










『RNN 监督序列标注』笔记-第三章 神经网络
多层感知机(Multilayer Perceptrons)
多层感知机的输出仅仅取决于当前的输入,因此 MLPs 更适用于模式分类而非序列标注任务。仅仅具有单隐含层的 MLPs 就具有了以任意精度逼近任意连续函数的能力,因此也被成为通用函数拟合器(universal function approximators)。
前向过程
前向过程可以描述为
激活函数有多种选择。其中有
然而有 tanh(x)=2σ(2x)−1 因此他们作为激活函数是等同的,实际使用中可以根据值域的不同来选择。这两种激活函数最大的优点在于:非线性与可微性。
输出层
可以用 softmax 进行多类输出函数:
损失函数
简单起见,先不考虑最大后验估计,只考虑极大似然估计,则直接取负对数即可:
反向过程
反向过程的关键在于推导残差反向传播过程。如果从链式法则的角度思考这个过程,能够清晰简单地得到结论,这里Calculus on Computational Graphs: Backpropagation介绍的很清楚。由于
可以定义
由链式法则
最终有
梯度校验
反向过程中一般采用对称差分的方式进行梯度校验:
循环神经网络(Recurrent Neural Networks)
与 MLP 相比,RNN 最大的优势在于其内部状态具有的记忆功能:MLP 只能建立从输入到输出向量的映射,而 RNN 却能够建立从之前整个历史到输出的映射。
前向过程
前向过程可以由公式下式概括:
最后一层的分类器,对于序列分类与时间段分类任务,都可以直接使用 MLP 的 Softmax / Logistic;而对于时序分类任务,需要重新设计输出层。
反向过程
反向过程一般采用(backpropagation through time ,BPTT),这种算法在概念和时间复杂度上都更优。
其中
展开(Unfolding)
标准的 RNN 网络结构如图所示:
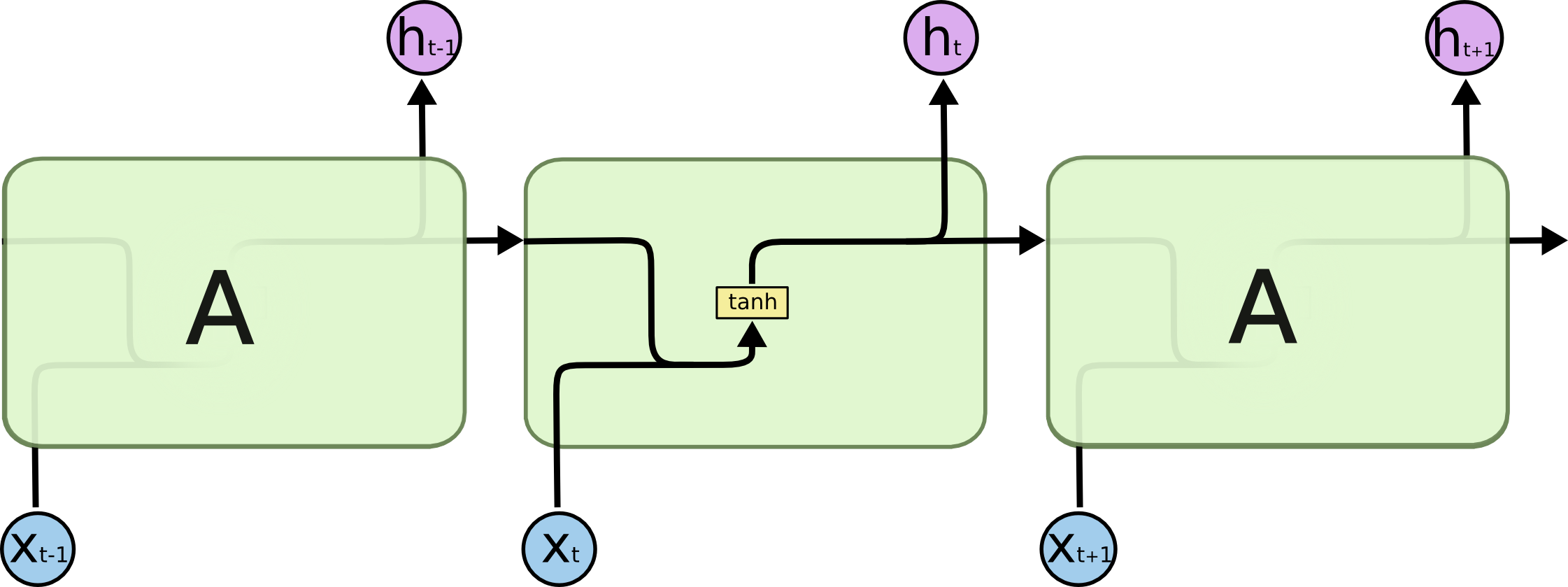
双向神经网络(Bidirectional recurrent neural networks, BRNNs)
如果能够同时使用序列的未来信息和历史信息,将能够更好完成序列标注任务。然而标准的 RNN 只能使用历史信息。最容易想到的解决方式有2种:
- 加上包含未来信息的时间窗。其缺陷在于:窗口长度固定、不能处理序列畸变。
- 加上输入序列与输出序列之间的延时。其缺陷在于:延时需要人工确定、每次都要记忆之前的上下文,对网络是一种负担。
正向过程与标准 RNN 类似,但是输入序列以两个相反的方向输入到两个不同的隐含层。整条序列处理完成之后,隐含层参数一起更新。反向过程也是类似。如图所示:
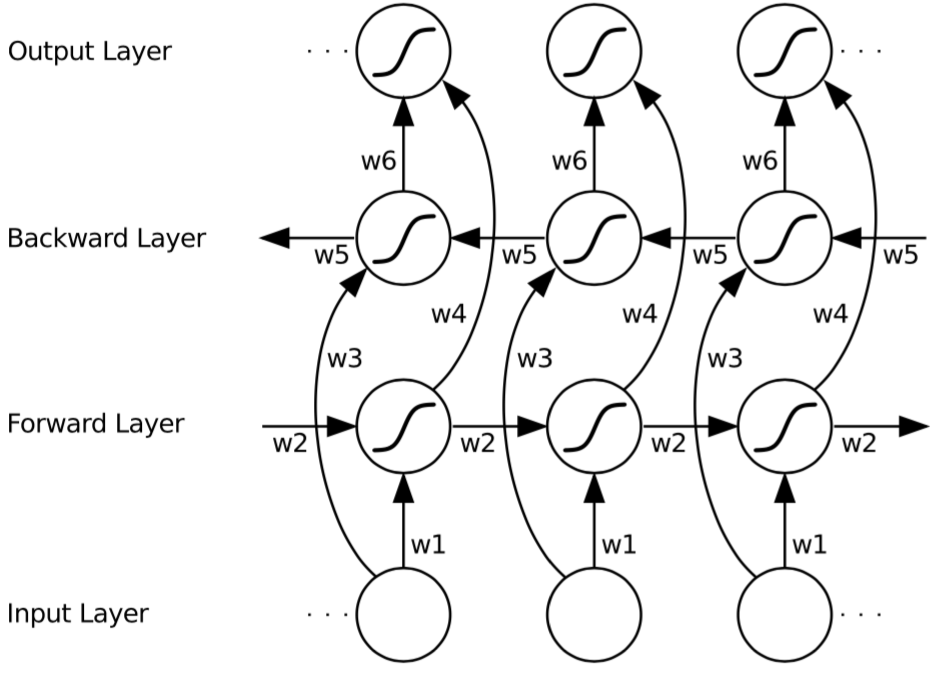
因果任务(Causal Tasks)
BRNN 违背了因果律,因此难以用于机器人导航、金融预测等等任务。然而如果输入序列是空间序列而非时间序列,那么输入序列的过去和未来就没有区别了,例如蛋白质结构的预测。
- 某些情况下,BRNN 也可用于时间序列任务,只要输出是在序列结束时才给出,例如语句识别和手写体识别任务。
- 甚至在线时间序列任务也能够使用 BRNN,只要允许在输入序列之间存在若干停顿,例如在线语音听写任务。
雅克比序列(Sequential Jacobian)
为了衡量输出向量对于输入微小改变的敏感程度,可以使用四维雅克比矩阵
J
,也称为序列雅克比:
通过雅克比序列,我们能够评估网络在某个特定时间步的输出下,整个输入序列中每个时间步对此分别的影响。
- 雅克比序列的绝对幅值并没有意义,其相对幅值能够表示输出被输入影响的程度(敏感度)。
- 敏感度在那些具有较小方差的时间步会更大,例如固定图片背景的角落。这是因为网络预计那里不会有什么变化,变得非常敏感。造成雅克比序列幅值很大,但并不能说明这个时间步就绝对更重要。
如图所示:是在线手写体识别任务的雅克比序列,
x
和
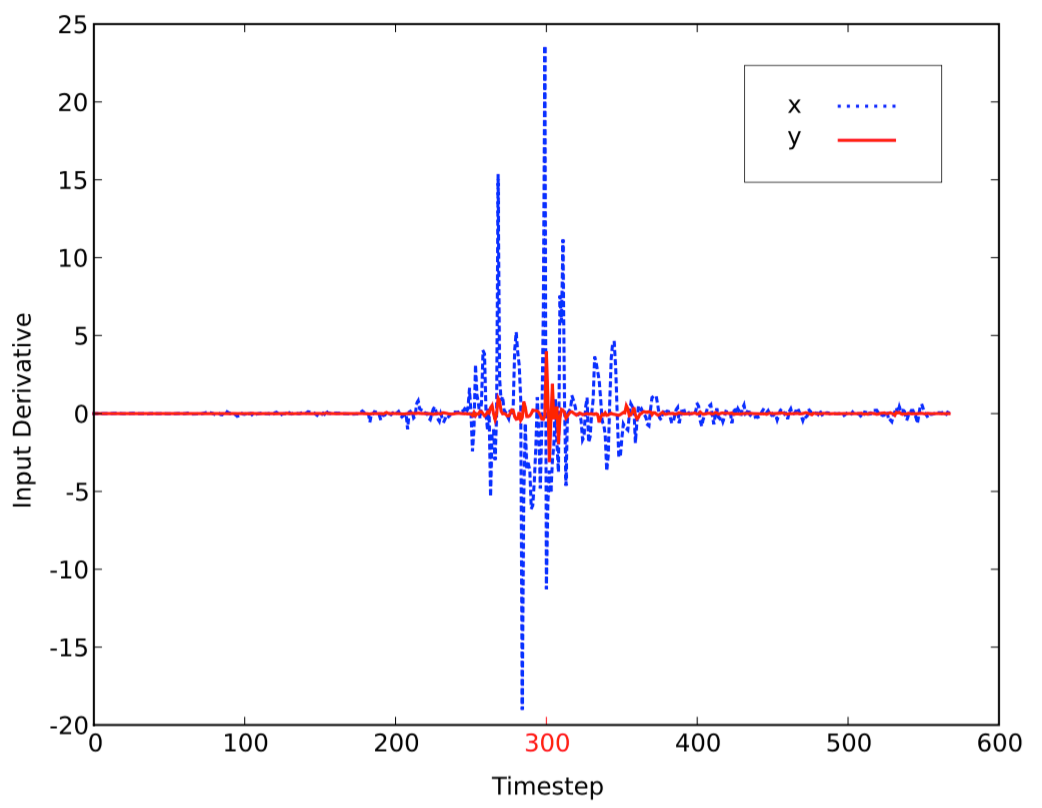
网络训练
梯度下降法
为了缓解陷入局部极值的问题,可以加上动量项:
泛化(Generalisation)
泛化即模型对于没有见过的数据集的预测效果。一般训练集越大,泛化效果越好。使用正则化(regularisers)方法能够改善泛化效果,例如提前停止、输入噪声以及权重噪声。
提前停止(Early Stopping)
提前停止是为了防止过拟合(overfitting)。将训练集抽出一部分作为验证(validation)集。训练刚开始时,三者错误率都持续下降,到一定位置,验证集开始停止下降,选取此时停止,可以作为测试集的最优值。如图所示:
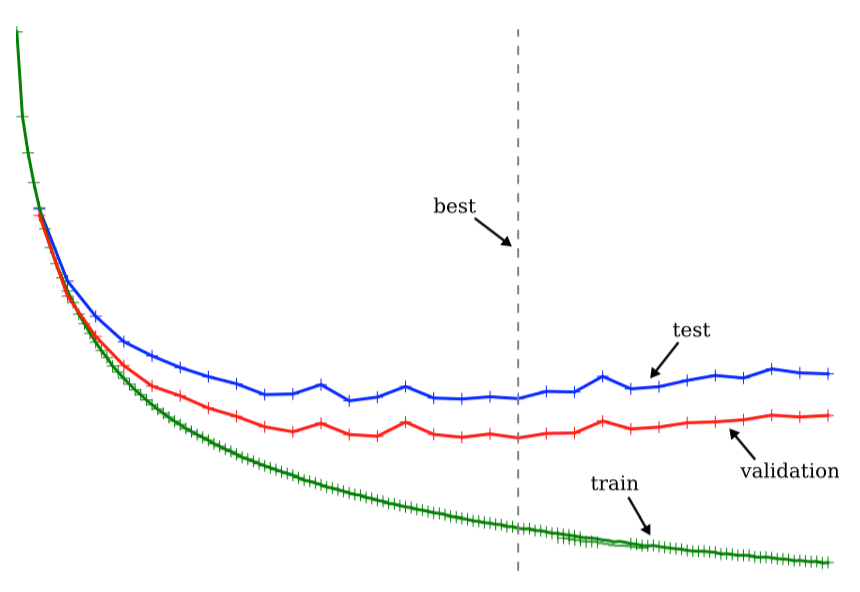
使用验证集有两个问题:其一,需要牺牲一部分训练集做验证,如果训练集本身就很小,会破坏训练效果。其二,难以确定验证集的大小。
输入噪声
向输入数据加入0均值高斯噪声能够人为增加输入数据的规模,从而最终增强网络的泛化能力。输入噪声的困难一方面在于难以决定噪声的大小,只能在验证集上凭经验选取;更重要的一方面在于,这种添加噪声的方式仅当它们反映了真实数据变化时才能奏效。如图所示:

这张图片来自于 MNIST,高斯噪声不管怎么加,这张照片都没有本质变化。但图片下方的随机拉伸则不然, 有效扩充了训练集。
- 每次不要用相同的随机噪声。
- 测试集不要加噪声。
权重噪声
另一种方案是给网络的权重施加0均值高斯噪声,因为这种方式适用于各种输入数据类型。然而一般来说,权重噪声效果弱于精心设计的输入噪声,并且可能造成收敛很慢的问题。同样地,在测试集上不应当使用权重噪声。
输入表达(Input Representation)
输入表达的目的是让输入数据与输出数据的关系尽可能简单,其要求是数据是完全的(包含了用以预测输出的全部信息)、相当紧凑(避免维数过高影响效果)。
首先是计算均值:
其次是计算标准差:
最终输入数据为:
注意:验证集和测试集要使用训练集所用的均值和标准差。
权重初始化
权重初始化一般要求网络权重初值选取随机、较小。














 549
549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









