







Scrapy 是使用Python编写的一个用来爬取网站数据,提取结构性数据的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。如果不熟悉可以在以下网站学习其基础知识。http://scrapy-chs.readthedocs.org/zh_CN/latest/intro/overview.html
使用Scrapy编写爬虫能大大提高工作效率。在安装好Scrapy之后我们可以在命令行中输入如:scrapy startproject bbs创建一个爬虫项目,在项目中会自动生成如下所示的一些文件。
bbs/
scrapy.cfg
bbs/
init.py
items.py
pipelines.py
settings.py
spiders/
init.py
结合这些生成的文件我们编写一个简单的bbs爬虫主要可以分为3个步骤:1、定义我们需要爬取的数据,这部分主要在items.py中实现。
Item 是保存爬取到的数据的容器;其使用方法和python字典类似, 并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。
如图所示我们要抓取论坛中的:论坛名称、今日登陆人数、帖子、会员、新会员、今日格言等数据。
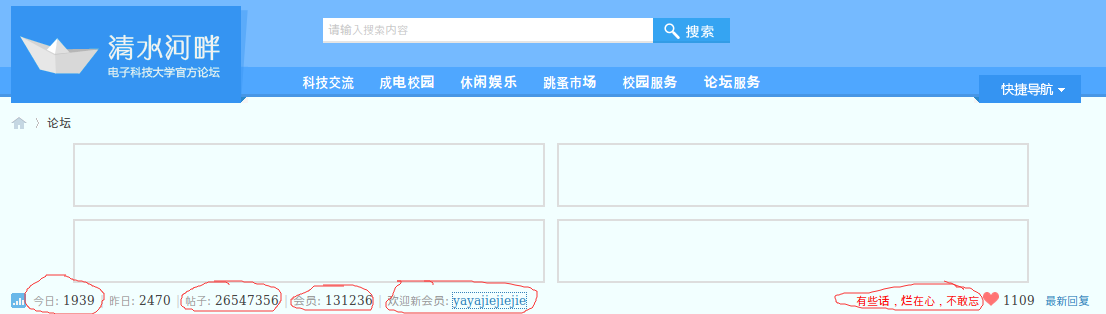
所以items.py代码如下:
import scrapy
class BbsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name=scrapy.Field()
today=scrapy.Field()
posting=scrapy.Field()
member=scrapy.Field()
vanfan_geyan=scrapy.Field()
newmember=scrapy.Field()2、编写自己的Spider
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。对spider来说,爬取的循环类似下文:以初始的URL初始化Request,并设置回调函数。 当该request下载完毕并返回时,将生成response,并作为参数传给该回调函数。spider中初始的request是通过调用 start_requests() 来获取的。 start_requests() 读取 start_urls 中的URL, 并以 parse 为回调函数生成 Request 。在回调函数内分析返回的(网页)内容,返回 Item 对象或者 Request 或者一个包括二者的可迭代容器。 返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的callback函数(函数可相同)。在回调函数内,您可以使用 选择器(Selectors) (您也可以使用BeautifulSoup, lxml 或者您想用的任何解析器) 来分析网页内容,并根据分析的数据生成item。最后,由spider返回的item将被存到数据库(由某些 Item Pipeline 处理)或使用 Feed exports 存入到文件中。虽然该循环对任何类型的spider都(多少)适用,但Scrapy仍然为了不同的需求提供了多种默认spider。 之后将讨论这些spider。
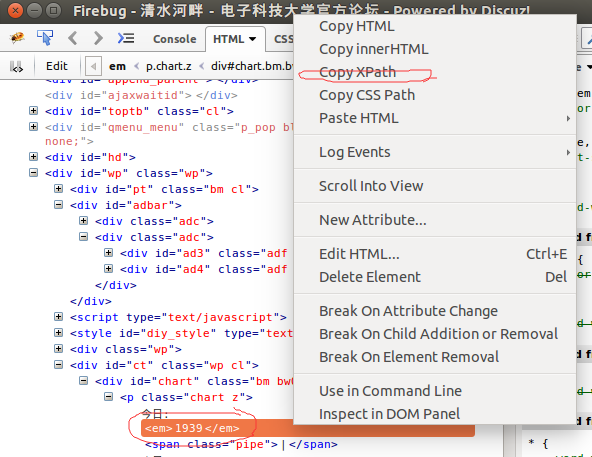
我们在spiders文件夹中创建自己的spider.py文件,在这个文件中我们可以编写自己的爬虫类。这里我们自己编写的爬虫类是从scrapy框架的Spider类中继承的。在我们这个最基本的爬虫中我们需要定义自己的爬虫名:name、限制爬虫爬取数据的域名范围:allowed_domain、爬虫开始工作的起始地址:start_urls。然后就可以在parse函数中对返回的response内容进行处理。在Scrapy中提取数据有自己的一套机制,它们被称作选择器(seletors),因为他们通过特定的 XPath 或者CSS 表达式来“选择” HTML文件中的某个部分。在这里我们选用xpath,xpath路径我们可以自己编写也可以使用firedebug中自带的提取xpath路径功能,如图所示,选择需要提取内容的部分右键选择xpath路径即可自动生成,但有时候这样生成的路径可能无法使用,建议自己手动编写。
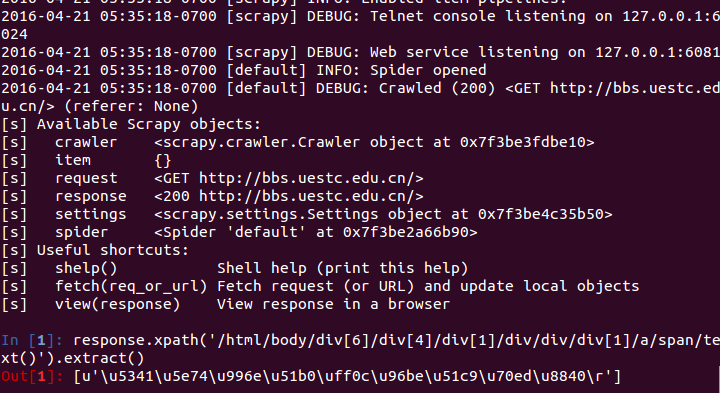
为了验证我们的xpath路径是否正确,我们可以在shell中进行验证,输入scrapy shell “url”如下图所示:
In中我们输入要提取的xpath路径,Out中就会输出对应位置的文本。
具体的spider代码如下所示:
from scrapy.spider import Spider
from scrapy.selector import Selector
from scrapy import log
from bbs.items import BbsItem
class bbsSpider(Spider):
name="bbs"
allowed_domain=["bbs.uestc.edu.cn/"]
start_urls=[
"http://bbs.uestc.edu.cn/"
]
def parse(self,response):
sel=Selector(response)
item=BbsItem()
item['name']=sel.xpath('//title/text()').extract()
item['today']=sel.xpath('/html/body/div[6]/div[4]/div[1]/p/em[1]/text()').extract()
item['posting']=sel.xpath('/html/body/div[6]/div[4]/div[1]/p/em[3]/text()').extract()
item['member']=sel.xpath('/html/body/div[6]/div[4]/div[1]/p/em[4]/text()').extract()
item['vanfan_geyan']=sel.xpath('/html/body/div[6]/div[4]/div[1]/div/div/div[1]/a/span/text()').extract()
item['newmember']=sel.xpath('/html/body/div[6]/div[4]/div[1]/p/em[5]/a/text()').extract()
return item3、编写pipelines、以及配置settings
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。
以下是item pipeline的一些典型应用:
清理HTML数据
(1)验证爬取的数据(检查item包含某些字段)
(2)查重(并丢弃)
(3)将爬取结果保存到数据库中
我们在pipelines.py中主要将spider抓取返回的item数据以utf-8形式保存到一个json文件中。并且在settings.py文件中添加配置项ITEM_PIPELINES = {
‘bbs.pipelines.BbsPipeline’:300,
}
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import codecs
import json
from scrapy import signals
class BbsPipeline(object):
def __init__(self):
self.file=codecs.open('data.json','w',encoding='utf-8')
def process_item(self, item, spider):
line=json.dumps(dict(item))+'\n'
self.file.write(line.decode("unicode_escape"))
return item
def spider_closed(self,spider):
self.file.close()最后在该项目的根目录运行scrapy crawl +爬虫名 开始运行爬虫,得到如下所示结果:
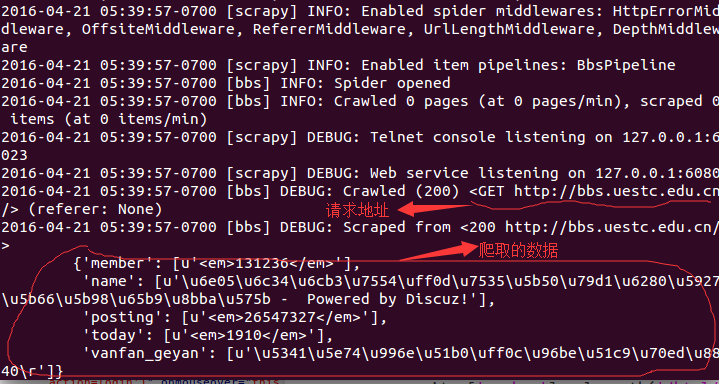
在爬虫运行完之后,在项目文件中会生成一个data.json文件,这个就是我们在pipelines.py文件中写的用来保存抓取数据的文件。文件内容如图所示:















 6816
6816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









