







摘要:我们对于ext2/ext3文件系统的了解大多来自操作系统的课本或者《understanding linux kernel》这本书,但是最近做了一个项目,需要根据文件的inode结点号找到inode本身。因此需要对ext2/ext3文件系统做深入的理解。在做的过程中才发现,原来书上讲的理论和现实的差距太大了。可能是因为书比较早,或者书上只是讲了一个概念模型,以至从实际工程的角度来看,课本上有好多的东西简直可以说是错误的。本文就把在工程中发现的问题和ext2/ext3文件系统的真相展示出来。
第一章:经典而又经典的图其实是错的
首先说明ext3文件系统和ext2文件系统的区别。ext3文件系统是带有日志的ext2文件系统,在设计时就秉承尽可能与ext2文件系统兼容的理念,因此他的文件系统数据结构与ext2文件系统的本质上是相同的。事实上可以把一个ext3文件系统卸载后做为ext2文件系统重新安装。反之也可以把创建日志的ext2文件系统做为ext3文件系统挂载。
ext2文件系统的磁盘数据结构如下图所示:

除了硬盘分区中的第一块作为引导块所保留,不受Ext3文件系统管理以外,其余部分分成块组(blockgroup),每个快组的分布下图所示,由于内核尽可能把属于一个文件的数据块存放在同一块中,所以组块减少了文件碎片。块组中的每块包含下列信息:
Ÿ 超级块:文件系统超级块的一个拷贝
Ÿ 组描述符:一组块组描述符的拷贝
Ÿ 数据块位图:一个数据块位图
Ÿ 索引节点位图:一组索引节点
Ÿ 索引节点表:一个索引节点位图
Ÿ 数据块:存放文件数据
其中超级块描述整个文件系统的信息,包括此文件系统共有多少个块组,每个块组包含多少个块,包含的结点的个数,每个结点的大小。
组描述符表描述的是每个组的情况,每个组有一个组描述符,大小为32字节。文件系统中所有的组描述符放在一起构成了组描述符表。
组描述符表之后是数据块位图和索引结点位图各占一个块。随后就是这个组的索引结点表,每个索引结点占用128个字节。
块组的大小是由数据块位图决定的。假设文件系统的数据块大小为b字节(可以配置为1K,2K,4K),则每个数据块位图可以描述的磁盘块大小为 b * 8 ,即8 * b * b 个字节大小。通常情况下块大小为4K,则一个块组包含 32k个物理块。需要说明是这32k个块并不全是数据块,而是包含元数据块和数据块的总和。这样看似备份的元数据浪费了数据块,但这种浪费换来的是查找性能上的提升。
块组大小确定之后,整个系统中的块组数就可以确定了,即磁盘总容量/每个块组的容量。
确定块组的重要的意义在于确定inode号。在整个文件系统中inode号是统一编址的,因此可以根据inode号确定这个inode所在的组号以及组内的偏移,进而找到这个inode。
根据上图,inode结点的地址的字节偏移应该按如下的方法计算:
inode地址 = ((inode_no / inode_per_group) * block_per_group + (1 + n + 1 +1)) * block_size + ( inode_no % inode_per_group ) * inode_size + 1024
其中inode_no为结点号,inode_per_group为每个块组含有多少个结点, block_per_group为每个块组的块的个数, (1 + n + 1 +1) 表示一个超级块,一个数据块位图,一个索引结点位图,n表示块组的个数,最后加上引导块占用的1K个字节。
但是实际的情况是这个公式是错误的,按照这个公式不可能读到索引结点。
第二章:寻找inode结点
产生错误的原因在于课本上所讲的数据结构是错误的,或者说只是一个逻辑上的模型,与实际在物理磁盘上存放的数据结构有很大的差别。首先看一张真正的磁盘数据结构图:
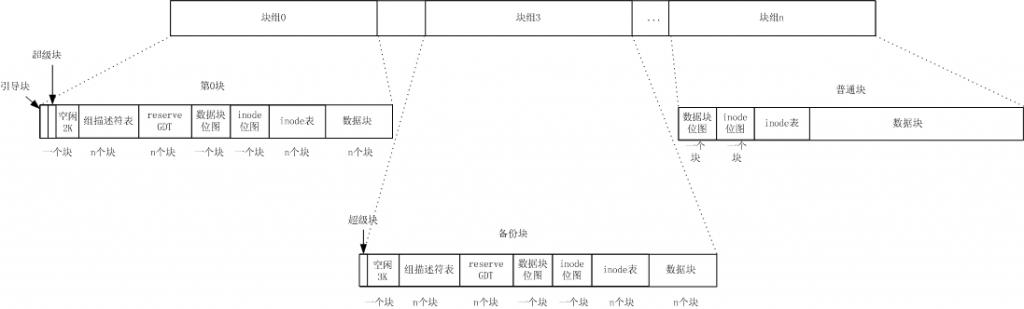
对比和上一张图的不同,真实的磁盘布局中有三种块组,一种是块组0,一种备份块组,一种是普通块组。
块组0即包含引导块的块组,通常系统使用元数据信息都是从这个块组中读取,只有当这个块组中的元数据发生错误时才会从备份的块组中恢复。
由此产生了和课本的冲突,并不是所有的块组都会备份一份元数据信息,只有部分块组会备份。但是哪些块组会备份呢?只有当块组号是3,5,7的幂的块组才会备份元数据,其他块组则是做为普通块组只存放数据,不备份元数据。
和课本的另一个冲突,引导块占据1K的空间,他虽然不被文件系统管理,但他确实占据了磁盘0块组的第一个块。所以教科书上的画法是不妥当的,或者说教科书只是画出了一种逻辑的磁盘结构,并不反应现实。在0块组的第一个块中,引导块和超级块各占了1K的空间,留下了2K的空闲。而在其他的备份块组中则没有引导块的备份,只是在第一个块中备份了一个超级块。
和课本的下一个冲突,在实际中出现了一个课本上没有提到过的区域,reserve GDT,而且还是一个占用了不少块的区域。这个区域是为了以后扩容用的。当以后为文件系统扩容时,可能人增加新的块组,块组描述符表也会相应增加,这个reserve GDT就是为那时使用的。这个区域占用多少个块我还没有找到计算方法,但是在super block结构中有一个域指示了这个区域占用的块数,可以直接读出。
至此,我们得到计算inode结点字节偏移的真正方法:
inode_address = ((inode_no / inode_per_group) * block_per_group + (1+n+n+1+1) * is_backup_group ) * block_size + (inode_no % inode_per_group) * inode_size
这就是真实的ext3文件系统的磁盘布局。到此我们可以拿到inode,可以进行查找操作了。
第三章:问题才刚刚开始
第一个问题:inode结点号真的是对的吗?
每个文件有一个inode结点,这个结点对应一个inode结点号。这个结点号可以由ls –i命令得到,也可以用debugfs 工具得到。但是这个inode结点号真的就是在磁盘物理空间上的结点顺序号吗? 看了内核中相应的一段代码才知道,这个inode结点号是不能直接拿来用的,必须减1才能用。减1是因为没有0号结点,我们拿到的结点号是从1开始计数的。
第二个问题:读写大文件
第二个问题是当把设备做为文件打开时,可能会因为设备过大导致文件无法支持,但是这时做的lseek, read操作会全部正确返回,但这时操作的结果是错误的,因为大的数据被截断了。解决方法是使用lseek64,或者_llseek。














 923
923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









