







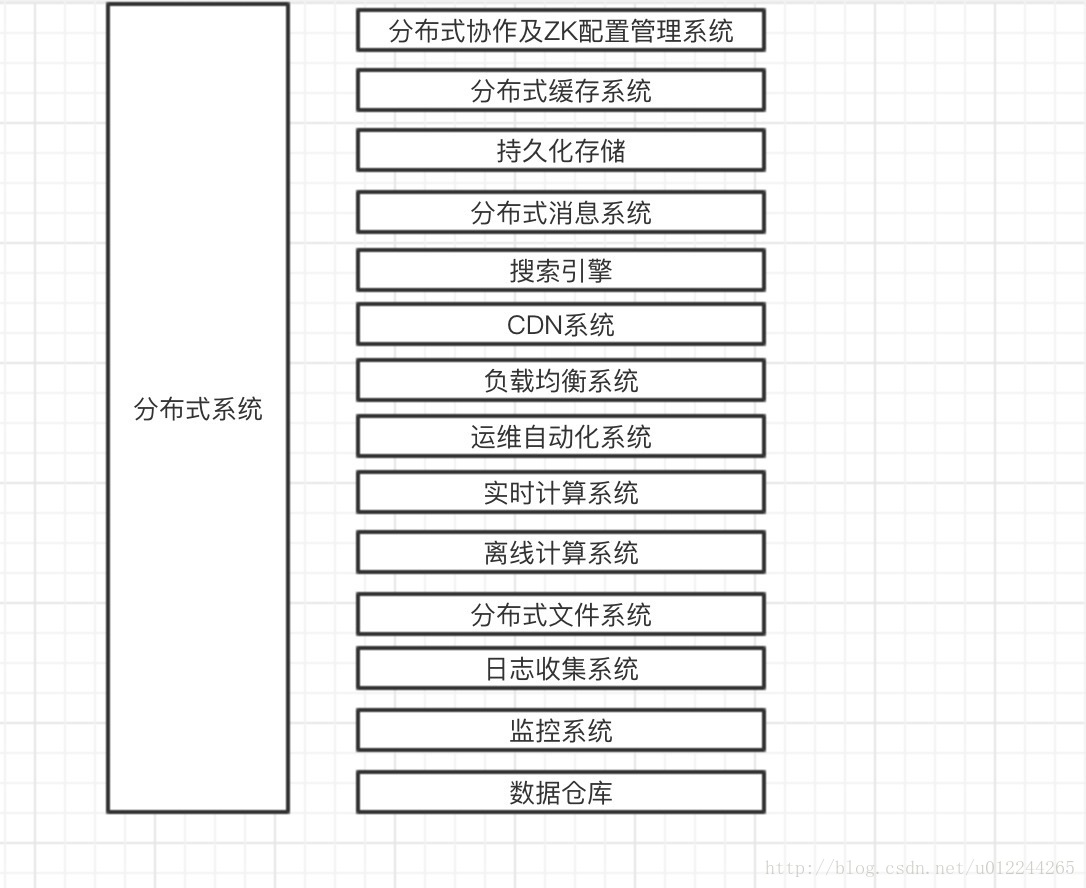
一个大型,稳健,成熟的分布式系统背后,是由很多系统共同支撑的,我们将这些支撑系统成为分布式系统的基础设施。
HBase
关于上篇文章提到的海量数据,如果采用分库分表进行管理和查询会存在局限性,于是我们可以引入一种新的数据存储方式,即HBase。HBase是Apache Hadoop项目下的子项目,它以Google BigTable为原型,设计实现的列存储数据库,本质上是一张稀疏的大表。
- 明确几个概念
Hive:
Hive不支持更改数据的操作,Hive基于数据仓库,提供静态数据的动态查询。其使用类SQL语言,底层经过编译转为MapReduce程序,在Hadoop上运行,数据存储在HDFS上。
HDFS:
HDFS是GFS的一种实现,他的完整名字是分布式文件系统,类似于FAT32,NTFS,是一种文件格式,是底层的。
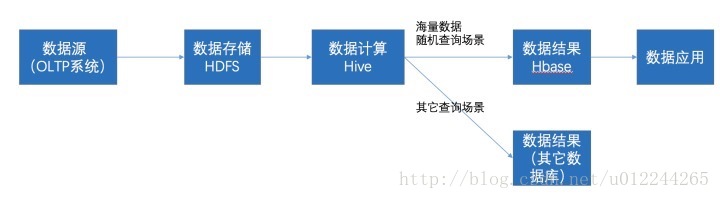
Hive与Hbase的数据一般都存储在HDFS上。Hadoop HDFS为他们提供了高可靠性的底层存储支持。
HBase:
Hbase是Hadoop database,即Hadoop数据库。它是一个适合于非结构化数据存储的数据库,HBase基于列的而不是基于行的模式。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据。
Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。
以上是目前大数据用到的几个概念,值得说明的是大数据之所以存在主要是还是解决海量数据在利用开源数据库比如Mysql等带来的存储和查询问题,如果业务的数据量达不到海量级别,用到大数据的地方比较少。
再仔细讨论下这几个的关系:
Hive 定义一张表来描述HDFS上的结构化文本,包括各列数据名称,数据类型是什么,基于这个层面上,通过SQL来处理和计算HDFS的数据,Hive会将SQL翻译为Mapreduce来处理数据,其对应的底层存储是HDFS。作为批处理系统,Hive不支持实时查询。HBase是非结构化数据库,本身存储为一张稀疏的大表,支持近实时系统。一般而言这两者可以一起工作。
基本应用
现在我们对HBase有了一个初步的了解,接下来看看如何用shell指令操作HBase。
进入命令行
hbase shell
创建一张表(如: 电影用户表)
create ‘表名称’,’列簇名称1’,…,’列簇名称n’
create ‘movieuser’,’review’,’useraction’
添加一条记录
put ‘表名’,’行键名’,’列名’,’单元值’,’时间戳’(可省略)
put ‘movieuser’,’2333180809’,’review:score’,’5’
put ‘movieuser’,’2333180809’,’review:content’,’好看’
全表扫描
scan ‘scores’
查询某条记录
get ‘movieuser’,’2333180809’,’review:score’
COLUMN CELL
review:score timestamp=1435491529683, value=10
review:score timestamp=1435491508206, value=9
2 row(s) in 0.0520 seconds
查询多个版本
get ‘movieuser’,’2333180809’,{COLUMN=>’review:score’,VERSION=>2}
查询行数
count ‘movieuser’
修改表结构
alter ‘movieuser’,NAME=>’desc’ (增加列簇)
alter ‘movieuser’,NAME=>’desc’,METHOD=>’delete’
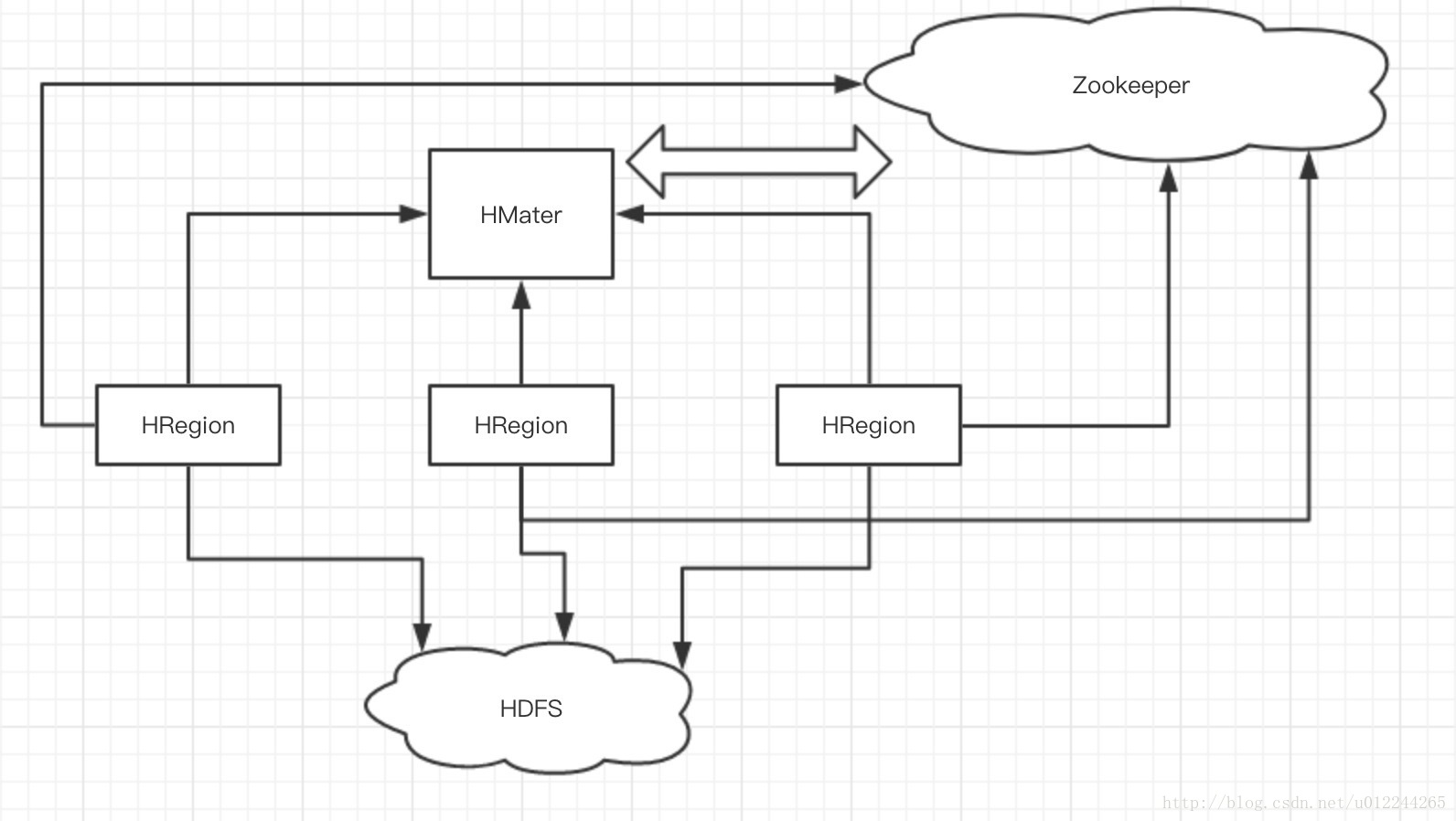
HBase集群部署
整个集群机器的管理一般还是采用ZooKeeper统一管理,在Hbase集群又包含两种角色,HMaster和HRegionServer,随着表记录条数的增加而不断变大之后,将分裂成一个个Region,每个Region可以由startkey,endkey来表示,包含一个startkey到endkey半区间。一个HRegionServer可以管理多个Region,并由HMaster来负责HRegionServer的调度和集群状态的监督。如图
HBase应用场景
rowkey设计
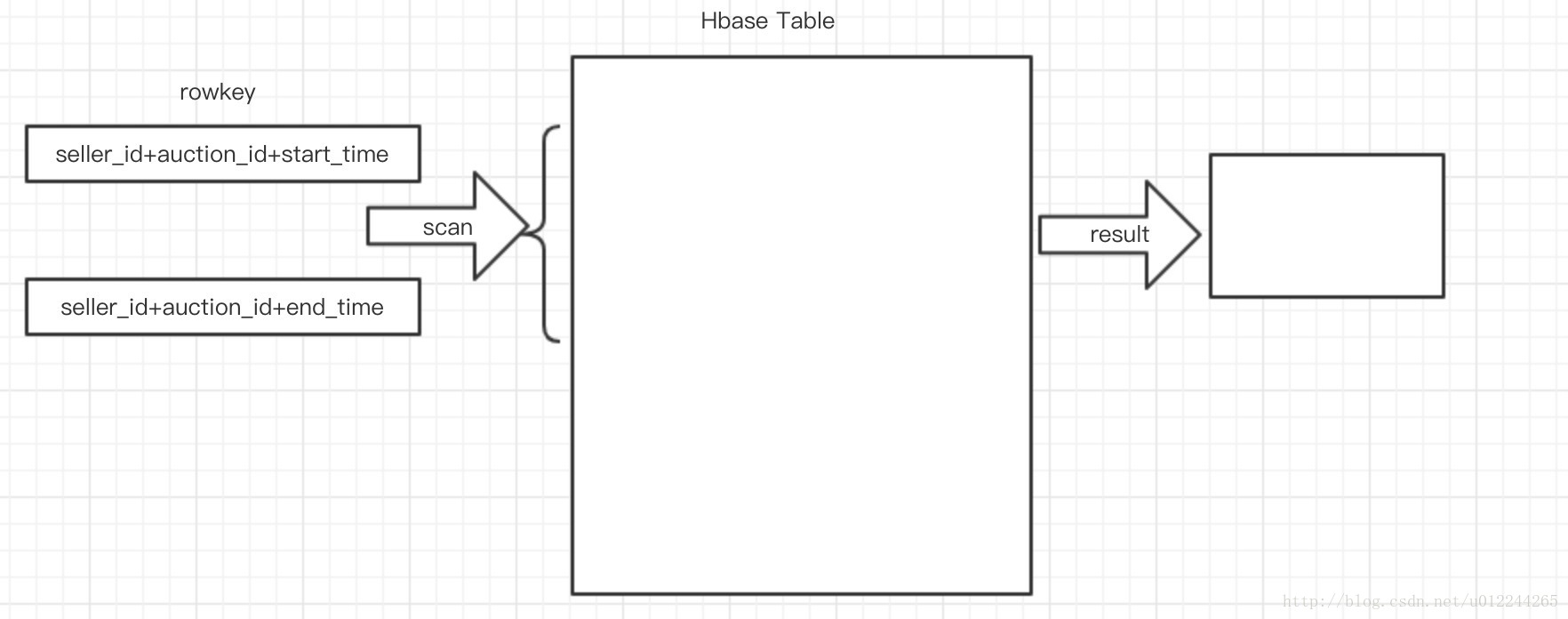
如果想要访问HBase的行,只有三种方式,一种是通过制定的rowkey进行访问,一种是rowkey的range进行scan,再者就是全表扫描。假如使用HBase来存储用户的订单信息,通过这几个维度来记录,比如买家uid,交易时间,商品id,商品名称,交易金额,卖家id。
如果从卖家维度来查看某商品已经售出的订单,并且按照下单时间进行查询
rowkey可以设计为
卖家id + 商品id + 创建时间
seller_id+auction_id+create_time
列簇设计为
order_info(auction_price,title,create_time)
如图
加入从买家角度来进行时间范围内订单查询呢,买家想要查看购买的商品列表
rowkey可以设计为
user_id + create_time
列簇设计为
order_info(auction_id,auction_title,price,seller_id)
同传统的关系型数据库相比,HBase比较适合海量的数据存储和处理,由于多个Region Server的存在,使得HBase能够多个节点同时写入,提高了写入性能。但是局限性在于查询维度有限,难以支持复杂查询,比如group by order by join等。这方面可以通过搜索引擎技术来构建索引。
Redis
Redis是一个高性能的key-value数据库,与其他key-value数据库不同的是数据库的不同之处在于,Redis不仅支持简单的键值对存储,还支持一系列丰富的数据存储结构,包括strings,hashs,lists,sets,sorted,sets等。
Redis API:
redis.set(“name”,”jack”);
redis.setex(“content”,5,”hello”);
redis.mset(“class”,”a”,”age”,”23”); // 多个key-value
redis.append(“content”,”lucky”);
redis.get(“content”);
redis.mget(“class”,”age”); // 一次取多个key-value
hashs
redis.hset(“url”,”google”,”www.google.com”); // 存储map
map.put(“name”,”jack”);
map.put(“age”,5);
redis.hmset(“userInfo”,map); // 批量设置
redis.hmget(“url”,”google”,”weibo”): //批量get
//获取所有键值
lists 链表结构,主要是对元素的push和pop,以及获取某个范围内的值。
redis.lpush(“charlist”,”abc”);
redis.lpush(“charlist”,”def”);
redis.rpush(“charlist”,”hij”);
redis.rpush(“charlist”,”klm”);
Listcharlist = redis.lrange(“charlist”,0,2);
redis.lpop(“charlist”); // 在list首部删除元素
redis.rpop(“charlist”); // 在list
long charlistSize = redis.llen(“charlist”);
sets
redis.sadd(“setMem”,”s1”);
redis.sadd(“setMem”,”s2”);
redis.srem(“setMem”,”s1”); //移除
redis.smembers(“setMem”); // 获取所有元素
sorted sets 排序sorts
redis.zadd(“SortSetMem”,1,”5th”);
redis.zadd(“SortSetMem”,2,”4th”);
score = redis.zscore(“SortSetMem”,”4th”);
Setsortset = redis.zrange(“SortSetMem”,2,4);
Setrevsortset = redis.zrevrange(“SortSetMem”,1,2);
相比较于传统的关系型数据库,Redis有更好的读写能力,支持更好的并发数,先比较于其他的key-value数据库,Redis能提供更为丰富的数据类型支持业务需求。Redis能高效率地实现诸如topN,访问计数器,队列系统,数据排查等业务。同时也可提供高性能的缓存服务。














 387
387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









