







1. 背景知识介绍
函数的风险
给定关于
X
X
和 的空间,学习一个函数
h:X→Y
h
:
X
→
Y
,函数的输入
x∈X
x
∈
X
,输出
y∈Y
y
∈
Y
。要学习函数
h
h
,需要有样本: ,其中
xi∈X,yi∈Y
x
i
∈
X
,
y
i
∈
Y
,我们的目标是学习到
h(xi)
h
(
x
i
)
。
形式化的描述如下:假定
X
X
和 服从概率分布
P(x,y)
P
(
x
,
y
)
,含有
m
m
个样本的训练集 是从分布
P(x,y)
P
(
x
,
y
)
依据独立同分布原则采样得来。这里关于概率分布
P(x,y)
P
(
x
,
y
)
的假设,使得我们可以对预测的不确定性进行建模,因为
y
y
并不是关于 的一个确定函数,而是一个随机变量,对于给定的
x
x
,服从分布 。
同时也假设,已经有一个非负实数损失函数
L(y^,y)
L
(
y
^
,
y
)
,这个函数度量了预测值
y^
y
^
和实际值
y
y
的偏差大小。
关于 的风险定义如下:
学习问题的最终目标是,在固定的函数空间 H H 中学习到这样的函数 h∗ h ∗ ,使得 R(h) R ( h ) 值最小化:
经验风险最小化(Empirical risk minimization)
通常情况,由于分布
P(x,y)
P
(
x
,
y
)
是未知的,风险函数
R(h)
R
(
h
)
也是未知的。因此,我们使用经验风险作为对风险函数的近似:
经验风险最小化原则表明,我们要找的函数 h∗ h ∗ 应满足:
因此,给予ERM的学习算法变成了解决如上的优化问题。
加法模型
加法模型定义如下:
其中, b(x;γm) b ( x ; γ m ) 为基函数, γm γ m 为基函数的参数, βm β m 为基函数的系数。
在给定训练数据及 L(y,f(x)) L ( y , f ( x ) ) 的条件下,学习加法模型 f(x) f ( x ) 成为经验风险极小化即损失函数极小化问题:
前向分布算法
由于对加法模型的求解是一个复杂的优化问题,因而采用前向分布算法来对加法模型进行求解。
前向分布算法的想法是:因为学习的是加法模型,如果能从前向后,每一步只学习一个基函数及其系数,逐步逼近优化目标函数式,那么就可以简化优化的复杂度。具体的,每步只需优化如下损失函数:
给定训练数据集 T={(x1,y1),(x2,y2),…,(xN,yN)} T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x N , y N ) } , xi∈X⊆Rn x i ∈ X ⊆ R n , yi∈Y={−1,+1} y i ∈ Y = { − 1 , + 1 } 。损失函数 L(y,f(x)) L ( y , f ( x ) ) 和基函数的集合 {b(x;γ)} { b ( x ; γ ) } ,学习加法模型 f(x) f ( x ) 的前向分布算法如下:

2.提升树(Boosting tree)
提升树模型介绍

提升树算法

3.梯度提升(Gradient boosting)
模型介绍

算法介绍

3.XGBoost
模型介绍
梯度提升算法中,使用了对函数的梯度来作为参数,这样就不能在使用传统的优化算法。因此,作者提出了xgboost以解决这一问题。先考虑如下的优化目标:
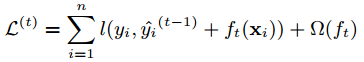
其中, y^(t) y ^ ( t ) 是第i个样本在第t轮迭代时的预测值, ft(xi) f t ( x i ) 是待求的参数。
这里,记 F(x)=l(yi,x) F ( x ) = l ( y i , x ) ,那么 l(yi,y^(t−1)i+ft(xi))=F(y^(t−1)i+ft(xi)) l ( y i , y ^ i ( t − 1 ) + f t ( x i ) ) = F ( y ^ i ( t − 1 ) + f t ( x i ) ) ,这里使用泰勒展开,取前三项近似得到 F(y^(t−1)i+ft(xi))≃F(y^(t−1)i)+F′(y^(t−1)i)∗ft(xi)+12F′′(y^(t−1)i)∗ft(xi)∗f2t(xi) F ( y ^ i ( t − 1 ) + f t ( x i ) ) ≃ F ( y ^ i ( t − 1 ) ) + F ′ ( y ^ i ( t − 1 ) ) ∗ f t ( x i ) + 1 2 F ″ ( y ^ i ( t − 1 ) ) ∗ f t ( x i ) ∗ f t 2 ( x i ) ,因此 L(t) L ( t ) 中对函数的梯度,就转换成了 F F 函数对常数 的一阶、二阶导数。
参考李航著《统计学习方法》和此博客














 4130
4130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









