







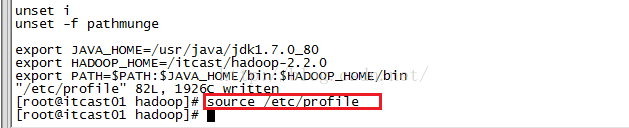
上节我们修改了5个配置文件,这节我们开始学习Hadoop初始化和测试,首先我们需要Hadoop的环境变量,输入命令:vim /etc/profile并按回车进入配置文件,如下图所示,我们添加的内容是下面红色圈住的内容。

编辑完之后我们按ESC键进行退出编辑,然后输入:wq保存并退出该文件,然后我们输入命令source /etc/profile来使配置起作用,如下图所示。
接下来我们开始初始化HDFS(格式化文件系统),格式化之前我们先到hadoop2.2.0目录,查看下该目录下都有哪些文件,从下图我们可以看出目前并没有tmp这个目录。

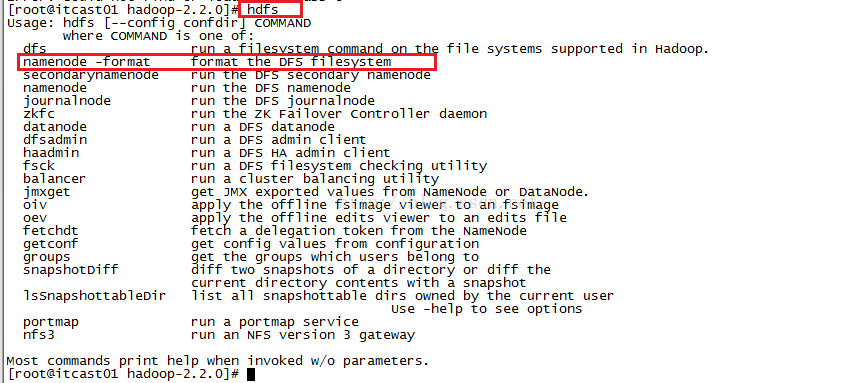
格式化文件的命令如果我们不知道的话,可以输入hdfs之后按回车,看提示信息,如下图所示,我们可以知道格式化的命令是hdfs namenode -format
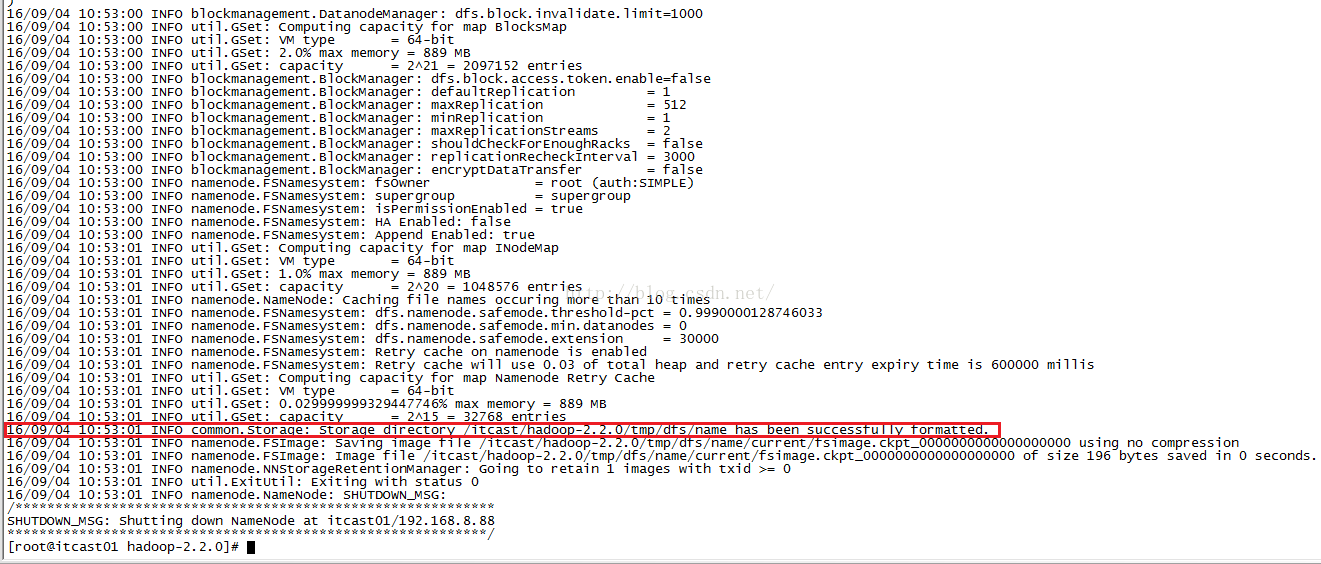
我们输入命令hdfs namenode -format并按回车后就开始进行格式化了,格式化完之后我们如果从信息中看到如下红色圈住的内容(/itcast/hadoop-2.2.0/tmp/dfs/name has been successfully formatted)说明格式化成功了!
格式化完之后,我们再来看看hadoop-2.2.0目录下的文件列表,我们可以看到列表中已经有tmp这个目录了。

接下来我们开启hdfs和yarn,首先我们进入sbin目录,然后查看都有哪些脚本,我们发现有很多脚本,其中我们用到的是start-dfs.sh、start-yarn.sh,当然,我们也可以直接用start-all.sh(不过已经过时了)来启动,如下图所示。

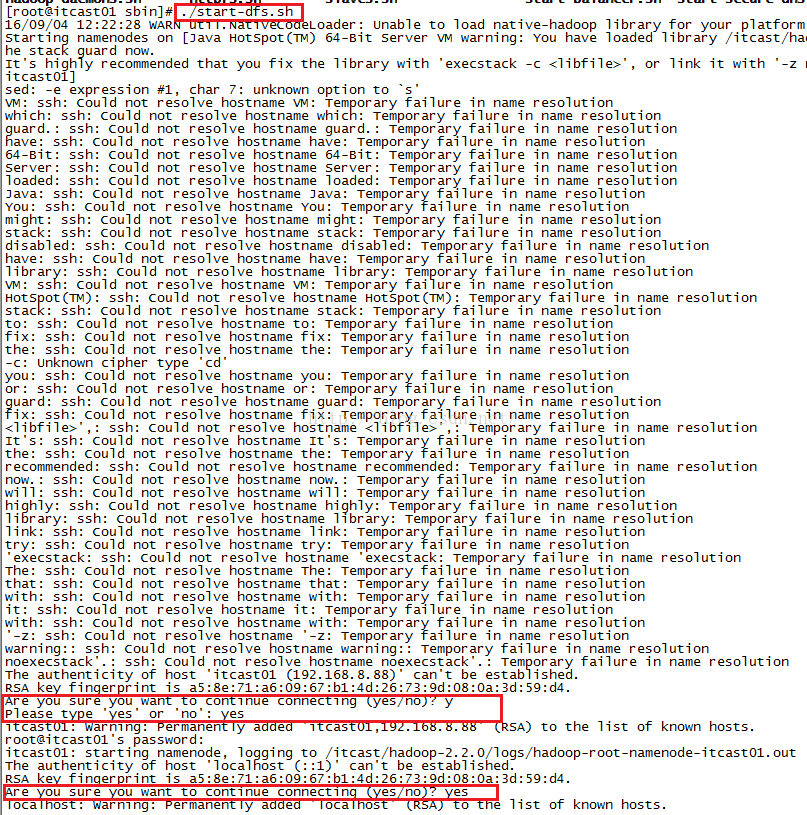
我们先启动dfs,输入命令./start-dfs.sh并按回车,启动过程中会多次让你输入yes和root账号的密码,如下图所示。
启动完start-dfs.sh之后,我们接着启动start-yarn.sh,如下图所示。

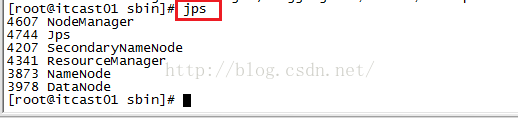
启动完两个脚本之后,我们来看一下java process snapshot(jps),我们发现有6个进程,其中NameNode是HDFS的老大,DataNode是HDFS的小弟,ResourceManager是YARN的老大,NodeManager是YARN的小弟,另外SecondaryNameNode是HDFS的NameNode的助理帮助NameNode完成一些数据的同步,主要用来合并fsimage和edits文件等。这说明我们前一节配置的完全正确,一次性我们启动成功!
我们还可以通过浏览器的方式进行验证:
http://192.168.8.88:50070 (hdfs管理界面)
http://192.168.8.88:8088 (yarn管理界面)
我们先在浏览器地址栏输入http://192.168.8.88:50070并回车,我们会进入以下页面,我们可以看到页面最上方便是NameNode的信息,该NameNode目前状态是active状态,说明正常,还有就是由于目前我们配置的是伪分布式,只能有一个NameNode,等到真正的集群时NameNode可能有多个。我们看到下面Cluster Summary表格中有一行是Live Nodes 信息显示它有一个DataNode,我们要查看这个DataNode的详细信息我们便点击Live Nodes链接。
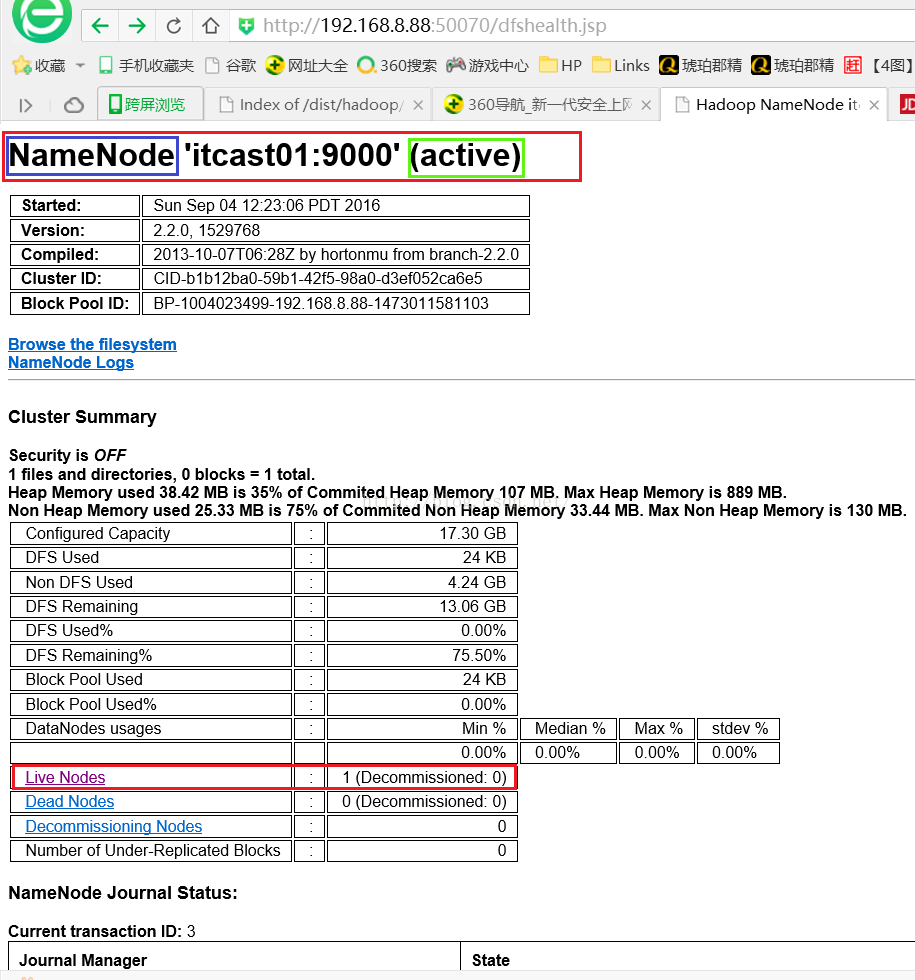
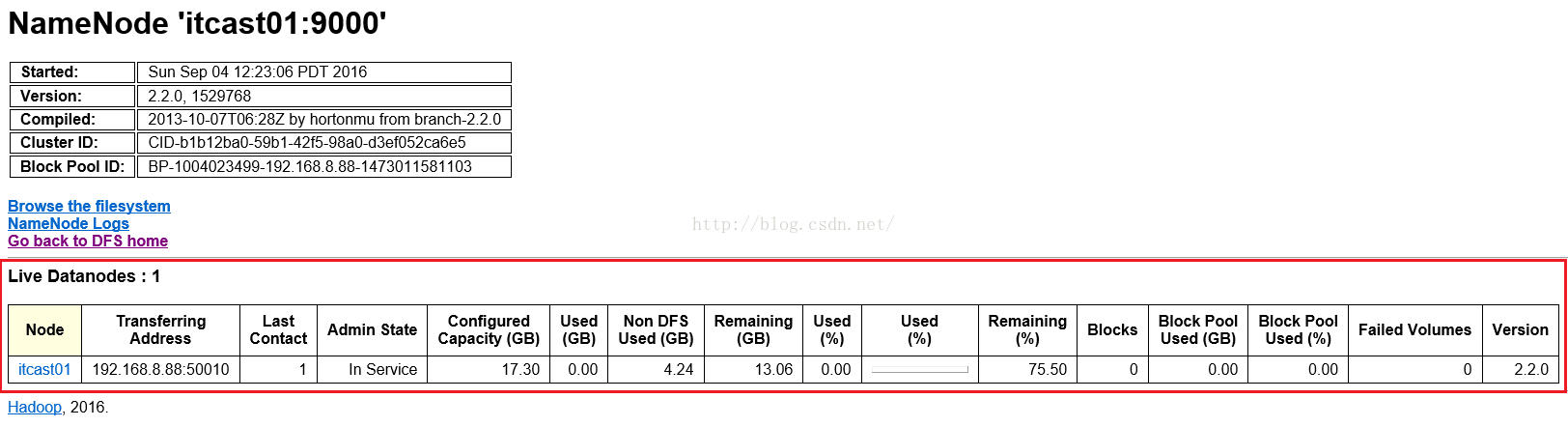
点击Live Nodes后我们进入下面这个子页面,我们可以看到DataNode的详细信息,真正的集群环境下DataNode将会有很多。
接下来我们来查看一下HDFS的文件系统,我们点击"Browse the filesystem",我们会发现无法访问,如下图所示
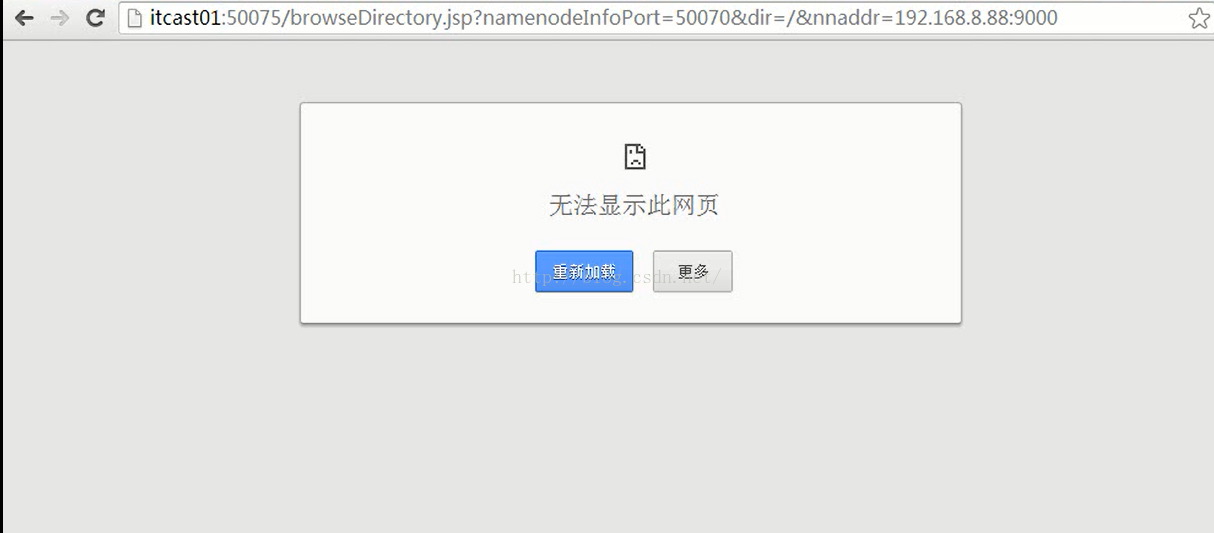
之所以出现如上图那样无法访问的情况,是因为浏览器访问的时候是以主机名的方式访问的,我们Windows系统还没配置过IP和主机名的相关映射,我们
在C:\Windows\System32\drivers\etc目录下可以找到host文件,如下图所示:
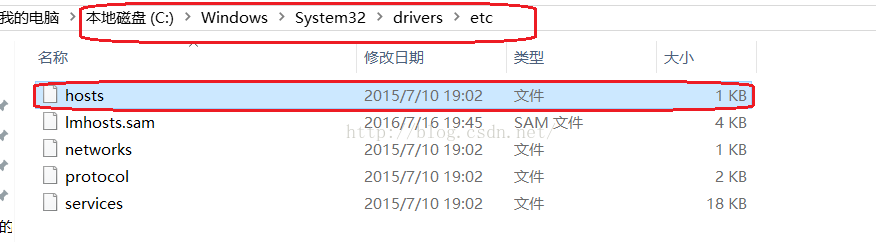
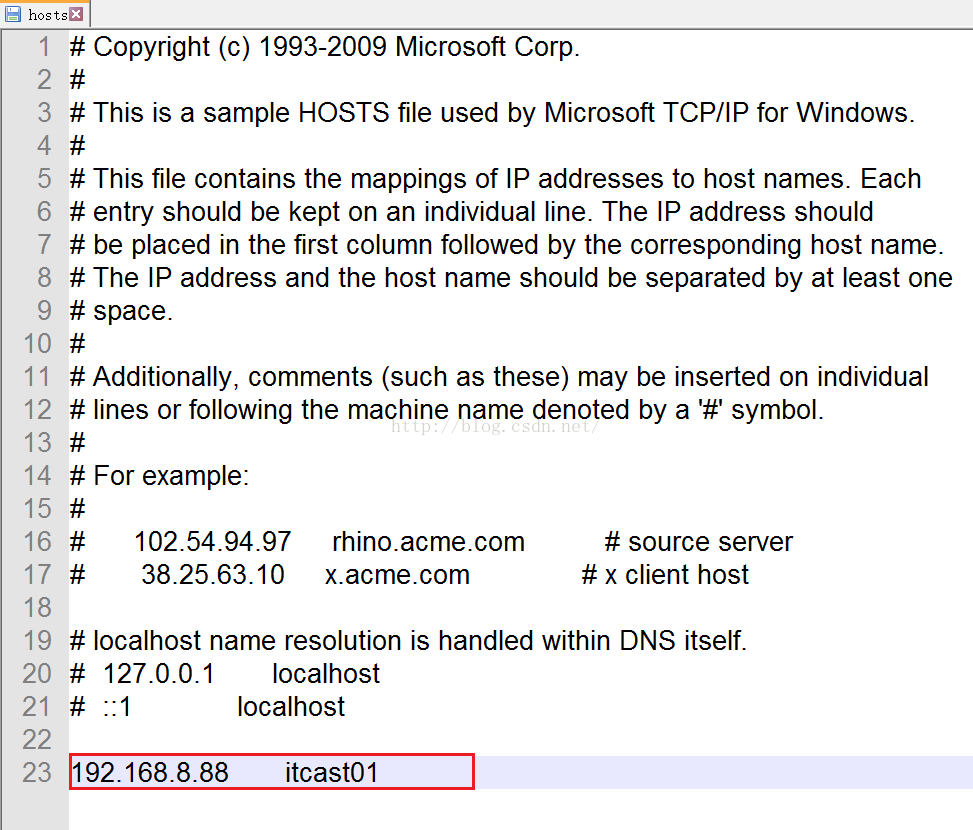
我们打开hosts文件在文件最下方我们配置一下IP和主机名之间的映射关系,如下图所示,保存并关闭文件。
然后我们刷新一下刚才没有加载出来的页面,会发现可以正常显示文件系统了,如下图所示
看完了HDFS的管理界面,我们接着来看yarn的管理界面,在地址栏输入:http://192.168.8.88:8088并回车,就可以看到如下图所示的界面。

接下来我们开始测试HDFS的功能,我们先向HDFS上传一个文件,我们就把JDK上传到HDFS,我们回到root根目录,ls命令查看文件列表,jdk就在该目录下,我们上传时先输入hadoop,如果下面的命令忘了的话可以直接按回车。

我们看到的提示信息如下图所示,从中我们可以看到fs,这个客户端可以进行一些文件操作,因此我们在hadoop命令后加上fs,后面的命令还不知道的话,接着按Enter查看提示信息。
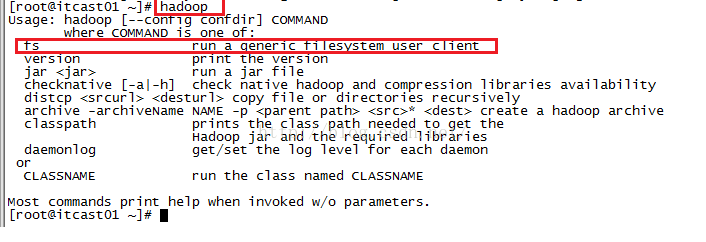
hadoop fs回车后的提示信息如下图所示,我们可以看到有很多命令可用,其中我们很关注的便是上传和下载功能,即下图中的-get和-put命令
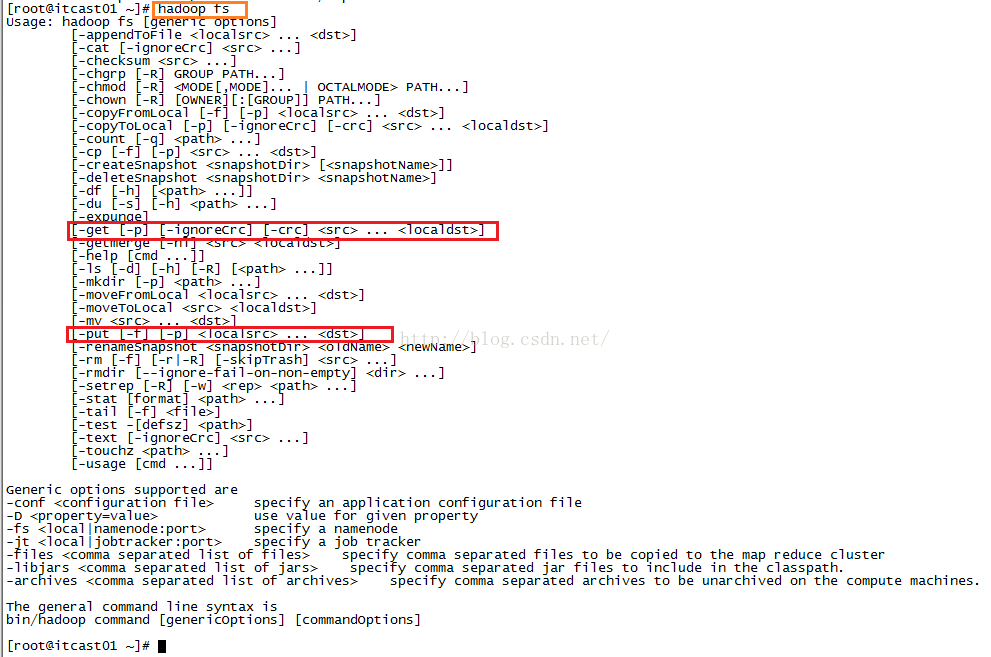
所谓的上传就是把文件从本地文件系统(Linux文件系统)上传到HDFS文件系统,我们用命令:
hadoop fs -put /root/jdk-7u80-linux-x64.gz hdfs://itcast01:9000/jdk,这条命令的意思是从root目录下把jdk文件上传到HDFS系统的根目录下并给文件重命名为jdk。

上传完之后我们便可以到HDFS文件系统进行查看是否刚才上传的文件上传成功了,我们刷新一下:http://itcast01:50075/browseDirectory.jsp?namenodeInfoPort=50070&dir=/&nnaddr=192.168.8.88:9000这个网址,便可以看到我们刚才上传的文件确实已经在HDFS系统当中了。
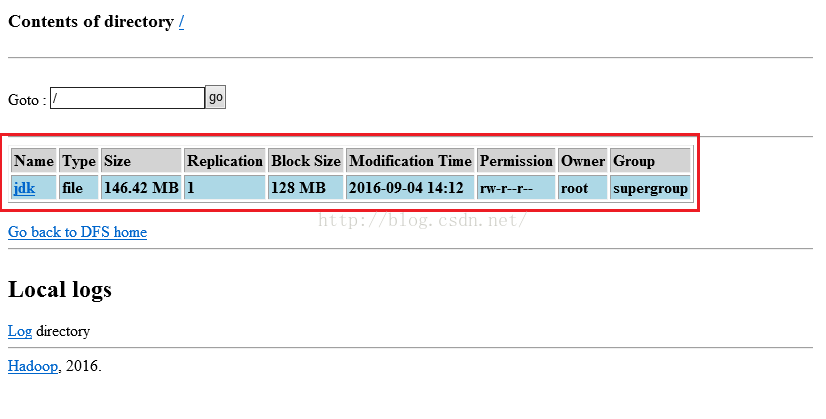
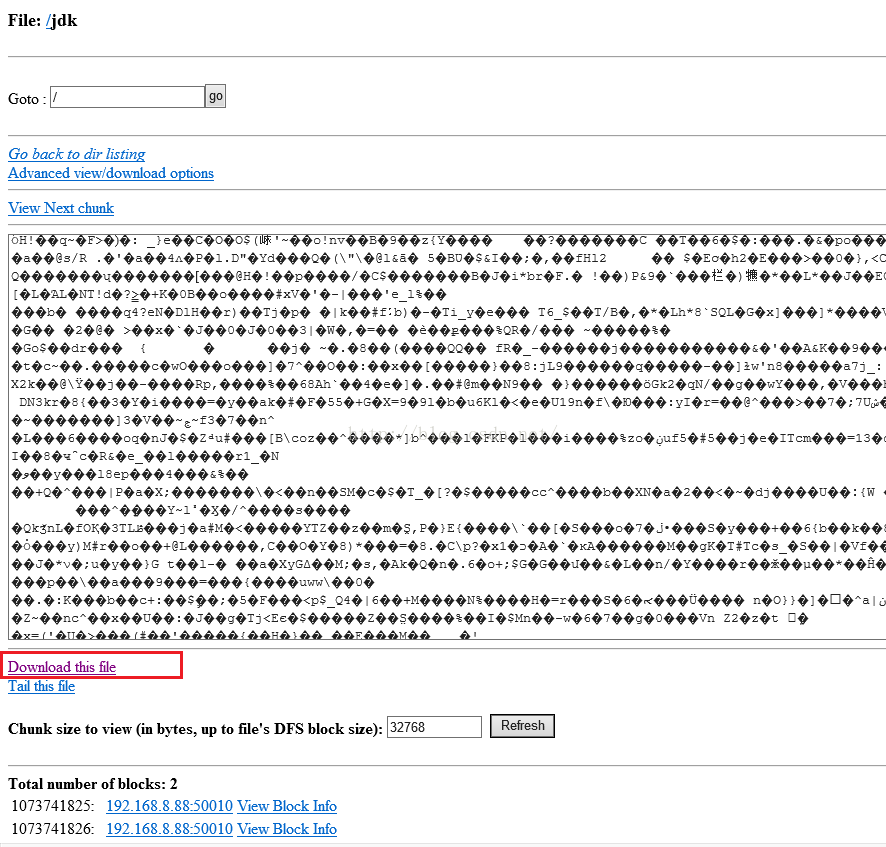
既然可以上传,当然也可以下载,那么我们怎么下载呢,第一种方法是我们点击上图中Name这一列中Jdk的链接,会进入到如下图所示的页面,我们点击下面红色框中的“Download this file”链接,就会弹出下载提示框,我们下载即可。
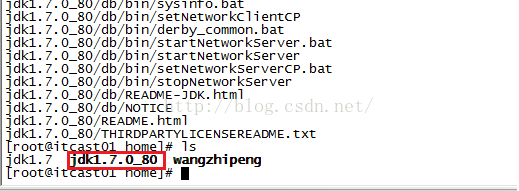
第二种下载方法便是用命令的方式,跟put类似,如下图所示,用命令:hadoop fs -get hdfs://itcast01:9000/jdk /home/jdk1.7,这条命令的意思是从hdfs文件系统的根目录下将jdk文件下载到本地/home/文件夹下并且将名字命名为jdk1.7。

下载到本地的文件我们怎么知道是否已经被损坏了呢,我们只需对该文件进行解压即可,我们使用命令:tar -zxvf jdk1.7进行解压缩,解压完后我们使用ls命令查看该目录当前的所有文件,发现多了jdk1.7.0_80这个文件夹,说明解压成功,同时说明下载的文件没问题。
接着我们测试MR和YARN,我们使用Hadoop官方提供的事例程序进行测试,我们先回到hadoop-2.2.0目录然后一步一步找到hadoop-mapreduce-examples-2.2.0.jar。

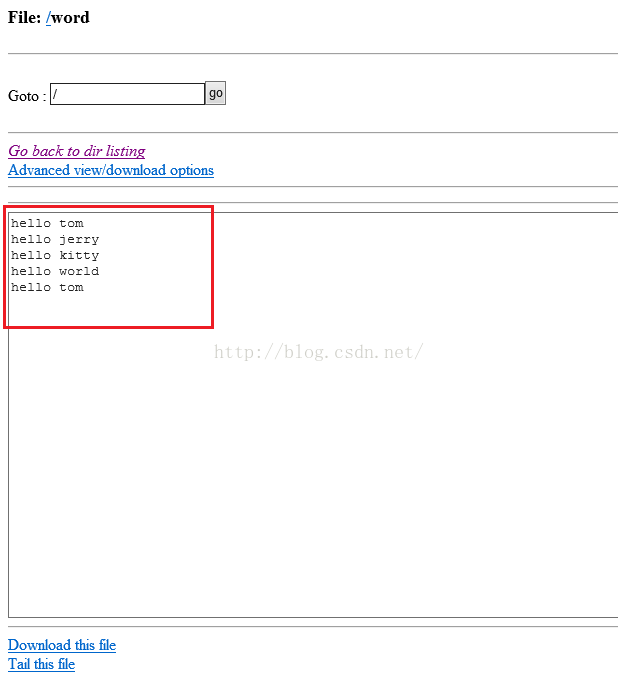
为了进行测试,我们使用命令vim word新建并打开word文件并在文件中插入如下图所示内容,保存并退出。

我们先用linux命令mc word来统计我们刚才输入的内容,下图中的5代表行数,10代表总共有10个单词,56代表的是字符的数量。

接下来我们使用hadoop命令来进行统计,为了防止本地word文件慢慢越来越大,我们把mapreduce目录下的word文件上传到HDFS系统,我们使用的命令是:hadoop fs -put word hdfs://itcast01:9000/word,上传成功后,我们用命令hadoop fs -ls hdfs://itcast01:9000/来查看HDFS根目录下的所有文件,从下图我们可以看到我们刚才上传的word文件确实已经上传到HDFS系统的根目录下了。

我们还可以通过在浏览器中浏览HDFS文件系统列表:http://itcast01:50075/browseDirectory.jsp?dir=%2F&namenodeInfoPort=50070&nnaddr=192.168.8.88:9000
可以看到word文件已在文件列表中。
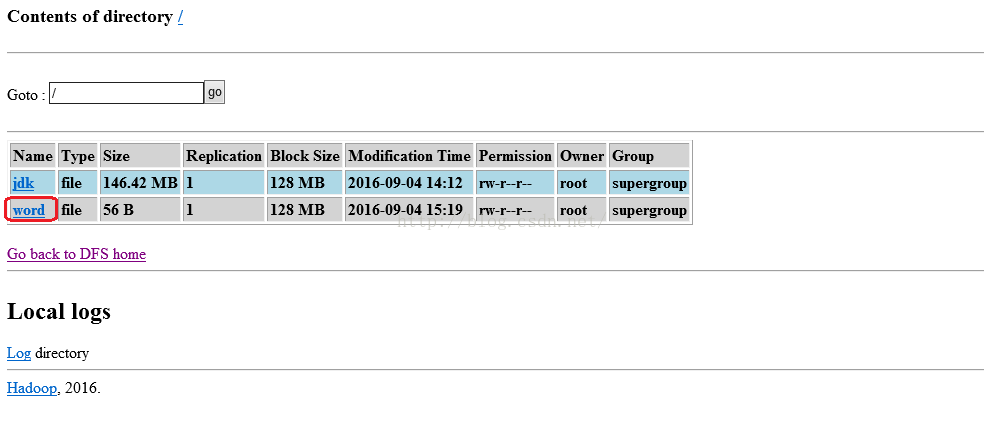
我们点击上图的word链接,进入该文件的具体内容,如下图红色框中的内容,就是我们新建word文件时输入的内容。
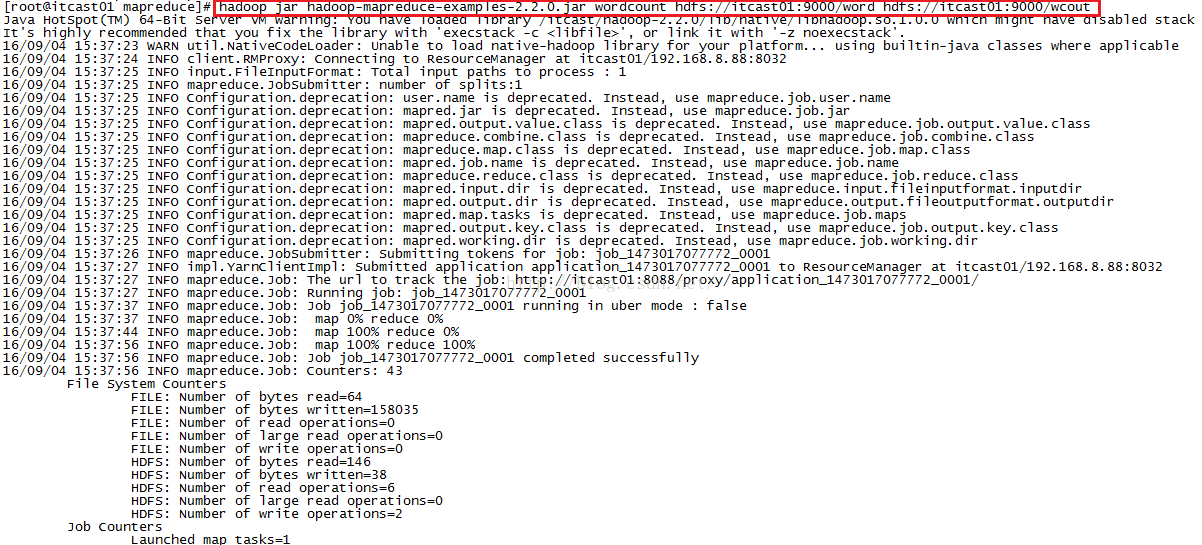
我们正式开始使用hadoop命令来统计我们输入的内容,命令是:
hadoop jar hadoop-mapreduce-examples-2.2.0.jar wordcount hdfs://itcast01:9000/word hdfs://itcast01:9000/wcout,针对这条命令,wordcount就是用来统计单词等信息的,浅蓝色的hdfs://itcast01:9000/word代表的是输入(IN),粉色的hdfs://itcast01:9000/wcout代表的是输出(Out)
命令执行成功之后,我们可以通过浏览器来看,我们依然刷新:http://itcast01:50075/browseDirectory.jsp?dir=%2F&namenodeInfoPort=50070&nnaddr=192.168.8.88:9000这个网址,就可以看到如下图所示的界面,从中可以看到wcout就在文件列表中。
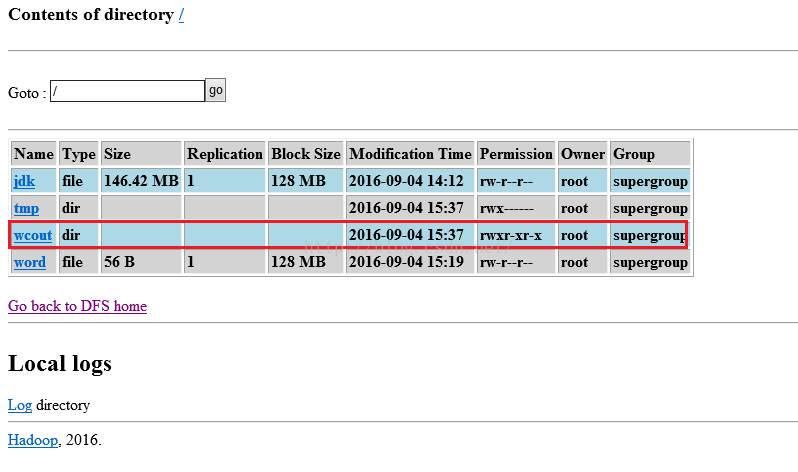
我们点击wcout链接进入到如下图所示的界面,其中SUCCESS表示执行成功,part-r-00000是执行结果文件。
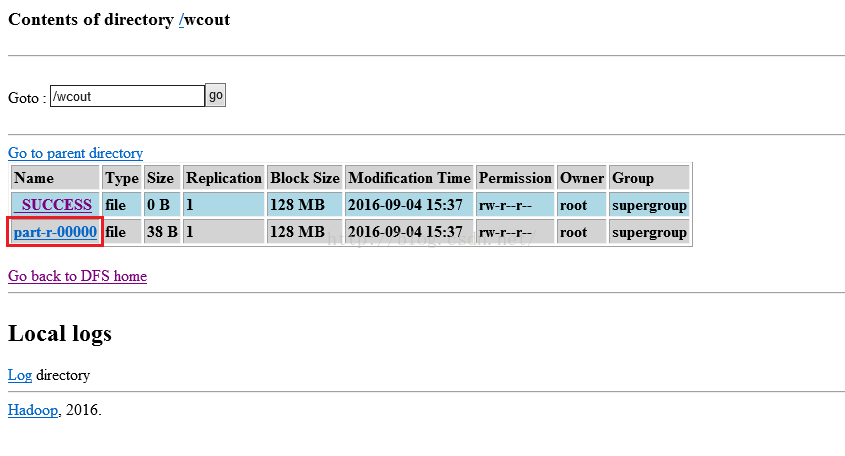
我们点击part-r-00000链接进去,就可以看到如下图所示的统计结果,发现统计结果完全正确!

上面我们的操作完全没有问题,当然,如果在操作中我们出现了这样那样的问题,我们可以通过查看logs文件,logs文件所在的目录是在hadoop-2.2.0下
,如下图所示,logs文件就在其中。我们进入logs文件,查看该目录下的所有日志文件,假如我们要查看namenode的日志,我们便使用命令:more hadoop-root-namenode-itcast01.log并回车,便可以查看。

下图便是namenode的错误日志。
至此,我们本节课便学完了!














 876
876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









