







上一节课我们一起学习了Hadoop自定义排序功能,这节我们一起学习Combiner编程,每一个map可能会产生大量的输出,Combiner的作用就是在map端对输出先合并一次,以减少传输到Reducer的数据量。
combiner最基本是实现本地key的归并,combiner具有类似本地reduce功能。
如果不用combiner,那么所有的结果都是reduce完成,效率会相对低下,使用combiner,先完成的map会在本地聚合,提升速度。
注意:Combiner的输出是Reducer的输入,如果Combiner是可插拔的,添加Combiner决不能改变最终的计算结果,在这种情况下Combiner只适用于那种Reduce的输入key/value和Reduce的输出key/value类型完全一致,且不影响最终结果的场景,比如累加、最大值。当然,Combiner也可以是不可插拔的,也就是说有与没有Combiner最终的计算结果是不一样的,不可插拔的应用场景是数据的筛选,比如我们可以在Map执行之后,Reduce执行之前先对数据进行筛选,把坏数据给过滤掉,这样传到Reduce的数据就都是好的数据了,这样最终的结果肯定是与没有筛选数据的结果是不一样的。
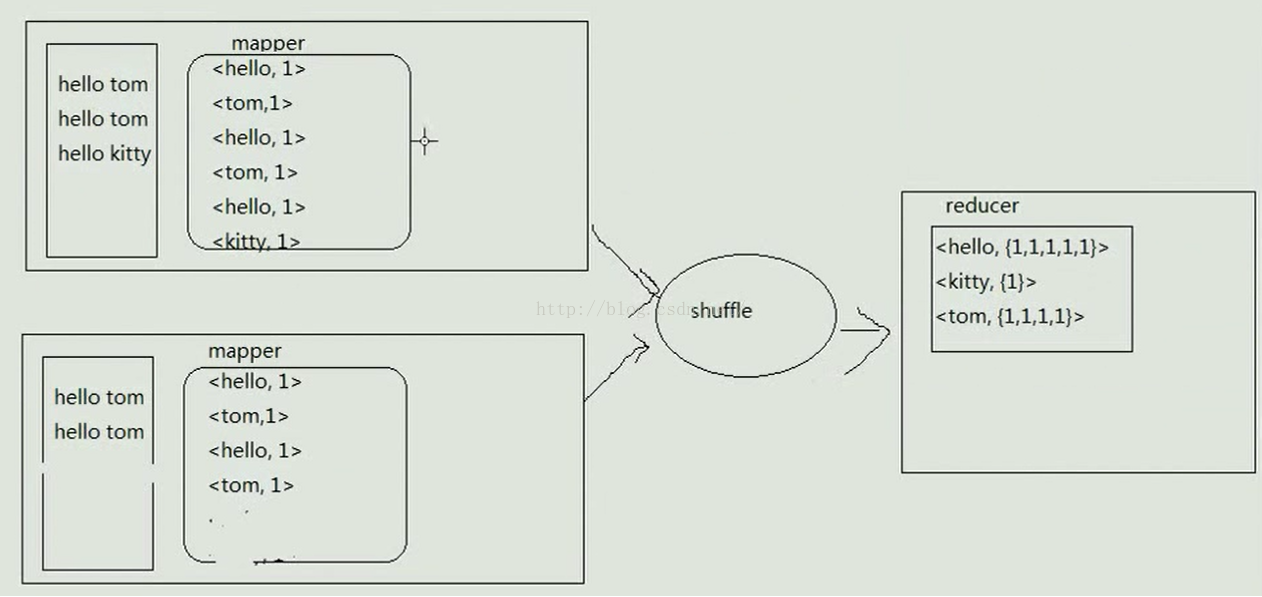
上面说了一堆理论,可能大家还不理解Combiner的作用具体是什么,下面我们画个图来更好的理解Combiner做了什么。我们先来看一张没有Combiner的MapReduce工作原理,比如有两个mapper,第一个mapper读取的文件中有两个hello tom和一个hello kitty,mapper处理完后,数据会被处理成一个一个的map,同理,第二个mapper读取的文件中有两个hello tom,经mapper处理后也变成了一个一个的map,两个mapper处理完之后把结果给shuffle处理,经shuffle处理后结果变为<hello,{1,1,1,1,1}>、<kitty,{1}>、<tom,{1,1,1,1}>,然后交给reducer处理,如下图所示
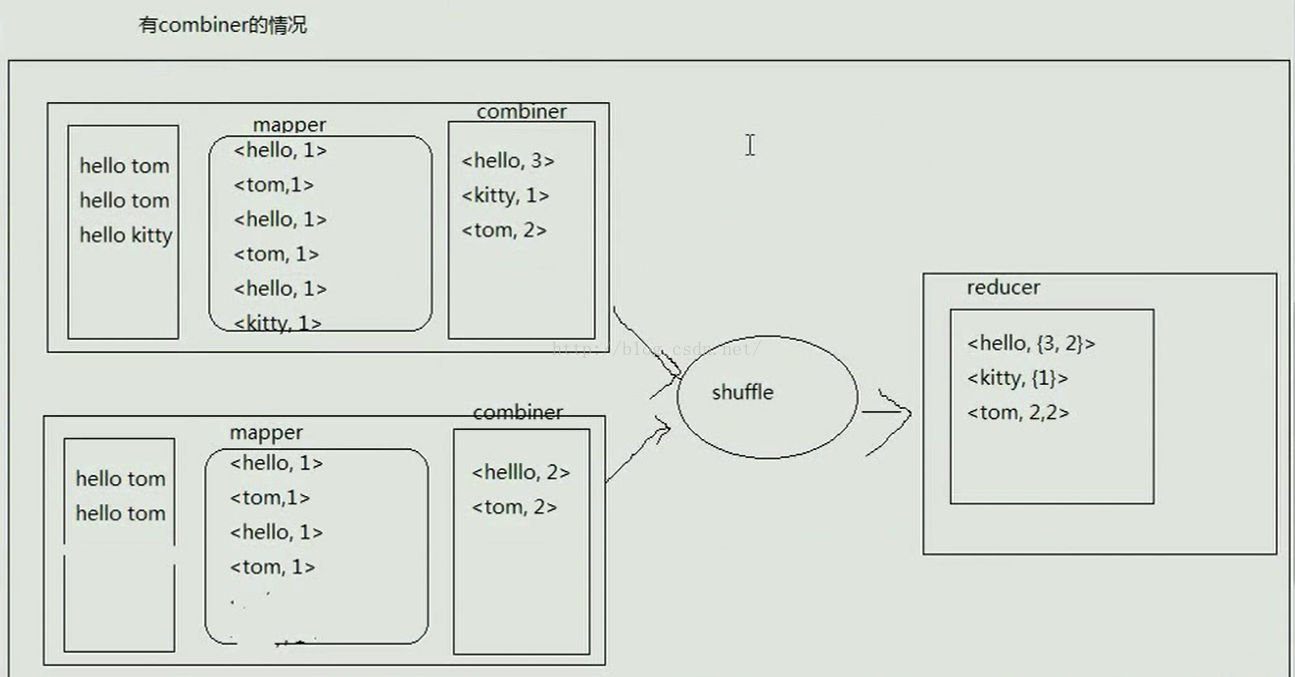
接下来我们再来看一副有Combiner的图片,如下图所示,我们看到Combiner存在的位置是在mapper端,它是在mapper执行完之后进行的,combiner会先对数据合并一下,第一个mapper读取的文件中hello出现3次,kitty出现1次,tom出现2次,因此经combiner处理后的结果是<hello,3>、<kitty,1>、<tom,2>,第二个mapper读取的文件中有两个hello和两个tom,经combiner处理之后的结果是<hello,2>、<tom,2>,然后把这些数据交给shuffle处理,shuffle处理后的结果是<hello,{3,2}>、<kitty,{1}>、<tom,{2,2}>,然后把这些数据交给reducer处理。而且我们可以看到经过Combiner处理后最终的结果并没有变化,这就是可插拔的。
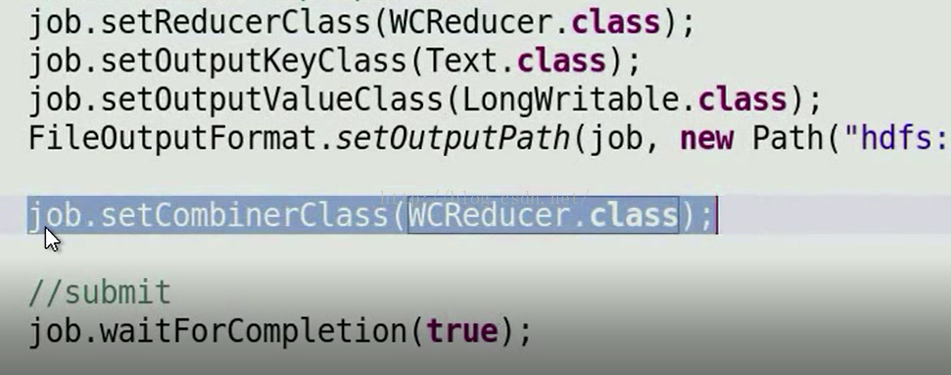
那么我们怎么使用Combiner呢,如下图所示,我们在Job中设置CombinerClass(job.setCombinerClass(WCReeducer.class)),其实Combiner是特殊的Reducer,因此如果是可插拔的话,我们可以把Reducer作为Combiner,如果不可插拔,我们可以定义一个Reducer来处理我们特殊的逻辑,然后在job中进行配置。
至此,我们本小节课便一起学习完了。














 668
668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









