







转自: http://blog.csdn.net/qiaochao911/article/details/40920645
最近在维护kafka集群,遇到了很多问题都需要记录下:
集群信息:12台服务器,每台机子12块盘每块1.8T,其中6台做RAID,6台使用12块盘,64G内存,CPU24核,万兆网卡。集群每天写入的消息量能到每天33亿条消息,消费暂时还没有统计(通过ZK消费的消息量大概每天100亿,还有很大一部分走的SimpleConsumer没有统计)。
topic数量(截止2014-11-09):
- topic -- 205个
集群数据存储量(截止2014-11-09): -- 总共容量252T,已经使用39.4T,已用百分比15.63%
- 16634 -- 4.2T
- 16781 -- 4.4T
- 16782 -- 4.8T
- 16783 -- 3.5T
- 16784 -- 3.5T
- 16785 -- 4.2T
- 18081 -- 225+181+214+205+214+208+199+194+371+199+192+184 = 2586G
- 18082 -- 226+187+202+212+209+209+193+178+241+291+179+183 = 2510G
- 18083 -- 207+200+214+210+208+207+182+181+212+189+183+187 = 2380G
- 18084 -- 207+187+211+211+209+213+180+188+370+191+193+184 = 2544G
- 18085 -- 213+194+207+207+219+210+180+186+199+192+190+200 = 2397G
- 18086 -- 222+194+215+202+216+211+198+191+188+197+184+183 = 2401G(12块盘每块1.8T的容量,这里G为单位)
网卡的上下行流量(截止2014-11-09):
- 16634,16785 --- 50mb/s左右
- 16784 --- 35mb/s左右
- 16783,16782,16781 --- 30mb/s左右
- 18081,18082,18083,18084,18085,18086 -- 20mb/s左右
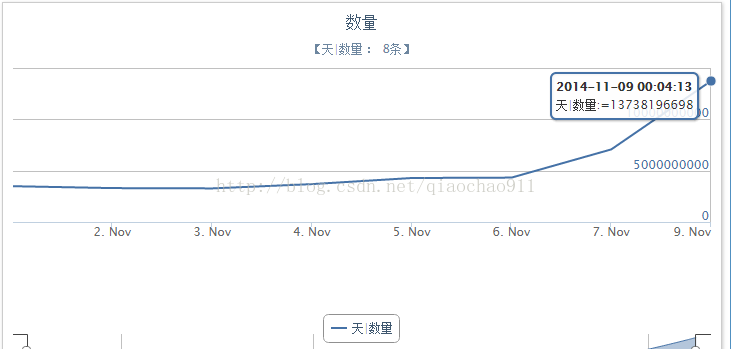
最近9天写入kafka集群的消息情况如图(截止2014-11-09,临近双11流量的消息量翻倍):
1. kafka 的topic 级别的配置修改
创建topic 的时候可以指定topic 的自己的相关配置与集群配置冲突,优先走topic自己的配置,未配置的走集群配置
- ./kafka-topics.sh --zookeeper 127.0.0.1:2181/kafka_2_10 --create --topic avrotest1 --partitions 1 --replication-factor 1 --config max.message.bytes=64000 --config flush.messages=1
修改其中的配置或者增加(注意:如果配置不是Topic_level的会报错--Error while executing topic command requirement failed: Unknown configuration "retention.hours")
- ./kafka-topics.sh --zookeeper 127.0.0.1:2181/kafka_2_10 --alter --topic avrotest1 --config retention.ms=128
- ./kafka-topics.sh --zookeeper 127.0.0.1:2181/kafka_2_10 --alter --topic avrotest1 --deleteConfig max.message.bytes
retention.ms=43200000 ---- topic数据保存的时间,超过这个时间则删除 以毫秒为单位,其他参数可见官方配置信息说明
2. kafka集群发送时间长,集群机子网卡上下行流量很不均衡,有些broker写数据的时间很长,经过测试修改发送ack为一份确认会快很多,也就是kafka的多broker之间拉取数据备份耗时较长,采取如下措施:
- 1) num.replica.fetchers=4 增加复制的线程数,默认为1 (broker配置)
- 2)replica.fetch.max.bytes=2097152 每次拉取消息的大小上线 (broker配置)
- 3)auto.leader.rebalance.enable=true
- leader.imbalance.per.broker.percentage=10
- leader.imbalance.check.interval.seconds=3600 自动均衡leader 每小时做一次(broker配置)
3. 手动指定分配topic的replica
编写需要分配的topic,partion和replica 的关系json,例如:(写入到test_reassignment.json)
- {"version":1,"partitions":[{"topic":"mine-topic","partition":0,"replicas":[16784,16785]},{"topic":"mine-topic","partition":1,"replicas":[16785,16634]}]}
按照指定的分配规则执行
- ./kafka-reassign-partitions.sh --zookeeper 127.0.0.1:2181/kafka_2_10 --reassignment-json-file test_reassignment.json --execute
可以查看执行进度
- ./kafka-reassign-partitions.sh --zookeeper 127.0.0.1:2181/kafka_2_10 --reassignment-json-file test_reassignment.json --verify
4. kafka字段分配到指定topic到指定的broker上
编写topics-to-move.json
- {"topics": [{"topic": "foo1"},
- {"topic": "foo2"}],
- "version":1
- }
- ./kafka-reassign-partitions.sh --zookeeper localhost:2181 --topics-to-move-json-file topics-to-move.json --broker-list "5,6" --generate
执行前---
- {"version":1,
- "partitions":[{"topic":"foo1","partition":2,"replicas":[1,2]},
- {"topic":"foo1","partition":0,"replicas":[3,4]},
- {"topic":"foo2","partition":2,"replicas":[1,2]},
- {"topic":"foo2","partition":0,"replicas":[3,4]},
- {"topic":"foo1","partition":1,"replicas":[2,3]},
- {"topic":"foo2","partition":1,"replicas":[2,3]}]
- }
- {"version":1,
- "partitions":[{"topic":"foo1","partition":2,"replicas":[5,6]},
- {"topic":"foo1","partition":0,"replicas":[5,6]},
- {"topic":"foo2","partition":2,"replicas":[5,6]},
- {"topic":"foo2","partition":0,"replicas":[5,6]},
- {"topic":"foo1","partition":1,"replicas":[5,6]},
- {"topic":"foo2","partition":1,"replicas":[5,6]}]
- }
5. 手动Balancing leadership
当topic有多个分区的时候,leader为replica list中最前面的那个broker,这个挂掉的时候leader会切换到其他的replaca中,这个时候可以kafka集群恢复leader,恢复副本运行
- ./kafka-preferred-replica-election.sh --zookeeper zk_host:port/chroot
- auto.leader.rebalance.enable=true
6. 遇到问题-kafka集群发送消息时间要很长甚者要到5秒以上,后台有16784Broker会不断自己重新向zk注册Broker(断掉所有链接,重新注册再把所有topic都rollback回来,网卡上下行一直上不来,链接数也很少)。经过查看各种监控信息,找到了源头并处理了这次事故:
xxx-topic 在前一天17:50 -- 第二天12:00之间发送数据,发送数据量46亿条消息
Topic: xxx-topic 分区:3 备份:3
- Partition: 0 Leader: 16634 Replicas: 16634,16781,16782 Isr: 16634,16781,16782
- Partition: 1 Leader: 16783 Replicas: 16783,18081,18082 Isr: 18081,18082,16783
- Partition: 2 Leader: 16784 Replicas: 16784,18082,18083 Isr: 18082,18083,16784
注:Partition 0 和 Partition: 1 的量都不大,Partition 2的量很大,此情况猜测每条消息的key是一样的(后续经过询问证实用了固定的key)。
分析处理:kafka集群单个broker写入消息的量太大(网卡和存储)会影响很大,一定要把数据量大的topic创建多个分区(根据topic的量大小来估算分区数量)分摊到不同的broker上,切发送时候的分区方法要设置均匀保证每个分区的量都差不多,关闭自动创建topic的功能,防止未知的topic出现这种问题。
16784Broker日志(会不断重复,truncate topic数据 rollback数据日志等全都省略):
- [2014-11-07 10:12:01,495] INFO re-registering broker info in ZK for broker 16784 (kafka.server.KafkaHealthcheck)
- [2014-11-07 10:12:01,667] INFO Registered broker 16784 at path /brokers/ids/16784 with address 172.22.167.84:9092. (kafka.utils.ZkUtils$)
- [2014-11-07 10:12:01,668] INFO done re-registering broker (kafka.server.KafkaHealthcheck)
- [2014-11-07 10:12:01,669] INFO Subscribing to /brokers/topics path to watch for new topics (kafka.server.KafkaHealthcheck)
- [2014-11-06 18:16:47,184] ERROR [ReplicaFetcherThread-3-16784], Error in fetch Name: FetchRequest; Version: 0; CorrelationId: 2242020; ClientId: ReplicaFetcherThread-3-16784; ReplicaId: 18082; MaxWait: 500 ms; MinBytes: 1 bytes; RequestInfo: [xxx-topic,2] -> PartitionFetchInfo(335480909,2097152) (kafka.server.ReplicaFetcherThread)
- java.net.SocketTimeoutException
- at sun.nio.ch.SocketAdaptor$SocketInputStream.read(SocketAdaptor.java:229)
- at sun.nio.ch.ChannelInputStream.read(ChannelInputStream.java:103)
- at java.nio.channels.Channels$ReadableByteChannelImpl.read(Channels.java:385)
- at kafka.utils.Utils$.read(Utils.scala:375)
- at kafka.network.BoundedByteBufferReceive.readFrom(BoundedByteBufferReceive.scala:54)
- at kafka.network.Receive$class.readCompletely(Transmission.scala:56)
- at kafka.network.BoundedByteBufferReceive.readCompletely(BoundedByteBufferReceive.scala:29)
- at kafka.network.BlockingChannel.receive(BlockingChannel.scala:100)
- at kafka.consumer.SimpleConsumer.liftedTree1$1(SimpleConsumer.scala:81)
- at kafka.consumer.SimpleConsumer.kafka$consumer$SimpleConsumer$$sendRequest(SimpleConsumer.scala:71)
- at kafka.consumer.SimpleConsumer
anonfun$fetch$1anonfun$apply$mcV$sp$1.apply$mcV$sp(SimpleConsumer.scala:109)
- at kafka.consumer.SimpleConsumer
anonfun$fetch$1anonfun$apply$mcV$sp$1.apply(SimpleConsumer.scala:109)
- at kafka.consumer.SimpleConsumer
anonfun$fetch$1anonfun$apply$mcV$sp$1.apply(SimpleConsumer.scala:109)
- at kafka.metrics.KafkaTimer.time(KafkaTimer.scala:33)
- at kafka.consumer.SimpleConsumer$$anonfun$fetch$1.apply$mcV$sp(SimpleConsumer.scala:108)
- at kafka.consumer.SimpleConsumer$$anonfun$fetch$1.apply(SimpleConsumer.scala:108)
- at kafka.consumer.SimpleConsumer$$anonfun$fetch$1.apply(SimpleConsumer.scala:108)
- at kafka.metrics.KafkaTimer.time(KafkaTimer.scala:33)
- at kafka.consumer.SimpleConsumer.fetch(SimpleConsumer.scala:107)
- at kafka.server.AbstractFetcherThread.processFetchRequest(AbstractFetcherThread.scala:96)
- at kafka.server.AbstractFetcherThread.doWork(AbstractFetcherThread.scala:88)
- at kafka.utils.ShutdownableThread.run(ShutdownableThread.scala:51)
- [2014-11-06 18:16:47,196] WARN Reconnect due to socket error: null (kafka.consumer.SimpleConsumer)
7. 手动Balancing leadership 时需要改变Replicas顺序,或者添加其他Replicas,可以先用上述4的方法改变Replicas 中broker的顺序或者添加删除broker,然后在用上述5中方法进行手动balance(注意:kafka-preferred-replica-election.sh 执行这个会将topic 的某个partition的leader 选举为Replicas中最前面的那个)。














 1799
1799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









