







文件的读取:
#文件的读操作的方法: #(1)readline读取一行,如果设置了读取的字节数,设备的字节数>一行的字节数时,会把一行的数据全部读出,若小于则只读取设置的字节数的大小 #(2)read方法默认读取全部,若设置了size则读取size字节 #(3)readlines 是读取buff的里差不多的大小,返回每一行所组成的列表,这里的size不管取多大,都是返回DEFAULT_BUFFER_SIZE差不多大小的值 #(4)使用iter迭代器来读取全部文件 f=open('/Users/mac/Desktop/test.rtf')
也可以用with open打开,它相当于try...finally,且不用调f.close(),
with open('/Users/mac/Desktop/test.rtf','r') as f:
print(f.read()) print f.readline() print f.readline(100) #读取一行 print f.readline(2) #只读取两2个字节 #使用readlines步骤:1,查看DEFAULT_BUFFER_SIZE模块8192。 # 2.追加test.rtf文件的内容,加到1000行,查看文件的大小ls -l test.rtf,得到大小是10890。大于DEFAULT_BUFFER_SIZE # 3.再次重新打开文件,查看读取的行数, 是否将1000行全部读出,只读出755行 list_c=f.readlines(1) print list_c print len(list_c) #返回755行,计算一下总的字节数:每行是11*755=8305与8192差不多字节,不管readlines(2)size的大小是多少 #查看DEFAULT_BUFFER_SIZE模块 import io print io.DEFAULT_BUFFER_SIZE #返回值是8192 f.close() #4.使用迭代器取全部文件,使用迭代器的好处是:它是把文件内容全部放在迭代器中,而不是放在内存中。当我们调用next方法时,才会把迭代器中的一条 #条内容放到内存中。故只要遍历读取迭代器的内容,就会遍历一条条写入到内存中。不消耗内存 f=f=open('/Users/mac/Desktop/test.rtf') iter_f=iter(f) lines=0 for line in iter_f: lines +=1 print line print lines #读出1000行
文件的写入:
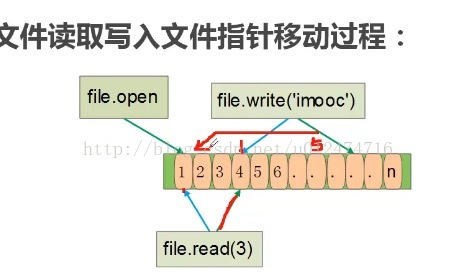
#文件的写操作的方法:#(1)write(str):将字符串写入文件 #(2)writelines(sequence of string):写入多行,参数为可迭代对象,包括字符串,字符串组成的元组,字符串组成的列表,字符串组成的迭代器 #文件的写操作出现的问题:(1)文件写入有个缓存机制,如果文件的长度<这个文件的缓存的size,它会先放在缓存中,调用close或者flush函数才会写入到磁盘 # (2)当写入的文件>这个文件的系统缓存,它会先把写满缓存的同时写入磁盘,这个时候查看文件已经写入了,不用调用close或者flush方法 # 缓存腾出来存剩下的。这个剩下的要调用close或者flush函数才可以写入到磁盘 #方法1: write方法 f=open('/Users/mac/Desktop/test.rtf','w') f.write('jolingtest') f.close() r=open('/Users/mac/Desktop/test.rtf') print r.read() #方法2:writelines方法 f=open('/Users/mac/Desktop/test.rtf','w') # f.writelines((1,2,3)) #报错,因为参数不是字符串组成的元组 f.writelines(('1','2','3')) #成功写入 f.writelines(['1','2','3']) #成功写入 f.close() # 写缓存,当写入数据量<缓存,则要调用close 和 flush来将缓存写入到磁盘 f=open('/Users/mac/Desktop/test.rtf','w') f.write('kkkktest') # r=open('/Users/mac/Desktop/test.rtf') # print r.read() #查看文件没有写入 f.close() #调用close或flush才会把缓存写入到磁盘 r=open('/Users/mac/Desktop/test.rtf') print r.read() #查看文件已经写入 # 写缓存,当写入数据>=缓存,则会把缓存中的数据同时同步到磁盘上,后面多出的缓存再次将剩下的数据写入到缓存时,才要调用close和flush f=open('/Users/mac/Desktop/test.rtf','w') for i in range(100000): f.write('test write'+str(i)+'\n') #在后台用ls -l test.rtf 文件的大小:155648个字节 #在后台用vi test.rtf查看文件,只写到了test write 9796行,故此时磁盘已经满了,所以它先将满的缓冲区直接同步到磁盘, #此时空出缓冲区存剩下的数据,故剩下的数据还没有让缓冲区满,故要调用close方法将剩下的写入到磁盘 f.close() #在后台用ls -l test.rtf 文件的大小:15889个字节,比原来的大 #vi test.rtf,查看最后一行shift+G查看,全部已经写入到磁盘了文件的关闭:文件要关闭的三个原因:1.将写缓存同步到磁盘 2.linux系统中每个进程打开文件的个数是有限的 3.如果打开文件数到了系统限制,在打开文件后会失败打开文件超过限制的实例:""" 1.打开文件,查看系统最大的文件打开值,在命令行中,ps,查看python的进程号PID,查看该进程的cat /proc/20384/ 下面的相关属性 查看limit属性:cat /proc/20384/limits 查看max open files 对应的值soft Limit是1024,故只能打开1024个文件 2.打开一个文件,查看是否到1024个的时候就无法再打开了 """ #2.打开一个文件,查看是否到1024个的时候就无法再打开了 list_f=[] for i in range(1025): list_f.append(open(("/Users/mac/Desktop/test.rtf"),'w')) print "%d:%d" %(i,list_f[i].fileno()) #结果是:1017:1023 后就报Too mangy open files:错误文件指针:#文件指针的操作: seek(offset,whence):移动文件指针 offset:偏移量,可以是负数 whence:偏移相对位置文件指针定位方式有三种: os.SEEK_SET:相对文件起始位置; os.SEEK_CUR:相对文件当前位置; os.SEEK_END:相对文件结尾位置#tell()函数是查看文件指针当前指向的位置 import os f=open('/Users/mac/Desktop/test.rtf','r+') print f.tell() print f.read(3) f.seek(0,os.SEEK_SET) #从文件起始位置 print f.tell() print f.read(3) f.seek(0,os.SEEK_END) #从文件末尾开始读取第0个 f.tell() #此时返回的当前位置应该是末尾,即文件的长度 #ls -l test.rtf查看文件的长度是否和上面的f.tell()一样 f.read() f.seek(-5,os.SEEK_END) #从末尾往前读5位开始读取 f.tell() print f.read() f.tell() #到文件的最后一位 f.seek(-19,os.SEEK_END) #若文件里总共就18个字符,要往前读19位,肯定会报错python文件属性及OS模块使用:os模块用于提供跨操作系统的、可以移植的操作,若想你的代码可以用于所有操作系统,可以用OS模块eg:f=open('/Users/mac/Desktop/test.rtf') print f.fileno() print f.mode print f.closed f.close()(1)python 标准文件有以下三类:文件标准输入:sys.stdin 文件标准输出:sys.stdout 文件标准错误:sys.stderr import sys type(sys.stdin) print sys.stdin.mode #它是只读的 sys.stdin.read() #它是空值 sys.stdin.fileno() #返回值为0 a=raw_input("a:") #它实际上是调用了stdin输入,输入到控制台 #输入00000,此时在终端控制台打印出来a是0000 sys.stdout.mode #它是只写的,'w' sys.stout.write('1000') #打印会输出到控制台,它其它是和print一样 print '1111' #它会调用stout sys.stdout.fileno() #返回1 sys.stderr.mode #它是只写,'w' sys.stderr.write('1000') #控制台会返回1000, sys.stderr.fileno() #返回值2(2)python 文件命令行参数:sys模块提供sys.argv属性,通过该属性可以得到命令行参数 sys.argv:字符串组成的列表 import sys if __name__=='__main__': print len(sys.argv) for arg in sys.argv: print arg #运行python arg.py 0,1,2,3 输入参数import codecs f=open('/Users/mac/Desktop/test.rtf','r+') f.read() f.write('1,2,3') # f.write(u'生活') #报'ascii' codec can't encode #方法一,将Ascii码转换成utf-8 a=unicode.encode(u'生活','utf-8') #将unicode转换成utf-8后再写入 print a f.write(a) f.read() f.close() # 方法二:使用codecs模块提供的方法创建指定编码格式的文件 # open(fname,mode,encoding) f=codecs.open('/Users/mac/Desktop/test.rtf','w','utf-8') print f.encoding #返回utf-8 f.write(u'学习') #不会像上面一样报错,且写入成功 import os f.seek(0,os.SEEK_SET) #文件指针移到最开始位置 # print f.read() #用read方法会报File not open #可用command端cat test.rtf文件查看是否正确写入 f.close()(3)os模块方法和os path方法介绍import os #用os文件系统创建文件并以读写方式打开,和read,write,seek基本一样,只是偏向更底层 #linux中把所有外围设备都包装成一个统一的接口,当我们调用open时会调用此接口 fd=os.open('imoc.txt',os.O_CREAT | os.O_RDWR) # os.write(fd,'immooc') l=os.lseek(fd,0,os.SEEK_SET) print(l) str1=os.read(fd,5) os.close(fd) #os模块方法介绍 """ os.listdir(os.getcwd()):获得当前目录再获得当前目录下的所有文件 access(path,mode):判断文件权限,F_OK存在,权限:R_OK,W_OK,X_OK listdir(path):返回当前目录下所有文件组成的列表 remove(path):删除文件 rename(old,new):修改文件或者目录名 mkdir(path,mode):创建目录 makedirs(path,mode):创建多级目录 removedirs(path):删除多级目录 rmdir(path):删除目录(目录必须空目录) """ print(os.access('imoc.txt',os.R_OK)) print(os.listdir('./')) print(os.rename('imoc.txt','imoc1.txt')) print(os.remove('imoc.rtf')) os.mkdir('test') os.makedirs('test/test1/test2') os.removedirs('test') #会报Directory not empty: 'test'错误 os.removedirs('test/test1/test2') #整个路径写全了才可以删除成功 #os.path模块方法介绍 """ split():用来返回路径目录名和文件名 exists(path):当前路径是否存在 isdir(s):是否是一个目录 isfile(path):是否是一个文件 getsize(filename):返回文件大小 dirname(p):返回路径的目录 basename(p):返回路径的文件名 join(path,name):将目录与文件名或者目录等连接起来#路径拆分为两部分,后一部分总是最后级别的目录和文件名 os.path.split("/User/mic/dir/test.txt") #拆分返回的是扩展名 os.path.splitext("/User/mic/dir/test.txt")"""print(os.path.exists('./imoc.txt'))print(os.path.isdir('imoc.txt'))print(os.path.isdir('./'))print(os.path.isfile('imoc.txt'))print(os.path.getsize('imoc.txt'))print(os.path.basename('./imoc.txt'))print(os.path.dirname('./imoc.txt'))#列出所有.py的文件[x for x in os.listdir('.') if os.path.isfile(x) and os.path.splitext(x)[1]=='.py']














 471
471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









