







最近收到个需求:查询几百个域名的whois信息,如域名注册时间,到期时间,注册商,域名状态等.如果手动去一个个查询,效率低,而最近刚好在看scrapy,故用它来爬取相关信息.
首先是想尝试去爬阿里云的whois信息,但尝试失败,需要验证码.(先放一边,有空再看).而站长之家也可以查询,而且没验证码,便选择用站长之家来爬取.
要点
1.理解xpath.在爬去相关内容的时候,要用到
2.理解items和pipelines.使用它们可以更好的来存储,处理爬取后的内容
部署
scrapy的安装,可以看另外一篇: 在centos7和centos6下安装scrapy
安装完成后,就开始吧.
1.新建一个scrapy项目,比如项目名称是chinaz,执行如下命令:
scrapy startproject chinaz
默认整个项目的结构如下:
chinaz
├── chinaz
│ ├── __init__.py
│ ├── __init__.pyo
│ ├── items.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ └── __init__.pyo
└── scrapy.cfg
scrapy.cfg是整个项目的配置文件,我们这里不用修改.
chinaz/chinaz/spiders/ 这个目录下存放我们爬虫程序
分析
目的有两个:
1.查询多个域名时的交互问题
2.找出对应信息的xpath
打开http://whois.chinaz.com/,随意查询一个域名,比如163.com.点击查询,可以看到相关的whois信息,url变成了http://whois.chinaz.com/163.com,把末尾域替换为其他的,如http://whois.chinaz.com/sina.com,可以看到sina.com的相关whois信息.所以我们只要把后面的域名替换为要查询的域名,便可以获取对应的whois信息了.
使用chrome的检查,找到注册商,找出它的xpath
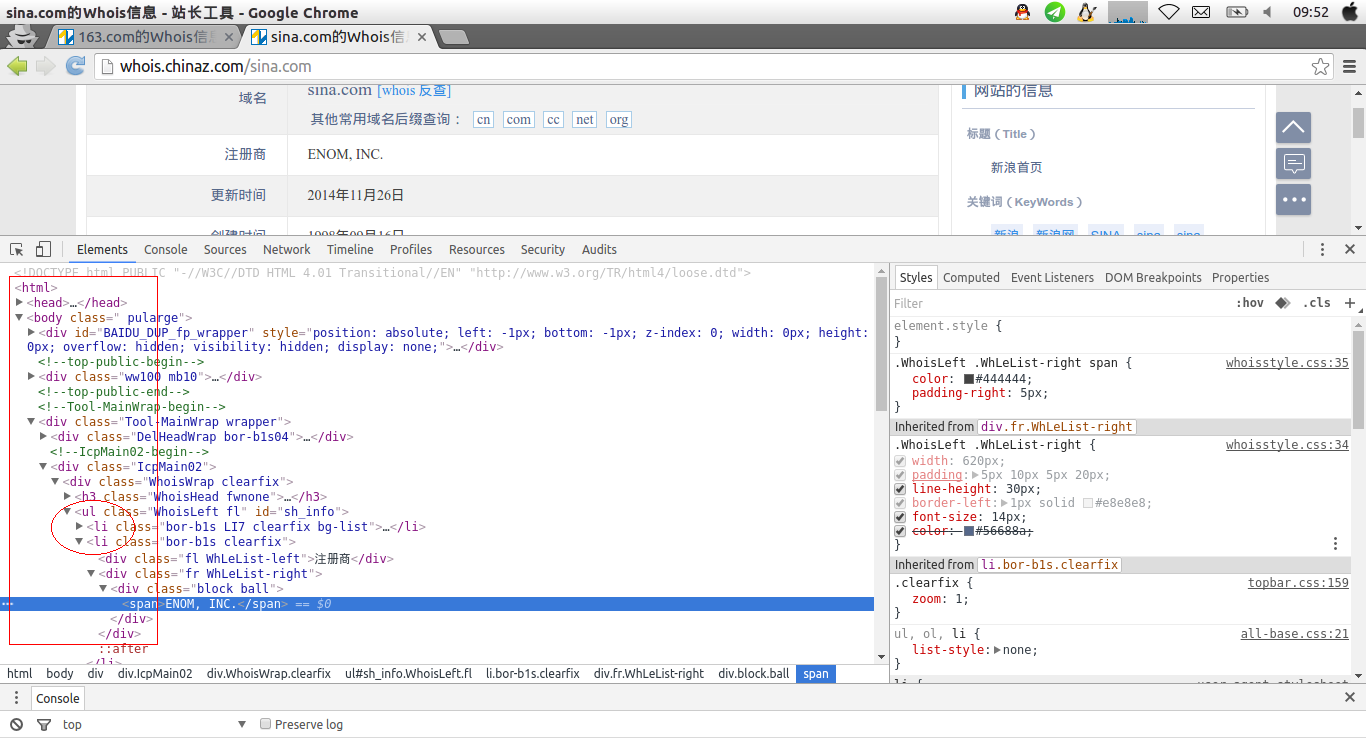
可以看出,所有的内容都在/ul/ui下面,注册商对应的内容是
<div class="fr WhLeList-right", <div class="block ball"
所以整个路径是:
//ul/li/div[@class="fr WhLeList-right"/div[@class="block ball"]/span/text()
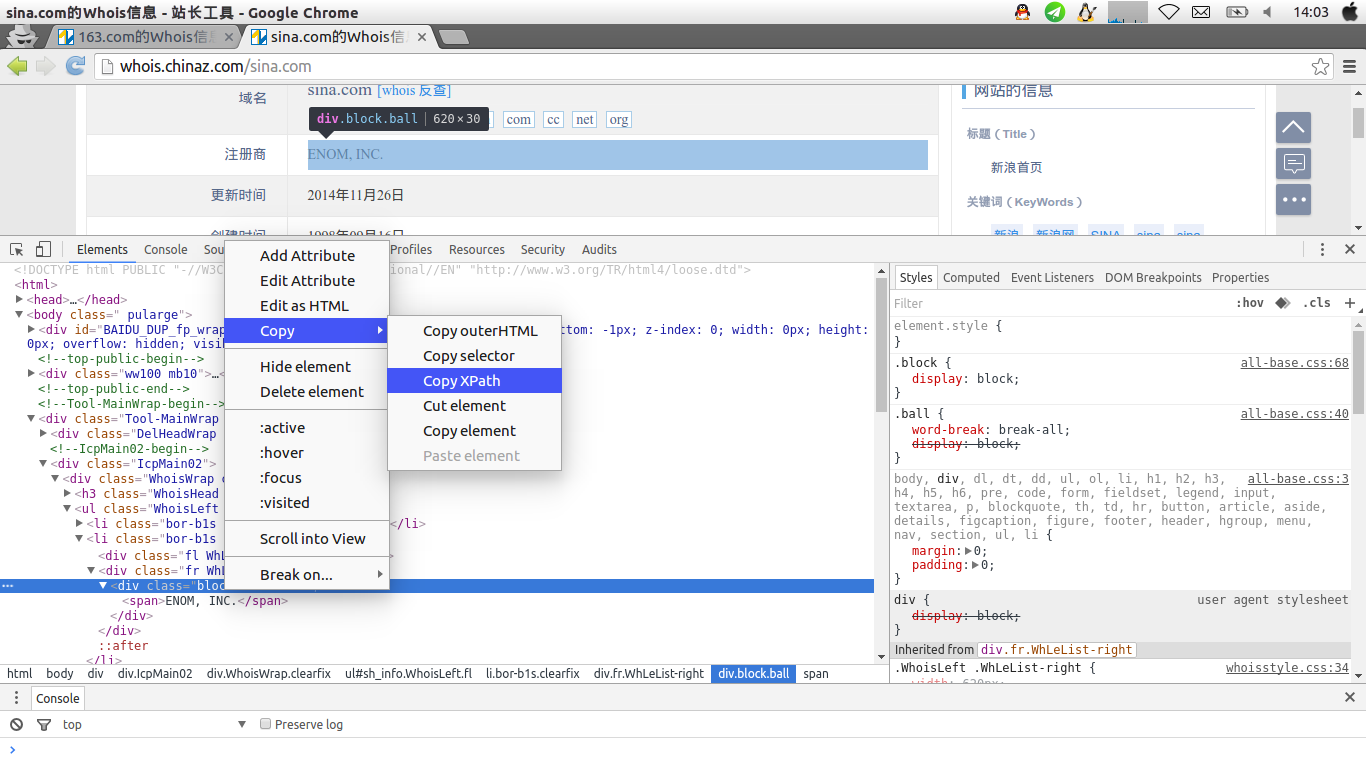
当然,如果一个个找出来拼凑会比较麻烦.我们可以直接用chrome的xpath功能.右击,选择copy,copy xpath,会获得如下路径
//*[@id="sh_info"]/li[2]/div[2]/div/span
爬取
直接上代码吧
1.chinaz_spider.py
#_*_ coding:utf-8 _*_
import scrapy
from chinaz.items import ChinazItem
class DmozSpider(scrapy.Spider):
name = "chinaz"
#allowed_domains = ["chinaz.com"]
dates = file('url').readlines()
start_urls = []
for v in dates:
v = v.strip('\n')
v = 'http://whois.chinaz.com/' + v
start_urls.append(v)
def clean_str(self):
data = self.data
data = [t.strip() for t in data]
data = [t.strip('\r') for t in data]
data = [t for t in data if t != '']
data = [t.encode('utf-8') for t in data]
return data
def parse(self, response):
surl = response.url
domain = surl.split('/')[3].strip()
items = []
regists = []
dates = []
dnss = []
contects = []
status = []
for sel in response.xpath('//ul/li/div[@class="fr WhLeList-right"]'):
#item = ChinazItem()
regist = sel.xpath('./div[@class="block ball"]/span/text()').extract()
date = sel.xpath('./span/text()').extract()
dns = sel.xpath('./text()').extract()
if regist != []:
self.data = regist
regist = self.clean_str()
regists.append(regist)
if date != []:
self.data = date
date = self.clean_str()
dates.append(date)
if dns !=[]:
self.data = dns
dns = self.clean_str()
dnss.append(dns)
for sel in response.xpath('//ul/li/div[@class="fr WhLeList-right block ball lh24"]'):
item = ChinazItem()
contect = sel.xpath('./span/text()').extract()
if contect != []:
self.data = contect
contect = self.clean_str()
contects.append(contect)
#yield item
for sel in response.xpath('//ul/li/div[@class="fr WhLeList-right clearfix"]'):
item = ChinazItem()
state = sel.xpath('./p[@class="lh30 pr tip-sh"]/span/text()').extract()
if state != []:
self.data = state
state = self.clean_str()
status.append(state)
#yield item
dates = [' '.join(t) for t in dates]
if len(dates) == 4:
dates.remove(dates[0])
item = ChinazItem()
item['regist'] = [' '.join(t) for t in regists]
item['date'] = dates
item['dns'] = ' '.join([' '.join(t) for t in dnss])
item['contect'] = [' '.join(t) for t in contects]
item['domain'] = domain
item['status'] = ' '.join([' '.join(t) for t in status])
return item2.items.py
import scrapy
class ChinazItem(scrapy.Item):
regist = scrapy.Field()
date = scrapy.Field()
dns = scrapy.Field()
contect = scrapy.Field()
domain = scrapy.Field()
status = scrapy.Field()
3.pipelines.py
class ChinazPipeline(object):
def process_item(self, item, spider):
try:
line = [item['regist'][0],item['date'][0], item['date'][1],item['dns'], item['contect'][0],item['domain'],item['status']]
except IndexError:
line = [item['regist'][0],item['date'][0], item['date'][1],item['dns'], ' ',item['domain'],item['status']]
line = ' '.join(line) + '\n'
fp = open('/tmp/domain_new.txt','a')
fp.write(line)
fp.close()
return item
4.setting.py里面要开启这个配置
ITEM_PIPELINES = {
'chinaz.pipelines.ChinazPipeline': 300,
}
以上动作都完成后,就开始爬取吧
scrapy crawl chinaz后续
站长之家的whois信息没有阿里云的新,有些信息没阿里云的全,所以有时间可以再研究下,如何去获取阿里云的whois信息.














 285
285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









