









报表开发中,经常会碰到一些需要进行非常规统计的报表,固定分组、可重复分组、组内排序,还包括跨行组计算的报表,甚至有些报表本身无数据来源、以及需要对数据源再计算。这些报表本身具备一定的特殊性,使用常规方法往往难于实现。
而集算报表在完成这类特殊统计报表时则比较简单,这里来看下使用集算报表完成固定分组报表的实现过程。
所谓固定分组报表是指分组没有规律,可能是分组范围没有规律,也可能分组顺序没有规律,需要报表开发人员事先固定分组的报表。常见的固定分组报表一般有三类:分段固定报表、固定次序分组报表、多层固定次序分组报表。
分段固定报表
这类报表的特点是分段的区间并未在数据库中存储需要根据相应字段(如年龄、日期)计算,并且每个分段可能会发生变化(如每年节假日所在日期可能不同),经常由用户随意指定。如:统计20-30岁,30-40岁,40-50岁各年龄段的用户数量;每年节假日(春节、端午节、国庆节)期间公路铁路承载的旅客统计。
更为特殊的情况下是对段界的要求,有的分段包含段界,有的分段不包含,这样看似特殊的情况可能伴随用户的指定时有发生。
下面通过实例说明,报表样式如下:

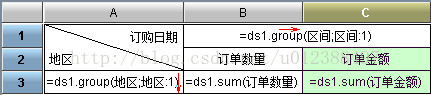
该报表是根据订单表统计各(预置)时间段内,各地区的订单数量、订单金额汇总。其中各时间段范围为:
【1996年圣诞前:date < 1996-12-25
1996年圣诞--1997年国庆:1996-12-25 <=date <= 1997-10-1
1997年国庆--1998年五一:1997-10-1 <= date<= 1998-5-1
1998年五一以后:date>1998-5-1】
这里出现了上文提到的段界包含问题,起始和结束两段不包含段界日期,而中间的各个分段则包含。
在润乾报表中,其提供的ds.plot()函数可以进行按段分组,而且可以通过该函数的参数控制是否包含边界,对于分组较少并且边界包含规律的分组报表尤其适用。但对于这类段界包含无规律的报表则无法实现。
润乾报表本身功能已足够强大,但仍然无法满足需求,其他报表工具实现起来将更加复杂,甚至无法实现。但在集算报表中,这类需求可以得到很好解决。使用集算报表可以通过如下步骤实现。
编写集算脚本
使用集算脚本编辑器编写集算脚本,这里使用系统默认数据源demo。
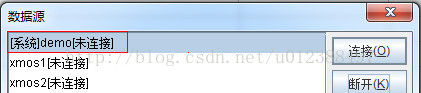
设置脚本参数(包括默认值,用于脚本调试)。
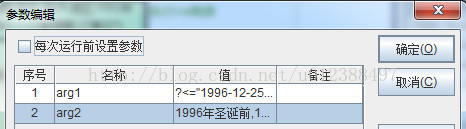
其中arg1值:?<="1996-12-25",?>="1996-12-25"&& ?<="1997-10-1",?>="1996-12-25" &&?<="1998-5-1",?>"1998-5-1"
arg2值:1996年圣诞前,1996年圣诞--1997年国庆,1997年国庆--1998年五一,1998年五一以后
编写脚本完成按段分组汇总计算。
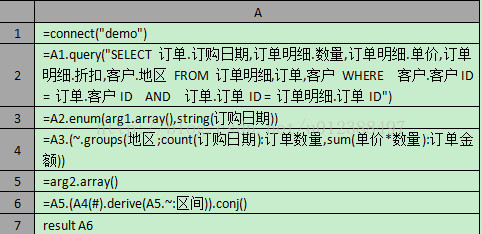
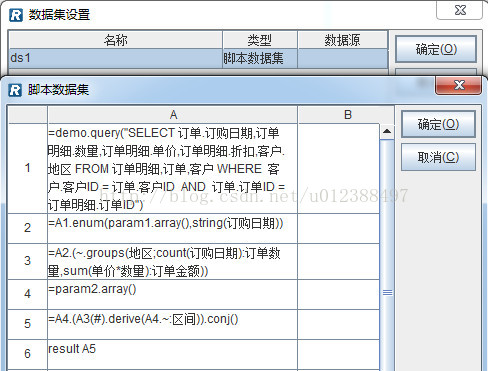
A1-A2:连接数据源后,通过sql完成取数;
A3:按照指定的日期端参数,根据订购日期进行分组,分组结果如下:
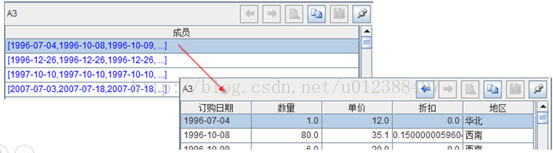
A4:汇总每个分段中的订单数据;
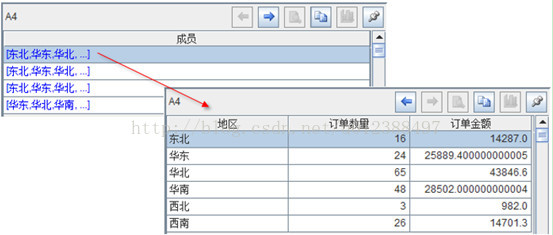
A6:增加字段显示时间段名称;
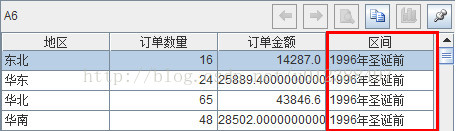
A7:为报表返回结果集。
编辑报表模板
使用集算报表编辑器,设置数据源,用于报表预览。
设置参数,并设置默认值。

新建报表模板并设置集算器数据集,调用上述编辑好的脚本文件。
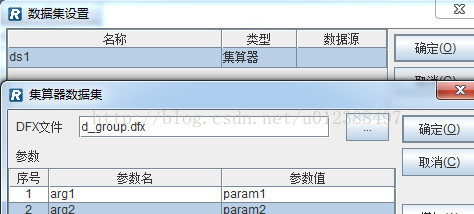
其中,dfx文件路径既可以是绝对路径,也可以是相对路径,相对路径是相对选项中配置的dfx主目录的;参数arg1和arg2为脚本参数,param1和param2为报表参数,实际使用中二者可以同名。
设置报表模板表达式,完成报表制作。
可以看到,使用集算器脚本可以快速完成这类特殊的分组报表。而且外置的集算脚本具有可视化的编辑调试环境,编辑好的脚本还可以复用(被其他报表或程序调用)。不过,如果脚本已经调试好,而且不需要复用的时候,要维护两个文件(集算脚本和报表模板)的一致性会比较麻烦,这时候直接使用集算报表的脚本数据集就比较简单了。
在脚本数据集中可以分步编写脚本完成计算任务,语法与集算器一致,还可以直接使用报表定义好的数据源和参数。以上述第二个报表需求为例,使用脚本数据集可以这样完成:
1. 在数据集设置窗口中点击“增加”按钮,弹出数据集类型对话框,选择“脚本数据集”;
2. 在弹出的脚本数据集编辑窗口中编写脚本;
这里可以看到,在脚本数据集中直接使用了报表中定义好的数据源demo,以及参数param1、param2,比起单独的集算脚本更加简单、直接。
3. 报表模板和表达式与使用集算器数据集方式一致,不再赘述。
除了按段分组报表,固定分组报表还包括固定顺序或多层固定顺序分组报表。下面分别来看一下实现过程,基于实现步骤与上述例子雷同,这里只展示主要实现步骤。
固定次序分组报表
这类报表的特点是用户要求分组次序固定,而数据库中并未存储相应的分组字段。如:要统计长三角地区、珠三角地区以及环首都经济圈内客户的订单情况。数据库客户表中只有城市(如:北京、上海、石家庄)和地区(如:华北、东北、华南)字段,如果单纯为该报表在数据库里增加另外一个地区字段显然是不值得的,所以任务自然落到报表端了。
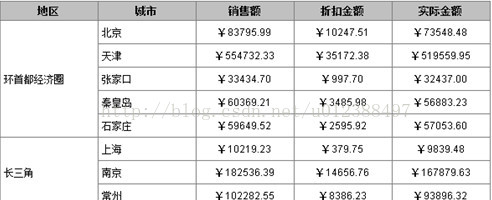
下面通过一个实例来说明使用集算器辅助实现这类报表的过程,报表样式如下:
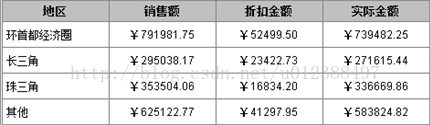
要求:
1、 根据源数据中的城市分区分组汇总某年的订单数据,其中:
环首都经济圈包括:[北京,天津,张家口,承德,保定,廊坊,唐山,秦皇岛,衡水,沧州,石家庄]
长三角地区包括:[上海,南京,苏州,无锡,常州,镇江,南通,扬州,泰州,杭州,宁波,湖州,嘉兴,绍兴,舟山,台州]
珠三角地区包括:[广州,深圳,珠海,佛山,江门,东莞,中山,惠州,肇庆]
其他城市列为其他地区;
2、报表显示的地区顺序固定,即上图所示顺序显示,这里显然无法通过按字母顺序升降来排序。
该类分组报表使用润乾报表实现,主要通过ds.overlap()函数,报表模板及其表达式如下:

其中,A2的表达式为:
=ds1.overlap(true,城市 in list("北京","天津","张家口","承德","保定","廊坊","唐山","秦皇岛","衡水","沧州","石家庄"),"环首都经济圈",城市 in list("上海","南京","苏州","无锡","常州","镇江","南通","扬州","泰州","杭州","宁波","湖州","嘉兴","绍兴","舟山","台州"),"金三角",城市 in list("广州","深圳","珠海","佛山","江门","东莞","中山","惠州","肇庆"),"珠三角","其他")
这里可以看到ds.overlap()函数的强大,对于固定的分组以及分组下成员较少的情况尤其适用。但当分组或分组成员过多时,继续使用该函数的可读性就太差了,难于维护;此外,本例中看到的是一层分组,如果要实现多层固定次序分组报表,ds.overlap()函数则无法直接实现。这类报表在集算报表中可以这样完成。
集算脚本
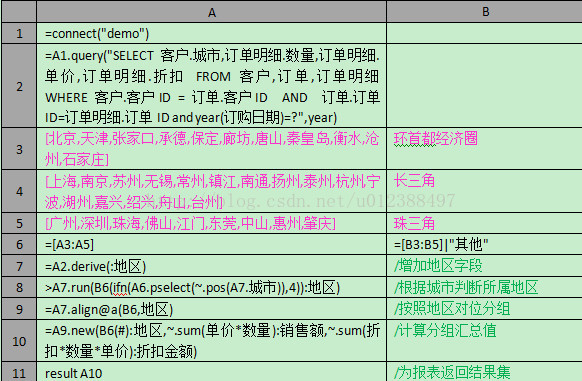
报表模板

通过在集算脚本中完成指定地区的分组汇总运算,在报表模板中只简单进行数据呈现,非常简单。
多层固定次序分组报表
再修改一下上例的报表需求,要求按地区和城市分组,且地区和城市的展现顺序固定,如下顺序(没有则不显示):
环首都经济圈包括:[北京,天津,张家口,承德,保定,廊坊,唐山,秦皇岛,衡水,沧州,石家庄]
长三角地区包括:[上海,南京,苏州,无锡,常州,镇江,南通,扬州,泰州,杭州,宁波,湖州,嘉兴,绍兴,舟山,台州]
珠三角地区包括:[广州,深圳,珠海,佛山,江门,东莞,中山,惠州,肇庆]
报表样式如下:
当出现多层固定分组时,使用润乾报表的ds.overlap()函数就无法实现了,但在集算报表中仍然可以很好满足。
集算脚本
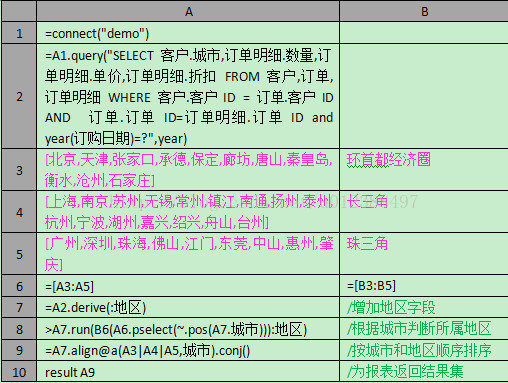
报表模板















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









