static inline float relu_activate(float x){return x*(x>0);}
static inline float elu_activate(float x){return (x >= 0)*x + (x < 0)*(exp(x)-1);}
static inline float relie_activate(float x){return x*(x>0);}
static inline float ramp_activate(float x){return x*(x>0)+.1*x;}
static inline float leaky_activate(float x){return (x>0) ? x : .1*x;}
static inline float tanh_activate(float x){return (exp(2*x)-1)/(exp(2*x)+1);}
static inline float plse_activate(float x)
{
if(x < -4) return .01 * (x + 4);
if(x > 4) return .01 * (x - 4) + 1;
return .125*x + .5;
}
激活函数的导数:
static inline float linear_gradient(float x){return 1;}
static inline float logistic_gradient(float x){return (1-x)*x;}
static inline float loggy_gradient(float x)
{
float y = (x+1.)/2.;
return 2*(1-y)*y;
}
static inline float relu_gradient(float x){return (x>0);}
static inline float elu_gradient(float x){return (x >= 0) + (x < 0)*(x + 1);}
static inline float relie_gradient(float x){return (x>0) ? 1 : .01;}
static inline float ramp_gradient(float x){return (x>0)+.1;}
static inline float leaky_gradient(float x){return (x>0) ? 1 : .1;}
static inline float tanh_gradient(float x){return 1-x*x;}
static inline float plse_gradient(float x){return (x < 0 || x > 1) ? .01 : .125;}GPU端的代码
// __device__ 该函数在器件里调用,在器件中执行
// __global__ 该函数在主机里调用,在器件中执行
// __host__ 该函数在主机中调用,在主机中执行
激活函数对应的代码:
__device__ float linear_activate_kernel(float x){return x;}
__device__ float logistic_activate_kernel(float x){return 1./(1. + exp(-x));}
__device__ float loggy_activate_kernel(float x){return 2./(1. + exp(-x)) - 1;}
__device__ float relu_activate_kernel(float x){return x*(x>0);}
__device__ float elu_activate_kernel(float x){return (x >= 0)*x + (x < 0)*(exp(x)-1);}
__device__ float relie_activate_kernel(float x){return x*(x>0);}
__device__ float ramp_activate_kernel(float x){return x*(x>0)+.1*x;}
__device__ float leaky_activate_kernel(float x){return (x>0) ? x : .1*x;}
__device__ float tanh_activate_kernel(float x){return (exp(2*x)-1)/(exp(2*x)+1);}
__device__ float plse_activate_kernel(float x)
{
if(x < -4) return .01 * (x + 4);
if(x > 4) return .01 * (x - 4) + 1;
return .125*x + .5;
}
激活函数的导数:
__device__ float linear_gradient_kernel(float x){return 1;}
__device__ float logistic_gradient_kernel(float x){return (1-x)*x;}
__device__ float loggy_gradient_kernel(float x)
{
float y = (x+1.)/2.;
return 2*(1-y)*y;
}
__device__ float relu_gradient_kernel(float x){return (x>0);}
__device__ float elu_gradient_kernel(float x){return (x >= 0) + (x < 0)*(x + 1);}
__device__ float relie_gradient_kernel(float x){return (x>0) ? 1 : .01;}
__device__ float ramp_gradient_kernel(float x){return (x>0)+.1;}
__device__ float leaky_gradient_kernel(float x){return (x>0) ? 1 : .1;}
__device__ float tanh_gradient_kernel(float x){return 1-x*x;}
__device__ float plse_gradient_kernel(float x){return (x < 0 || x > 1) ? .01 : .125;}
__device__ float activate_kernel(float x, ACTIVATION a)
{
switch(a){
case LINEAR:
return linear_activate_kernel(x);
case LOGISTIC:
return logistic_activate_kernel(x);
case LOGGY:
return loggy_activate_kernel(x);
case RELU:
return relu_activate_kernel(x);
case ELU:
return elu_activate_kernel(x);
case RELIE:
return relie_activate_kernel(x);
case RAMP:
return ramp_activate_kernel(x);
case LEAKY:
return leaky_activate_kernel(x);
case TANH:
return tanh_activate_kernel(x);
case PLSE:
return plse_activate_kernel(x);
}
return 0;
}
__device__ float gradient_kernel(float x, ACTIVATION a)
{
switch(a){
case LINEAR:
return linear_gradient_kernel(x);
case LOGISTIC:
return logistic_gradient_kernel(x);
case LOGGY:
return loggy_gradient_kernel(x);
case RELU:
return relu_gradient_kernel(x);
case ELU:
return elu_gradient_kernel(x);
case RELIE:
return relie_gradient_kernel(x);
case RAMP:
return ramp_gradient_kernel(x);
case LEAKY:
return leaky_gradient_kernel(x);
case TANH:
return tanh_gradient_kernel(x);
case PLSE:
return plse_gradient_kernel(x);
}
return 0;
}
__global__ void activate_array_kernel(float *x, int n, ACTIVATION a)
{
//这个的计算可以参照下面的示意图,因为每个block的维度是一维的,因此只需要使用threadIdx.x。
int i = (blockIdx.x + blockIdx.y*gridDim.x) * blockDim.x + threadIdx.x;
if(i < n) x[i] = activate_kernel(x[i], a);
}
__global__ void gradient_array_kernel(float *x, int n, ACTIVATION a, float *delta)
{
int i = (blockIdx.x + blockIdx.y*gridDim.x) * blockDim.x + threadIdx.x;
if(i < n) delta[i] *= gradient_kernel(x[i], a);
}
//extern "C"表明了一种编译规约,其中extern是关键字属性,“C”表征了编译器链接规范。对于extern "C"可以理解成在C++/C中的混合编程的编译指令。
extern "C" void activate_array_ongpu(float *x, int n, ACTIVATION a)
{
activate_array_kernel<<<cuda_gridsize(n), BLOCK>>>(x, n, a);
check_error(cudaPeekAtLastError());
}
extern "C" void gradient_array_ongpu(float *x, int n, ACTIVATION a, float *delta)
{
gradient_array_kernel<<<cuda_gridsize(n), BLOCK>>>(x, n, a, delta);
check_error(cudaPeekAtLastError());
}
//这个地方已经定义了BLOCK的大小为512,这个函数的功能是使得设置网格的维度,要求是x的大小不超过65535,返回网格的大小。网格的示意图如下图。
dim3 cuda_gridsize(size_t n){
size_t k = (n-1) / BLOCK + 1;
size_t x = k;
size_t y = 1;
if(x > 65535){
x = ceil(sqrt(k));
y = (n-1)/(x*BLOCK) + 1;
}
dim3 d = {x, y, 1};
return d;
}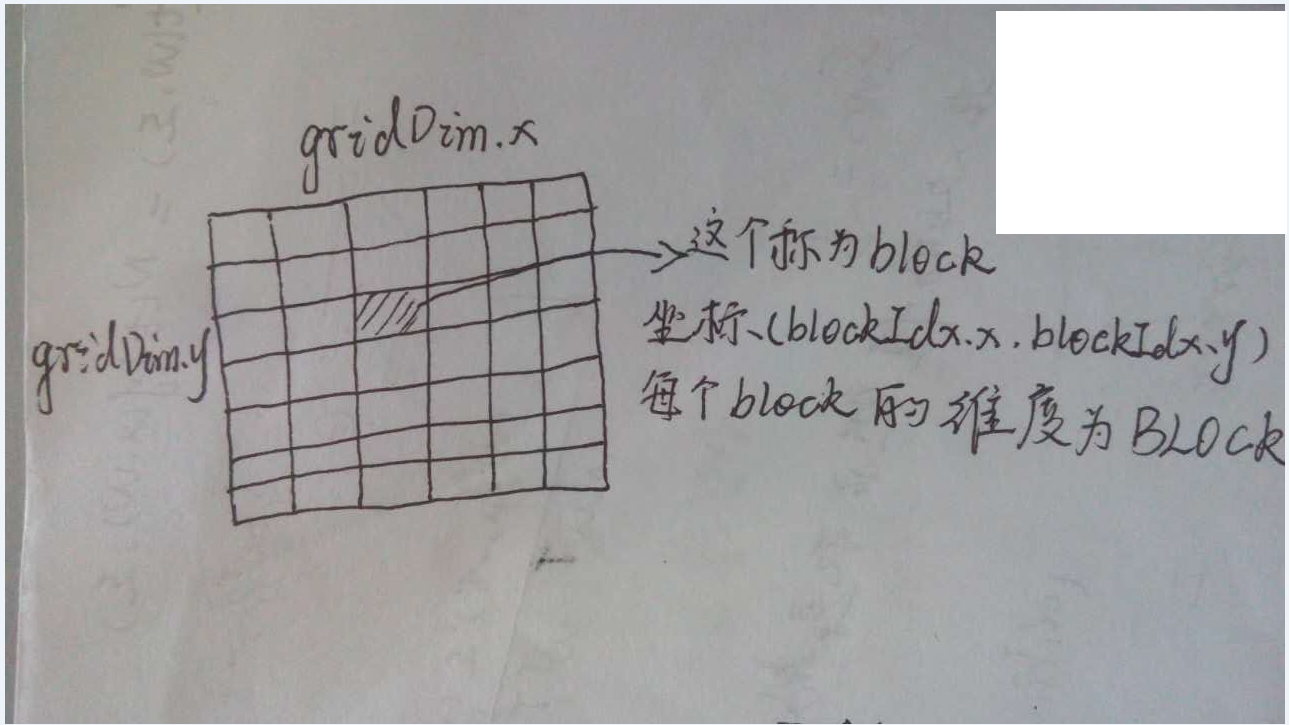
对于给定的线程的坐标为(blockIdx.x,blockIdx.y,threadIdx.x,threadIdx.y)
对应的线程标号为(blockIdx.y*gridDim.x + blockIdx.x)*BlockDim.x*BlockDim.y + (threadIdx.y*BlockDim.x + threadIdx.y)
对应于这个程序代码里面 ,BlockDim.x = BLOCK , BlockDim.y = 1, threadIdx.y = 0
对应的线程标号为 (blockIdx.y*gridDim.x + blockIdx.x)*BlockDim.x* + threadIdx.yLOGISTIC 的表达式
y=1.01.0+e−x
dydx=1
RELU 的表达式
y={x0 if x>0 if x≤0
RELIE 的表达式
y={x0if x>0if x≤0
dydx={10if x>0if x≤0
LINEAR 的表达式
y=x
dydx=1
RAMP 的表达式
y={x+0.1x0.1xif x>0if x≤0
dydx={1+0.10.1if x>0if x≤0
TANH 的表达式
y=e2x−1e2x+1
dydx=1−x2
PLSE 的表达式
y=⎧⎩⎨0.01(x+4)0.01(x−4)0.125x+0.5if x<−4if x>4if x=4
dydx={0.010.125if x<0∥x>1if x=4
LEAKY 的表达式
y={x0.1xif x>0if x≤0
dydx={10.1if x>0if x≤0
ELU 的表达式
y={xex−1if x≥0if x<0
dydx={1x+1if x≥0if x<0
LOGGY 的表达式
y=2.01.0+e−x−1=1.0−e−x1.0+e−x
dydx=21−x1+x














 1435
1435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









