







引言:
自己在学习这个东西的时候,发现网上很多关于HashMap底层介绍的文章基于的jdk版本比较低。因为我对比之后发现编码风格有了比较大的改变。而且,今天我想尝试一种很通俗的方式来尝试记录这次的学习。在本文中我主要整理了HashMap类的重要成员变量和关键方法的涵义和作用,HashMap初始化方式并描述初始化变量。了解HashMap存储结构,根据JDK源码逐字逐句解读核心方法。笔者目前整理的一些blog针对面试都是超高频出现的。大家可以点击链接:http://blog.csdn.net/u012403290
技术点:
1、数组与链表
简单通俗来说,两者各有优劣。对于数组来说,它的存储空间是连续的,占用内存严重,连续的大内存进入老年代的可能性也会变大(关于GC后面我会把学习的也记录下来),但是正因为如此,寻址就显得简单,也就是说查询某个arr会有指定的下标,但是插入和删除比较困难,因为每次插入和删除时,如果数组在插入这个地方后面还有很多数据,那就要后面的数据整体往前或者往后移动。对于链表来说存储空间是不连续的,占用内存比较宽松,它的基本结构是一个节点(node)都会包含下一个节点的信息(如果是双向链表会存在两个信息一个指向上一个一个指向下一个),正因为如此寻址就会变得比较困难,插入和删除就显得容易,链表插入和删除的时候只需要修改节点指向信息就可以了。
2、哈希表/散列表(Hash table 注意这个不是JAVA线程安全类:HashTable)
“你有故事我有酒”,很多时候两者结合才显得韵味十足。在哈希表的结构中就融入了数组和链表的结构,从而产生了一种寻址容易,插入删除也容易的新存储结构,下图是百度百科引入的图片:
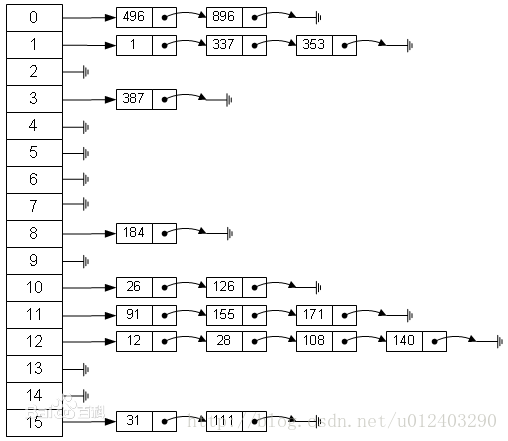
其实哈希表的实现方式有很多种,我们就研究如上这最常用的一种:
为了解释方便,我们定义两个东西:String[] arr; 和 List list;
那么,上图左边那一列就是arr, 就是整个的arr[0]~arr[15],且arr.length() = 16。上图每一行就是一个list,这里理论来说应该最大存储16个List。每个数组存存放的应该是某一个链表的头,也就是arr[0] == list.get(0)。不知道我这样的描述是否清楚。
那么如何确定某一个对象是属于数组的某个下标呢?一般算法就是 下标 = hash(key)%length。算式中的key是存放的对象ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









