







朴素贝叶斯分类算法:
优点:在数据较少的情况下仍然有效,可以处理多分类问题。
缺点:对于输入数据的准备方式较为敏感。
适用数据类型:标称型数据(离散型数据)
算法原理:
对于某一个条件,这个条件下哪个类的个数最多,这个情况就可能是这个类的。其实就是max{P(y1|X),P(y2|X)...P(yn|X)},X是条件(属性),y是类。
ps:是不是感觉有点像k-近邻算法的概率表达形式,另外肯定有人会问朴素贝叶斯中的'朴素是什么意思',朴素要表达的意思就是其假设了各个特征之间是独立的。特征独立的好处是可以大大降低需要训练的特征样本数。
算法流程:
收集数据:即建立训练测试数据集。
准备数据:数据类型最好是转化成数值型或者布尔类型数据
分析数据:有大量数据特征是,由于是概率表示的原因绘制特征作用不大,用直方图表示效果更好
训练算法:计算不同的独立特征的条件概率
测试算法:即求出误差率
使用算法:朴素贝叶斯比较常用的分类场景是文档分类
说道贝叶斯公式,我们要先了解条件概率公司:
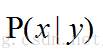
这个公式的意思就是在y事件成立是x事件发生的概率是多少。
下面我们就可以看看贝叶斯公式:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









