









平时任务实在比较忙,只能先记录简单步骤,后续再写详细说明。
win7下eclipse中开发统一局域网内hbase程序简单操作步骤
win7下管理统一局域网内的集群
1.3台ubuntu服务器作为实验机器,一台win7作为管理机器,网线都在同一个交换机上。
2.3台主机关闭防火墙,并开通ssh服务。
3.在win7上安装xshell 用来进行命令操作3台主机。安装winscp来进行文件上传等操作。
ubuntu和win7安装配置
一、运行平台
hbase服务器端:Ubuntu 14.04 64位;Hadoop2.8.1;HBASE1.3.1;JAVA 1.8;
hbase客服端:windows64位;JAVA1.8;eclipse客户端 ;
二、linux服务器端环境配置
1、 安装java 1.8软件(略)
1)下载java软件
2)安装java 8
3)验证安装的java版本
java –version #执行后会输出java版本信息
3、 安装配置Hadoop
1)下载
2)安装和配置安装参考
3、 安装配置HBASE
1)下载hbase-1.3.1
2)解压
3)配置hbase分布式安装参考
到此,hbase服务器端的配置已完成。
三、windows客服端配置
1、下载安装java 1.8并且配置好环境变量。
2、下载安装eclipse,最好为最新版。
3、客户端java程序设置
1)找到运行hbase程序所需要的jar包,我通过pom.xml文件导入
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>storm_hbase</groupId>
<artifactId>lab</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>lab</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<storm.version>1.0.1</storm.version>
<!-- 开发调试时配置为compile,topology打包时配置为provided -->
<storm.scope>provided</storm.scope>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.7</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${storm.version}</version>
<scope>${storm.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.2</version>
</dependency>
</dependencies>
</project>
2)将hbase文件下conf文件下的hbase-site.xml文件拷贝一份,放入为其单独建一个文件夹中。
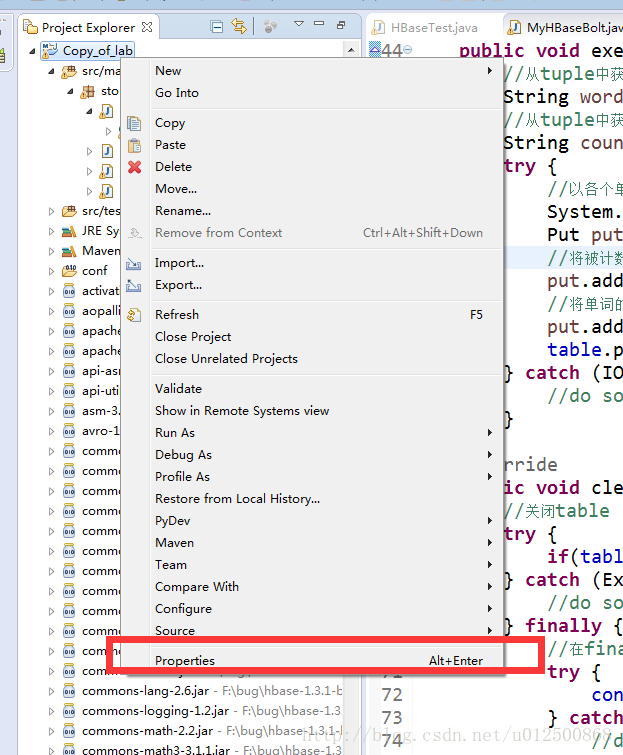
3)将hadoop和hbase下的配置文件复制到项目下自己建立的config文件里,并且导入。
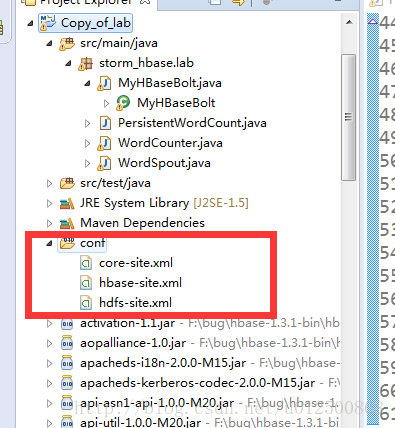
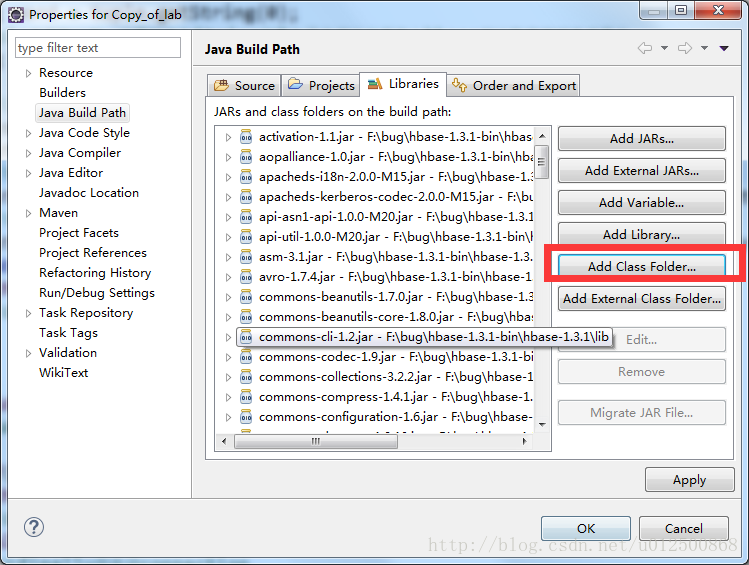
5)Windows下hosts文件
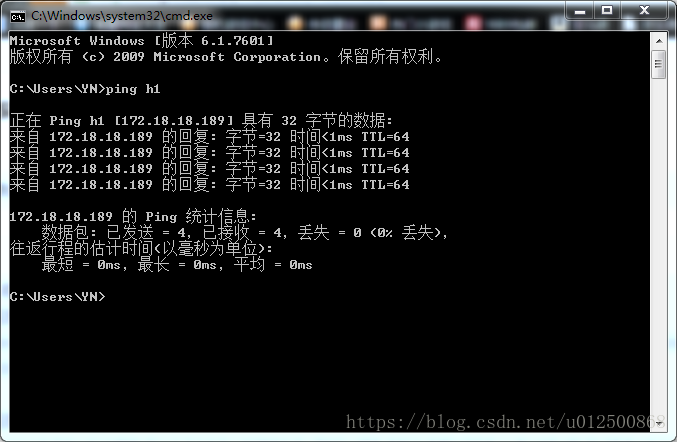
在win7下C:\Windows\System32\drivers\etc中找到hosts文件,添加集群的hostname解析。其中,前半部分表示IP地址,后半部分表示机器名字,根据实际情况进行修改。 这里不要写错,可以先通过ping命令测试是否eclipse能和集群联通。
6)测试代码:首先通过hbase shell建立表和列族结构,然后运行程序,注意程序中的表名要和自己建立的表名一致。
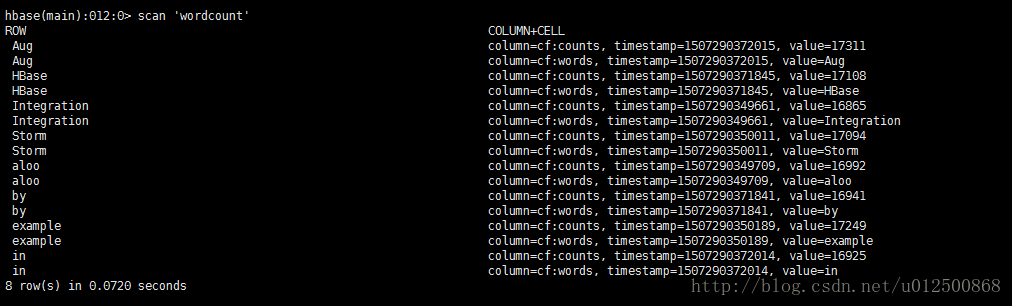
在hbase shell中可以看到,程序计算结果已经写入。

最后贴出代码,代码不是自己写的,也是网上的大神写的,可以根据需要进行改动。
topo
package storm_hbase.lab;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
public class PersistentWordCount {
private static final String WORD_SPOUT = "WORD_SPOUT";
private static final String COUNT_BOLT = "COUNT_BOLT";
private static final String HBASE_BOLT = "HBASE_BOLT";
public static void main(String[] args) throws Exception {
// System.setProperty("hadoop.home.dir","E:/BaiduYunDownload");
Config config = new Config();
WordSpout spout = new WordSpout();
WordCounter bolt = new WordCounter();
MyHBaseBolt hbase = new MyHBaseBolt();
// wordSpout ==> countBolt ==> HBaseBolt
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(WORD_SPOUT, spout, 1);
builder.setBolt(COUNT_BOLT, bolt, 1).shuffleGrouping(WORD_SPOUT);
builder.setBolt(HBASE_BOLT, hbase, 10).fieldsGrouping(COUNT_BOLT, new Fields("word"));
if (args.length == 0) {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word", config, builder.createTopology());
Thread.sleep(10000);
cluster.killTopology("word");
cluster.shutdown();
System.exit(0);
} else {
config.setNumWorkers(3);
StormSubmitter.submitTopology(args[0], config, builder.createTopology());
}
}}spout
package storm_hbase.lab;
import java.util.Map;
import java.util.Random;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
public class WordSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private static final String[] MSGS = new String[]{
"Storm", "HBase", "Integration", "example", "by ", "aloo", "in", "Aug",
};
private static final Random random = new Random();
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
public void nextTuple() {
String word = MSGS[random.nextInt(8)];
collector.emit(new Values(word));
System.out.println(word);
}
}
wordcountbolt
package storm_hbase.lab;
import java.util.HashMap;
import java.util.Map;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
public class WordCounter extends BaseBasicBolt {
private Map<String, Integer> _counts = new HashMap<String, Integer>();
public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getString(0);
int count;
if(_counts.containsKey(word)){
count = _counts.get(word);
} else {
count = 0;
}
count ++;
_counts.put(word, count);
collector.emit(new Values(word, count));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
hbasebolt
package storm_hbase.lab;
import java.io.IOException;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Tuple;
public class MyHBaseBolt extends BaseBasicBolt {
private Connection connection;
private Table table;
public void prepare(Map stormConf, TopologyContext context) {
Configuration config = HBaseConfiguration.create();
//
// HBaseAdmin admin = new HBaseAdmin(config);
// admin.createTable("WordCount");
try {
connection = ConnectionFactory.createConnection(config);
//示例都是对同一个table进行操作,因此直接将Table对象的创建放在了prepare,在bolt执行过程中可以直接重用。
table = connection.getTable(TableName.valueOf("wordcount"));
} catch (IOException e) {
//do something to handle exception
}
}
public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {
//从tuple中获取单词
String word = tuple.getString(0);
//从tuple中获取计数,这里转换为String只是为了示例运行后存入hbase的计数值能够直观显示。
String count = tuple.getInteger(1).toString();
try {
//以各个单词作为row key
System.out.println(word);
Put put = new Put(Bytes.toBytes(word));
//将被计数的单词写入cf:words列
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("words"), Bytes.toBytes(word));
//将单词的计数写入cf:counts列
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("counts"), Bytes.toBytes(count));
table.put(put);
} catch (IOException e) {
//do something to handle exception
}
}
@Override
public void cleanup() {
//关闭table
try {
if(table != null) table.close();
} catch (Exception e){
//do something to handle exception
} finally {
//在finally中关闭connection
try {
connection.close();
} catch (IOException e) {
//do something to handle exception
}
}
}
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
//示例中本bolt不向外发射数据,所以没有再做声明
}
}














 619
619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









