









1. 展开计算图
循环神经网络使用下面的公式定义隐藏单元的值。 为了表明状态是网络的隐藏单元,我们使用变量 h 代表状态重写:
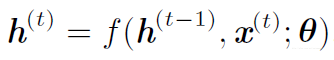
上式可以用两种不同的方式绘制。 一种方法是为可能在模型的物理实现中存在的部分赋予一个节点,如生物神经网络。 在这个观点下,网络定义了实时操作的回路,如下图的左侧,其当前状态可以影响其未来的状态。 在本章中,我们使用回路图的黑色方块表明在时刻
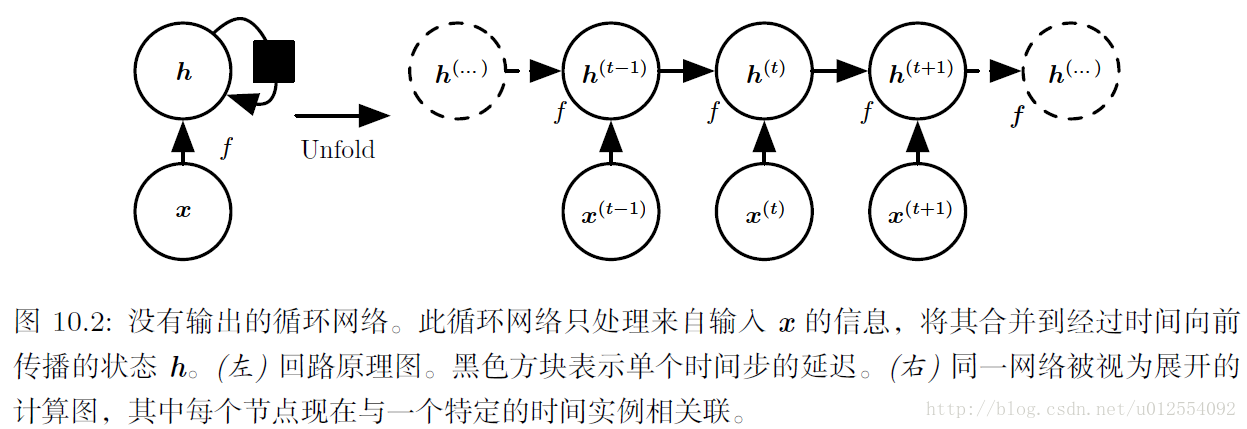
2. 循环神经网络
循环神经网络中一些重要的设计模式包括以下几种:
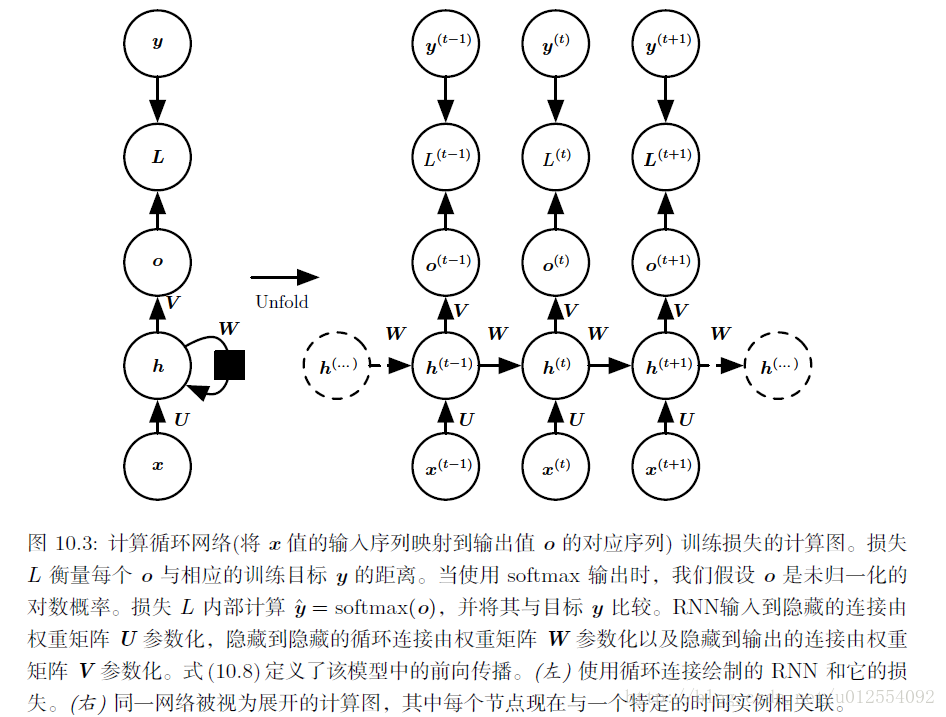
a. 每个时间步都有输出,并且隐藏单元之间有循环连接的循环网络:
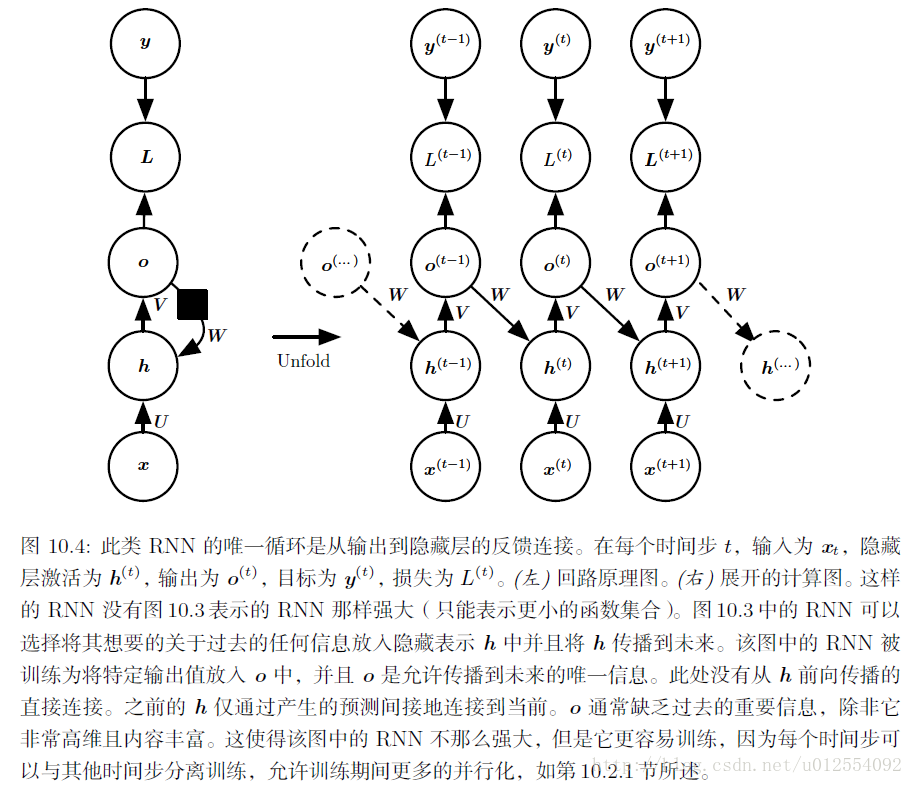
b. 每个时间步都产生一个输出,只有当前时刻的输出到下个时刻的隐藏单元之间有循环连接的循环网络:
c. 隐藏单元之间存在循环连接,但读取整个序列后产生单个输出的循环网络:
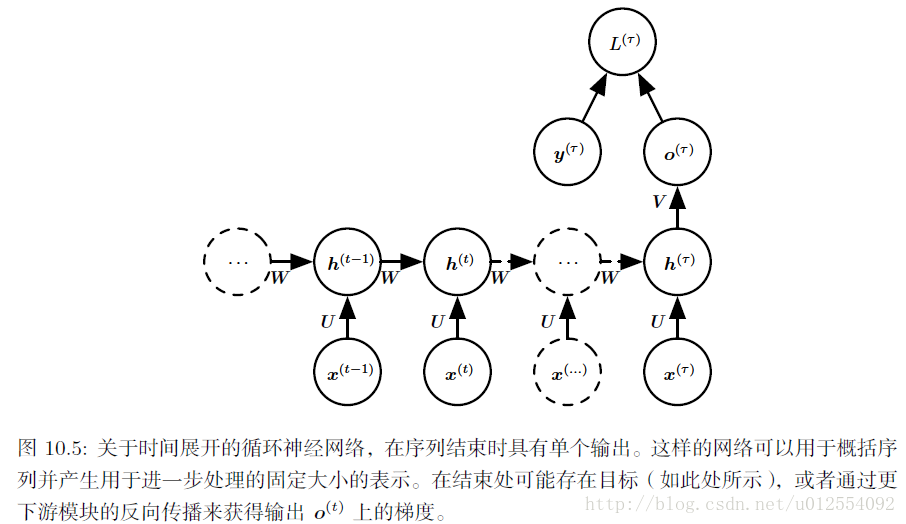
RNN从特定的初始状态 h(0) 开始前向传播。 从 t=1 到 t=τ 的每个时间步,我们应用以下更新方程:
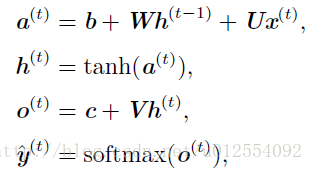
其中的参数的偏置向量
b
和
L(x(1),…,x(τ),y(1),…,y(τ))
=∑tL(t)
=−∑tlogpmodel(y(t)∣x(1),…,x(t))
其中 pmodel(y(t)∣x(1),…,x(t)) 需要读取模型输出向量 y^(t) 中对应于 y(t) 的项。 关于各个参数计算这个损失函数的梯度是计算成本很高的操作。 梯度计算涉及执行一次前向传播(如在10.3展开图中从左到右的传播),接着是由右到左的反向传播。 运行时间是 O(τ) ,并且不能通过并行化来降低,因为前向传播图是固有循序的;每个时间步只能一前一后地计算。 前向传播中的各个状态必须保存,直到它们反向传播中被再次使用,因此内存代价也是 O(τ) 。 应用于展开图且代价为 O(τ) 的反向传播算法称为通过时间反向传播(BPTT)。 因此隐藏单元之间存在循环的网络非常强大但训练代价也很大。
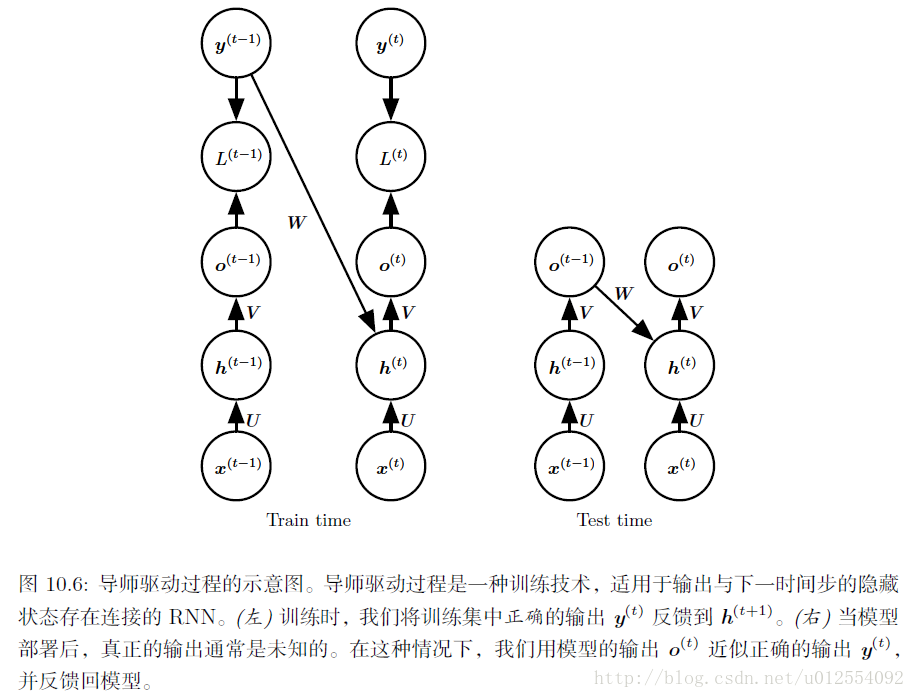
导师驱动过程和输出循环网络:
我们使用导师驱动过程的最初动机是为了在缺乏隐藏到隐藏连接的模型中避免通过时间反向传播。只要模型一个时间步的输出与下一时间步计算的值存在连接,导师驱动过程仍然可以应用到这些存在隐藏到隐藏连接的模型。然而,只要隐藏单元成为较早时间步的函数,BPTT 算法是必要的。因此训练某些模型时要同时使用导师驱动过程和BPTT。
计算循环神经网络的梯度:
我们假设输出
o(t)
作为softmax函数的参数,我们可以从softmax函数可以获得关于输出概率的向量
y^
。 我们也假设损失是迄今为止给定了输入后的真实目标
y(t)
的负对数似然。 对于所有
i,t
,关于时间步
t
输出的梯度
(∇o(t)L)i=∂L∂o(t)i
=∂L∂L(t)∂L(t)∂o(t)i
=y^(t)i−1i,y(t)
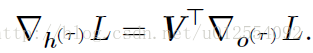
然后,我们可以从时刻 t=τ−1 到 t=1 反向迭代, 通过时间反向传播梯度,注意 h(t)(t<τ) 同时具有 o(t) 和 h(t+1) 两个后续节点。 因此,它的梯度由下式计算 :
∇h(t)L=(∂h(t+1)∂h(t))⊤(∇h(t+1)L)+(∂o(t)∂h(t))⊤(∇o(t)L)
=W⊤(∇h(t+1)L)diag(1−(h(t+1))2)V⊤(∇o(t)L)
其中
diag(1−(h(t+1))2)
表示包含元素
1−(h(t+1)i)2
的对角矩阵。 这是关于时刻
t+1
与隐藏单元~
i
关联的双曲正切的Jacobian。
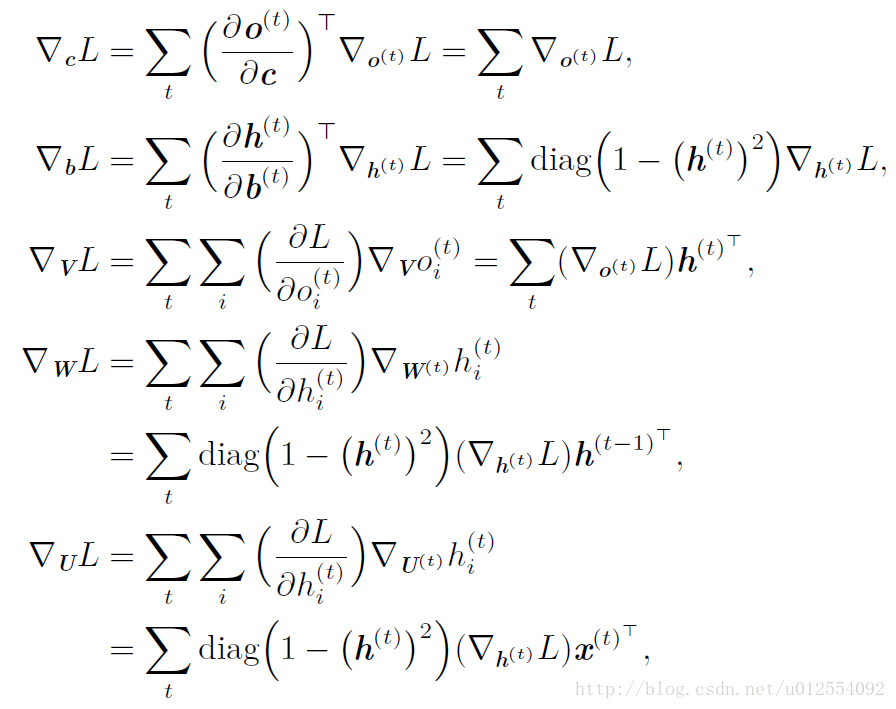
3. 双向RNN
顾名思义,双向RNN 结合时间上从序列起点开始移动的RNN 和另一个时间上从序列末尾开始移动的RNN。
这个想法可以自然地扩展到2维输入,如图像,由四个RNN组成,每一个沿着四个方向中的一个计算:上、下、左、右。 如果RNN能够学习到承载长期信息,那在2维网格每个点
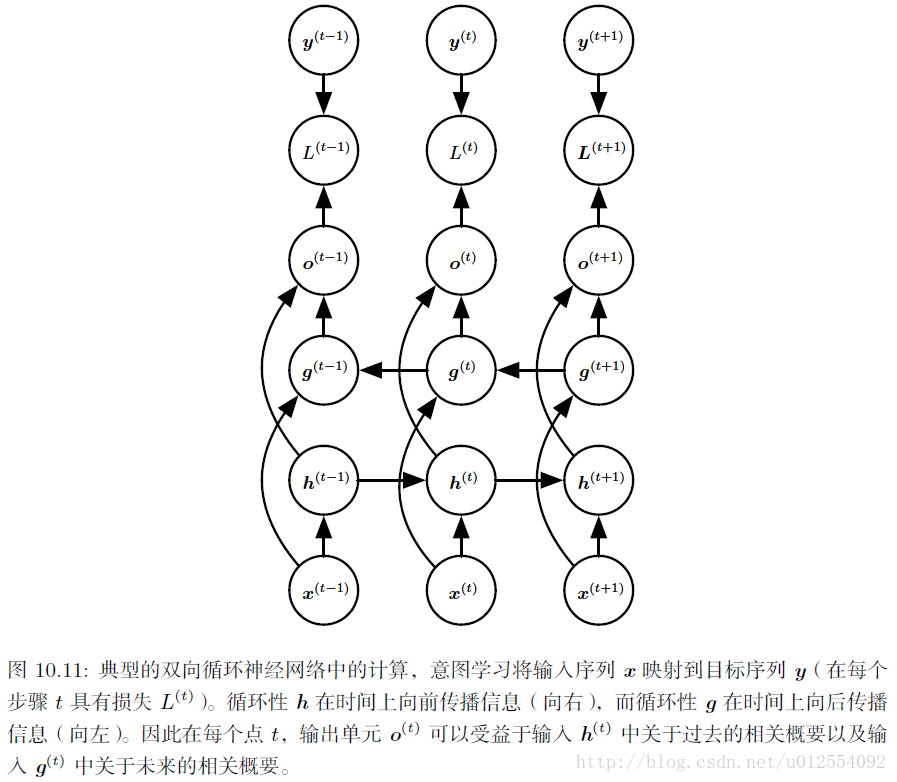
4. 基于编码-解码的序列到序列架构
( 1 ) 编码器或读取器或输入RNN处理输入序列。 编码器输出上下文 C (通常是最终隐藏状态的简单函数)。
( 2 ) 解码器或写入器或输出RNN则以固定长度的向量为条件产生输出序列
这种架构对比本章前几节提出的架构的创新之处在于长度
nx
和
ny
可以彼此不同,而之前的架构约束
nx=ny=τ
。 在序列到序列的架构中,两个RNN共同训练以最大化
logP(y(1),…,y(ny)∣x(1),…,x(nx))
(关于训练集中所有
x
和
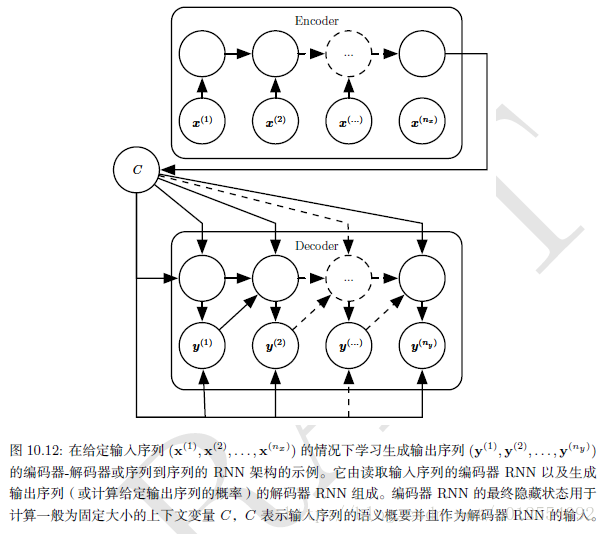
5. 深度循环网络
Graves第一个展示了将RNN的状态分为多层的显著好处,如下图左。 我们可以认为,在下图(a)所示层次结构中较低的层起到了将原始输入转化为对更高层的隐藏状态更合适表示的作用。 Pascanu更进一步提出在上述三个块中各使用一个单独的MLP(可能是深度的),如下图(b)所示。 考虑表示容量,我们建议在这三个步中都分配足够的容量,但增加深度可能会因为优化困难而损害学习效果。 在一般情况下,更容易优化较浅的架构,加入下图(b)的额外深度导致从时间步
6. 递归神经网络
递归网络的一个明显优势是,对于具有相同长度 τ 的序列,深度(通过非线性操作的组合数量来衡量)可以急剧地从 τ 减小为 O(logτ) ,这可能有助于解决长期依赖。 一个悬而未决的问题是如何以最佳的方式构造树。 一种选择是使用不依赖于数据的树结构,如平衡二叉树。 在某些应用领域,外部方法可以为选择适当的树结构提供借鉴。 例如,处理自然语言的句子时,用于递归网络的树结构可以被固定为句子语法分析树的结构(可以由自然语言语法分析程序提供){cite?}。 理想的情况下,人们希望学习器自行发现和推断适合于任意给定输入的树结构。
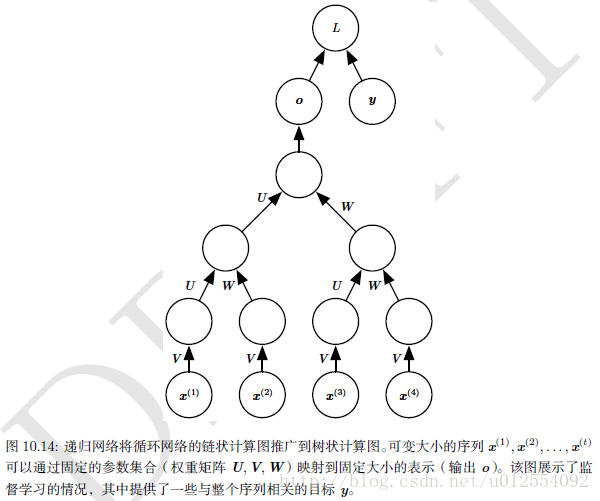
7. 长期依赖的挑战
经过许多阶段传播后的梯度倾向于消失(大部分情况)或爆炸(很少,但对优化过程影响很大)。 即使我们假设循环网络是参数稳定的(可存储记忆,且梯度不爆炸),但长期依赖的困难来自比短期相互作用指数小的权重(涉及许多Jacobian相乘)。
特别地,循环神经网络所使用的函数组合有点像矩阵乘法。 我们可以认为,循环联系

8. 渗漏单元和其他多时间尺度的策略
处理长期依赖的一种方法是设计工作在多个时间尺度的模型,使模型的某些部分在细粒度时间尺度上操作并能处理小细节,而其他部分在粗时间尺度上操作并能把遥远过去的信息更有效地传递过来。 存在多种同时构建粗细时间尺度的策略。 这些策略包括在时间轴增加跳跃连接,”渗漏单元”使用不同时间常数整合信号,并去除一些用于建模细粒度时间尺度的连接。
时间维度的跳跃连接
增加从遥远过去的变量到目前变量的直接连接是得到粗时间尺度的一种方法。梯度可能关于时间步数呈指数消失或爆炸。算法引入了
d
延时的循环连接以减轻这个问题。 现在导数指数减小的速度与
渗漏单元和一系列不同时间尺度
获得导数乘积接近1的另一方式是设置线性自连接单元,并且这些连接的权重接近1。我们对某些
删除连接
这个想法与之前讨论的时间维度上的跳跃连接不同,因为它涉及主动删除长度为一的连接并用更长的连接替换它们。 以这种方式修改的单元被迫在长时间尺度上运作。 而通过时间跳跃连接是添加边。 收到这种新连接的单元,可以学习在长时间尺度上运作,但也可以选择专注于自己其他的短期连接。
9. 长短期记忆LSTM
实际应用中最有效的序列模型称为门控RNN。 包括基于长短期记忆和基于门控循环单元的网络。
像渗漏单元一样,门控RNN想法也是基于生成通过时间的路径,其中导数既不消失也不发生爆炸。 渗漏单元通过手动选择常量的连接权重或参数化的连接权重来达到这一目的。 门控RNN将其推广为在每个时间步都可能改变的连接权重。
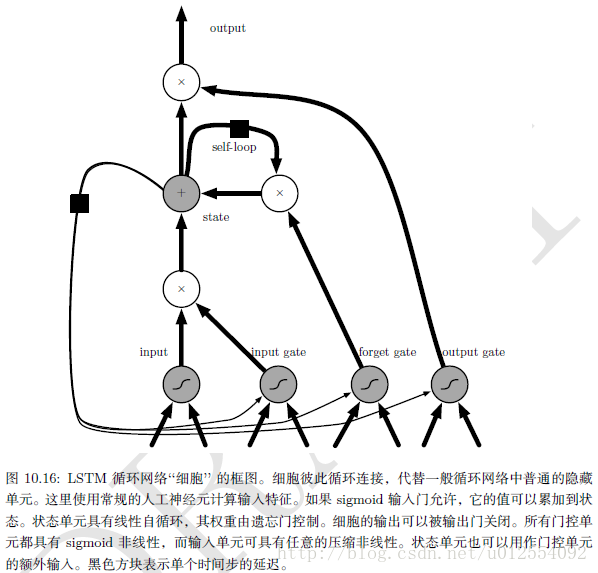
LSTM不是简单地向输入和循环单元的仿射变换之后施加一个逐元素的非线性。 与普通的循环网络类似,每个单元有相同的输入和输出,但也有更多的参数和控制信息流动的门控单元系统。 最重要的组成部分是状态单元
s(t)i
,与前一节讨论的渗漏单元有类似的线性自环。 然而,此处自环的权重(或相关联的时间常数)由遗忘门
f(t)i
控制(时刻
t
和细胞
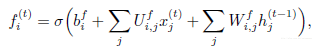
其中 x(t) 是当前输入向量, ht 是当前隐藏层向量, ht 包含所有LSTM细胞的输出。 bf,Uf,Wf 分别是偏置、输入权重和遗忘门的循环权重。 因此LSTM细胞内部状态以如下方式更新,其中有一个条件的自环权重 f(t)i :

10. 优化长期依赖
截断梯度
强非线性函数(如由许多时间步计算的循环网络)往往倾向于非常大或非常小幅度的梯度。 如下图所示,我们可以看到,目标函数(作为参数的函数)存在一个伴随”悬崖”的”地形”:宽且相当平坦区域被目标函数变化快的小区域隔开,形成了一种悬崖。
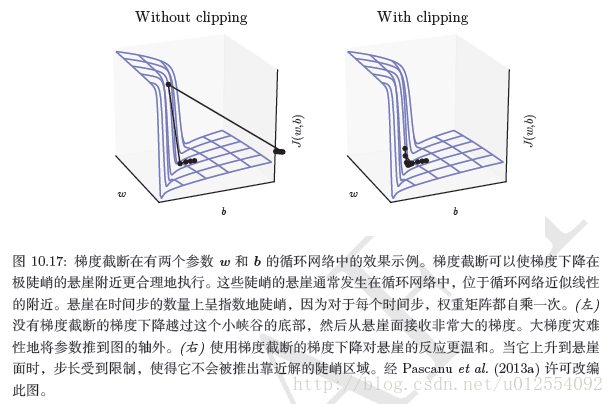
一个简单的解决方案已被从业者使用多年:截断梯度。一种选择是在参数更新之前,逐元素地截断小批量产生的参数梯度。 另一种是在参数更新之前截断梯度
g
的范数
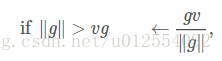
其中
v
是范数上界,
引导信息流的正则化
正则化或约束参数,以引导”信息流”。 特别是即使损失函数只对序列尾部的输出作惩罚,我们也希望梯度向量 ∇h(t)L 在反向传播时能维持其幅度:

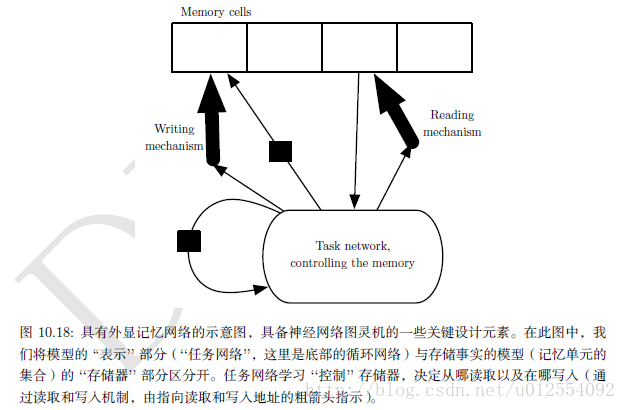
11. 外显记忆
神经网络擅长存储隐性知识,但是他们很难记住事实。被存储在神经网络参数中之前,随机梯度下降需要多次提供相同的输入,即使如此,该输入也不会被特别精确地存储。 Graves推测这是因为神经网络缺乏工作存储(working memory)系统,即类似人类为实现一些目标而明确保存和操作相关信息片段的系统。 这种外显记忆组件将使我们的系统不仅能够快速”故意”地存储和检索具体的事实,也能利用他们循序推论。 神经网络处理序列信息的需要,改变了每个步骤向网络注入输入的方式,长期以来推理能力被认为是重要的,而不是对输入做出自动的、直观的反应 。
为了解决这一难题,Weston引入了记忆网络,其中包括一组可以通过寻址机制来访问的记忆单元。 记忆网络原本需要监督信号指示他们如何使用自己的记忆单元。 Graves引入的神经网络图灵机,不需要明确的监督指示采取哪些行动而能学习从记忆单元读写任意内容,并通过使用基于内容的软注意机制,允许端到端的训练。 这种软寻址机制已成为其他允许基于梯度优化的模拟算法机制的相关架构的标准。
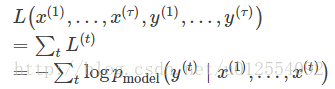















 1283
1283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









