







资源下载
1、JDK下载: 下载链接
2、hadoop: 下载链接
3、下载完成后验证一下下载,将计算的MD5值与官网的进行对比已验证安装包的准确性:
md5sum ./hadoop-2.6.*.tar.gz | tr "a-z" "A-Z" # 计算md5值,并转化为大写,方便比较一、创建Hadoop用户
创建hadoop用户,并分配以用户名为家目录/home/hadoop,并将其加入到sudo用户组,创建好用户之后,以hadoop用户登录:
sudo useradd -m hadoop -s /bin/bash
sudo adduser hadoop sudo
sudo passwd hadoop # 设置hadoop用户密码二、安装JDK、Hadoop及配置环境变量
安装,解压JDK到/usr/lib/java/路径下,Hadoop到/usr/local/etc/hadoop/路径下:
tar zxf ./hadoop-2.6.*.tar.gz
mv ./hadoop-2.6.* /usr/local/etc/hadoop # 将 /usr/local/etc/hadoop作为Hadoop的安装路径解压完成之后,可验证hadoop的可用性:
cd /usr/local/etc/hadoop
./bin/hadoop version # 查看hadoop的版本信息若在此处,会出现类似以下的错误信息,则很有可能是该安装包有问题。
Error: Could not find or load main class org.apache.hadoop.util.VersionInfo配置环境,编辑“/etc/profile”文件,在其后添加如下信息:
export HADOOP_HOME=/usr/local/etc/hadoop
export JAVA_HOME=/usr/lib/java/jdk1.8.0_45
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$PATH:${JAVA_HOME}/bin:${JRE_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin使配置的变量生效:
source /etc/profile三、测试一下
在此我们可以运行一个简单的官方Demo:
cd `echo $HADOOP_HOME` # 到hadoop安装路径
mkdir ./input
cp ./etc/hadoop/*.xml ./input
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'输出的结果应该会是:
1 dfsadmin - 这里有一点需要注意,该Example程序运行时不能已存在
output目录,否则或将无法执行!
四、Hadoop的伪分布式环境搭建
什么是伪分布式?Hadoop 伪分布式模式是在一台机器上模拟Hadoop分布式,单机上的分布式并不是真正的分布式,而是使用线程模拟的分布式。分布式和伪分布式这两种配置也很相似,唯一不同的地方是伪分布式是在一台机器上配置,也就是名字节点(namenode)和数据节点(datanode)均是同一台机器。
需要配置的文件有core-site.xml和hdfs-site.xml这两个文件他们都位于${HADOOP_HOME}/etc/hadoop/文件夹下。
其中core-site.xml:
1 <?xml version="1.0" encoding="UTF-8"?>
2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
3 <!--
4 Licensed ...
-->
18
19 <configuration>
20 <property>
21 <name>hadoop.tmp.dir</name>
22 <value>file:/home/hadoop/tmp</value>
23 <description>Abase for other temporary directories.</description>
24 </property>
25 <property>
26 <name>fs.default.name</name>
27 <value>hdfs://master:9000</value>
28 </property>
29 </configuration> 文件hdfs-site.xml的配置如下:
1 <?xml version="1.0" encoding="UTF-8"?>
2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
3 <!--
4 Licensed ...
-->
18
19 <configuration>
20 <property>
21 <name>dfs.replication</name>
22 <value>1</value>
23 </property>
24 <property>
25 <name>dfs.namenode.name.dir</name>
26 <value>file:/home/hadoop/tmp/dfs/name</value>
27 </property>
28 <property>
29 <name>dfs.datanode.data.dir</name>
30 <value>file:/home/hadoop/tmp/dfs/data</value>
31 </property>
32 </configuration>配置完成后,执行格式化命令,使HDFS将制定的目录进行格式化:
hdfs namenode -format若格式化成功,在临近输出的结尾部分可看到如下信息:

五、启动HDFS
启动HDFS的脚本位于Hadoop目录下的sbin文件夹中,即:
cd `echo $HADOOP_HOME`
./sbin/start-dfs.sh # 启动HDFS脚本在执行start-dfs.sh脚本启动HDFS时,可能出现类似如下的报错内容:
localhost: Error: JAVA_HOME is not set and could not be found.很明显,是JAVA_HOME没找到,这是因为在hadoop-env.sh脚本中有个JAVA_HOME=${JAVA_HOME},所以只需将${JAVA_HOME}替换成你的JDK的路径即可解决:
echo $JAVA_HOME # /usr/lib/java/jdk1.*.*_**
vim ./etc/hadoop/hadoop-env.sh # 将‘export JAVA_HOME=${JAVA_HOME}’字段替换成‘export JAVA_HOME=/usr/lib/java/jdk1.*.*_**’即可再次执行
`echo $HADOOP_HOME`/sbin/start-all.sh如果成功,应该会有如下输出:

也可以执行以下命令判断是否启动:
jps若已成功运行起来了,会有类似如下输出:
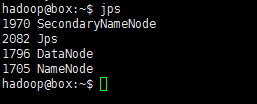
对了,初次执行貌似还有两次确认,输入“yes”即是。对应的启动,自然也有关闭咯:
`echo $HADOOP_HOME`/sbin/stop-dfs.sh当成功启动之后,可以在浏览器通过访问网址http://192.168.2.109:50070/
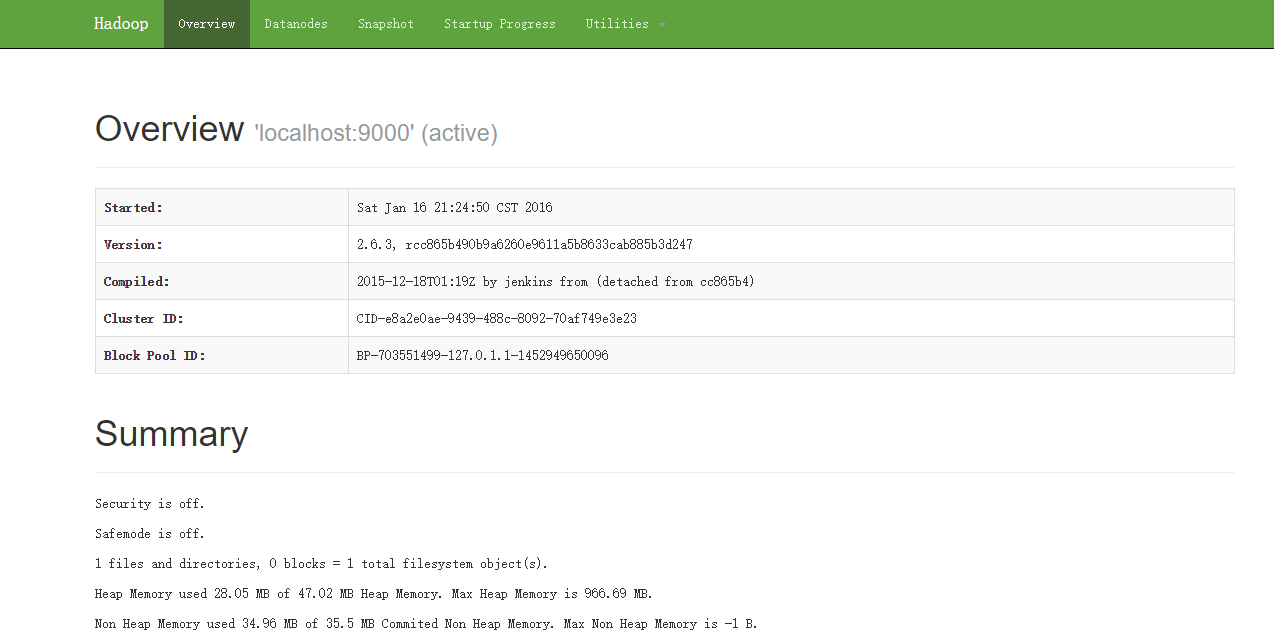
六、运行伪分布式实例
以上的“四、测试一下”只是使用的是本机的源生文件运行的测试Demo实例。既然搭建好了伪分布式的环境,那就使用分布式上存储(HDFS)的数据来进行一次Demo测试:
- 先将数据源搞定,也就是仿照“四”中的Demo一样,新建一个文件夹作为数据源目录,并添加一些数据:
hdfs dfs -mkdir /input # 这里的文件名必须要以‘/’开头,暂时只了解是hdfs是以绝对路径为基础,因为没有 ‘-cd’这样的命令支持
hdfs dfs -put `echo $HADOOP_HOME`/etc/hadoop/*.xml /input也可以查看此时新建的input目录里面有什么:
hdfs dfs -ls /
hdfs dfs -ls /input 再次运行如之前运行的那个Demo
hadoop jar /usr/local/etc/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /input /output 'dfs[a-z.]+'可看见如下输出:
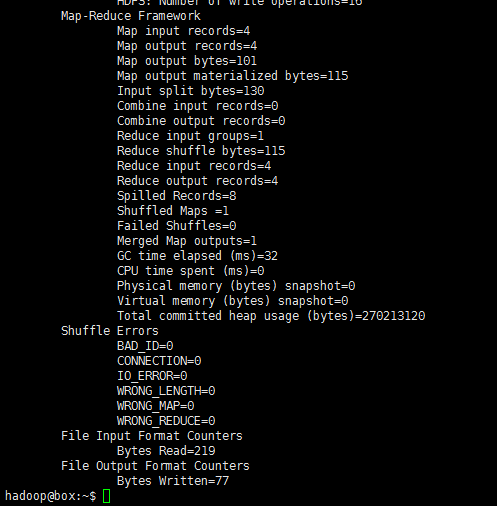
再次查看HDFS中的目录:
hdfs dfs -ls /
hdfs dfs -cat /output*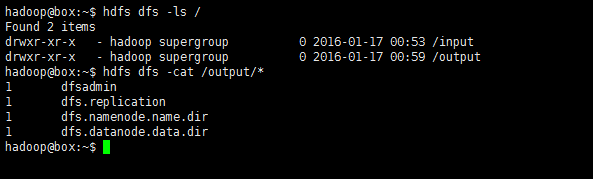
如此,该测试算式通过了。HDFS支持的操作hdfs dfs -command中的‘command’也可通过只键入hdfs dfs即可查看:
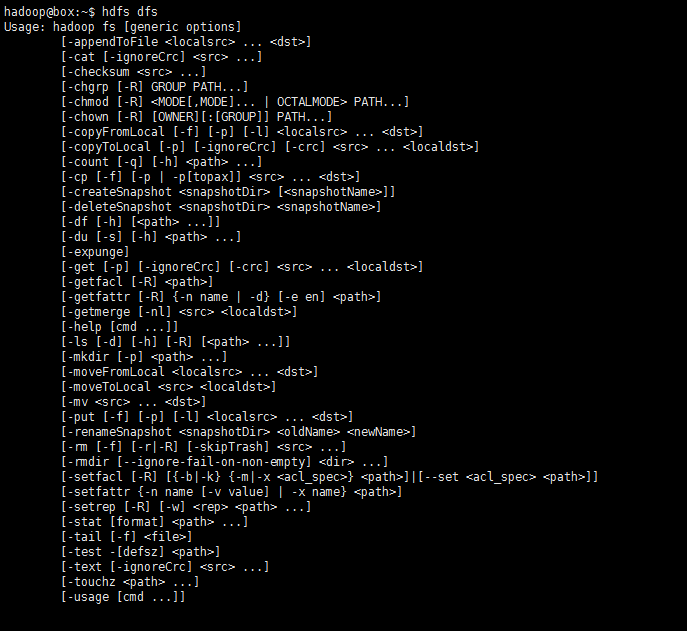
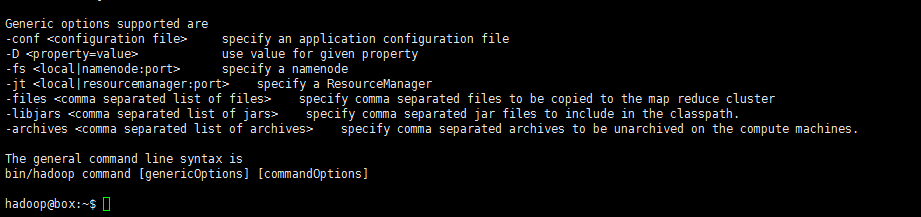
七、Hadoop集群安装
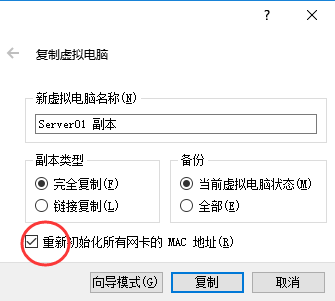
关乎集群,必然需要各太机器间能够通信,所以需配置使每台虚拟机的网卡连接方式为“桥接网卡”,并且他们的MAC地址一定不能有相同。配置集群所需的三台Linux虚拟机都运行在VirtualBox虚拟机上,既然已经配置好了一台的环境,可以使用virtualbox的复制功能,直接复制两台出来。
先关闭虚拟机,右键点击已配置好的那台Linux虚拟机,选择“复制”,在复制选项中一定要确认“初始化MAC地址“:
- 配置master
为便于区别master和slave,将作为master的主机名改为”master“,修改/etc/hostname文件,将里面以前的名称替换成‘master’:
sudo vim /etc/hostname修改master以及所有slave主机上的IP地址映射关系,添加master机器的IP以及slave机器的IP及对应的机器名称:
sudo vim /etc/hosts
#vim:
8 192.168.2.109 master
9 192.168.2.119 slave01 # 对应的第一个slav主机的名称
10 192.168.2.129 slave02 # 对应的第二个slav主机的名称修改完成之后重启一下虚拟机,重启之后验证一下是否能互相ping通:
master主机上ping所有:

slave01主机上ping所有:

- @ 这里所使用的IP地址,最好配置成静态的IP,配置静态IP可参考配置静态IP地址
master配置SSH无密码登陆slave节点
这个操作是要让master节点可以无需密码通过SSH登陆到各个slave节点上
安装openssh-server,生成密钥,配置无密码登录:
sudo apt-get install openssh-server
cd ~ # 进入hadoop用户目录下
mkdir .ssh & cd ./.ssh # keygen存放的位置
ssh-keygen -t rsa
cat id_rsa.pub >> authorized_keys # 加入授权然后将生成的密钥复制到其他的slave主机上,期间需要输入‘yes’确认传输和输入密码以认证身份:
scp /home/hadoop/.ssh/id_rsa.pub hadoop@slave01:/home/hadoop
scp /home/hadoop/.ssh/id_rsa.pub hadoop@slave02:/home/hadoop接着在各个slave节点上将ssh公钥加入授权:
cd ~
mkdir .ssh # 若是已经存在了,就先把它删掉
cat id_rsa.pub >> ./.ssh/authorized_keys
rm id_rsa.pub # 已使用执行完以上操作,便可测试一下在master上无密码ssh连接slave节点的主机了:
ssh slave01
配置集群/分布式环境
配置分布式集群环境需对一下几个文件进行配置:
slaves: 文件 slaves,配置datanode的主机名,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为namenode也作为datanode。分布式配置可以保留localhost,也可以删掉,让master节点仅作为namenode使用。现配置两个slave则在该文件中编辑如下字段:
slave01 slave02core-site.xml:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3 <!-- 4 Licensed ... --> 18 19 <configuration> 20 <property> 21 <name>hadoop.tmp.dir</name> <!-- Hadoop的默认临时文件存放路径 --> 22 <value>file:/home/hadoop/tmp</value> 23 <description>Abase for other temporary directories.</description> 24 </property> 25 <property> 26 <name>fs.defaultFS</name> <!-- namenode的URI --> 27 <value>hdfs://master:9000</value> 28 </property> 29 </configuration>hdfs-site.xml:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3 <!-- 4 Licensed ... --> 18 19 <configuration> 20 <property> 21 <name>dfs.replication</name> <!-- 数据节点个数 --> 22 <value>2</value> 23 </property> 24 <property> 25 <name>dfs.namenode.name.dir</name> <!--namenode节点的namenode存储URL --> 26 <value>file:/home/hadoop/tmp/dfs/name</value> 27 </property> 28 <property> 29 <name>dfs.datanode.data.dir</name> 30 <value>file:/home/hadoop/tmp/dfs/data</value> 31 </property> 32 <property> 33 <name>dfs.namenode.secondary.http-address</name> 34 <value>master:50090</value> 35 </property> 36 </configuration>mapred-site.xml,该文件一开始为一个模版,所以先拷贝并重命名一份:
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xmlvim:
1 <?xml version="1.0"?> 2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3 <!-- 4 Licensed --> 18 19 <configuration> 20 <property> 21 <name>mapreduce.framework.name</name> 22 <value>yarn</value> 23 </property> 24 <property> 25 <name>mapreduce.jobhistory.address</name> 26 <value>master:10020</value> 27 </property> 28 <property> 29 <name>mapreduce.jobhistory.webapp.address</name> 30 <value>master:19888</value> 31 </property> 32 </configuration>yarn-site.xml:
1 <?xml version="1.0"?> 2 <!-- 3 Licensed ... --> 15 <configuration> 16 <!-- Site specific YARN configuration properties --> 17 <property> 18 <name>yarn.resourcemanager.hostname</name> 19 <value>master</value> 20 </property> 21 <property> 22 <name>yarn.nodemanager.aux-services</name> 23 <value>mapreduce_shuffle</value> 24 </property> 25 </configuration>这些配置文件其他的相关配置可参考官方文档。配置好后,因为之前有跑过伪分布式模式,建议在切换到集群模式前先删除之前的临时文件:
cd `echo $HADOOP_HOME`
rm -rf ./tmp/
rm -rf ./logs再将配置好的master上的/usr/local/etc/hadoop文件夹复制到各个节点上(也就是覆盖原来的slave节点上安装的hadoop)。
以上步骤完毕后,首次启动需要先在master节点执行namenode的格式化:
hdfs namenode -format # 首次运行需要执行初始化,之后并不需要接着可以启动hadoop了,启动需要在master节点上进行:
cd `echo $HADOOP_HOME/etc/hadoop`
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver执行结果:
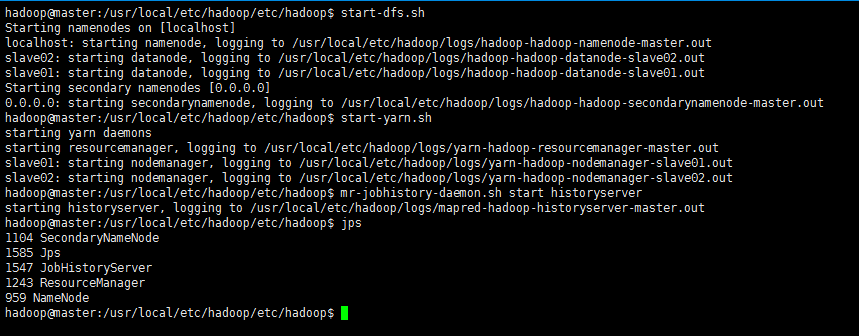
再使用jps查看启动之后的状态:
jps
此时,到slave主机上查看(jps)状态,会发现:
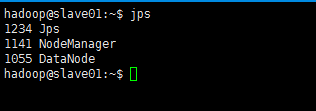
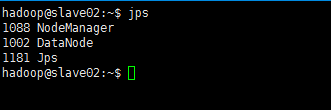
- 缺少任一进程都表示出错。另外还需要在 master 节点上通过命令
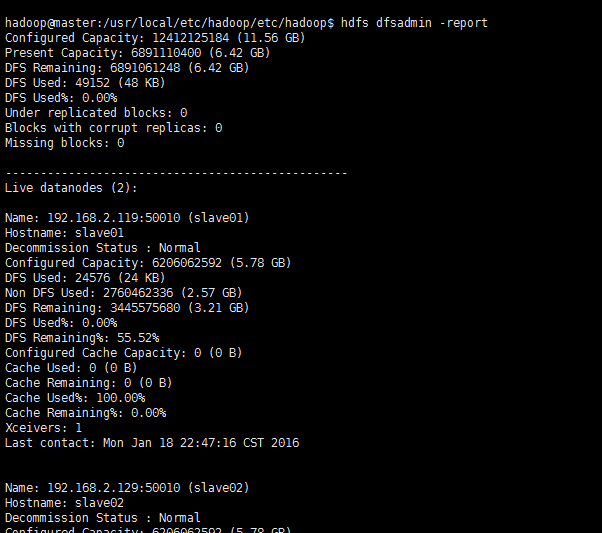
hdfs dfsadmin -report -live查看 datanode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。例如在此配置了两个datanode,则这边一共有 2 个 datanodes:
也可通过http://192.168.2.109:50070
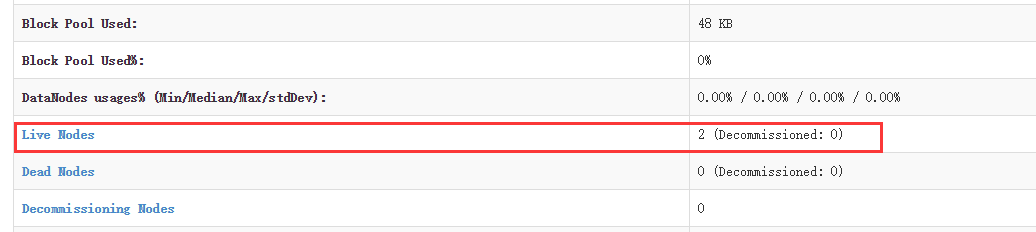
如果发现并没有出现如上信息,则使用刷新节点命令进行刷新:
hdfs dfsadmin -refreshNodes八、HDFS集群实例测试
依然是之前的那个示例,首先,创建一个数据源文件夹,并添加数据:
hdfs dfs -mkdir /input
hdfs dfs -put /usr/local/etc/hadoop/etc/hadoop/*.xml /input运行mapreduce示例:
hadoop jar /usr/local/etc/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /input /output 'dfs[a-z.]+'holding…














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









