









1. What is Reinforcement Learning
概述:

举个栗子:

再举一个:
2. Markov Decision Process
- Mathematical formulation of the RL problem
- Markov property: Current state completely characterises the state of the world

**处理流程:**

The optimal policy π*
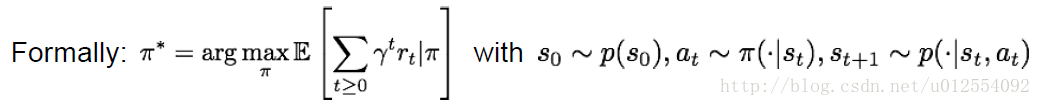
3. Q-learning
Definitions: Value function and Q-value function:

Bellman equation:

优化策略:

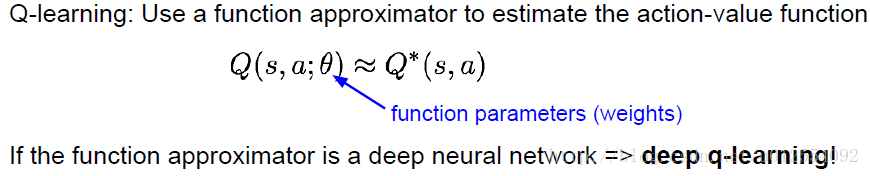
**Solving for the optimal policy: Q-learning**

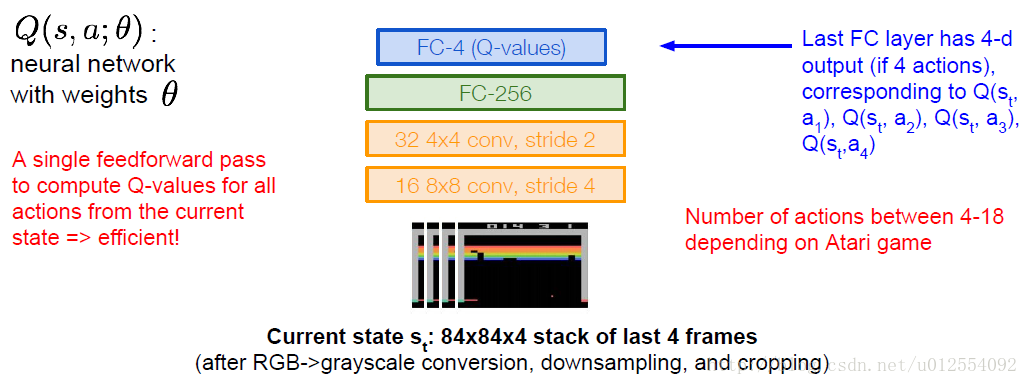
举个栗子:Playing Atari Games

**Q-network Architecture**
**Training the Q-network: Experience Replay**

Deep Q-Learning with Experience Replay

4. Policy Gradients



Intuition:

Variance reduction:

Variance reduction: Baseline

How to choose the baseline?

A better baseline: Want to push up the probability of an action from a state, if this action was better than the **expected value of what we should get from that state**

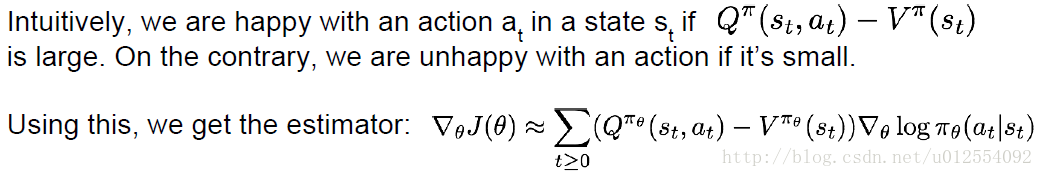
**Actor-Critic Algorithm**


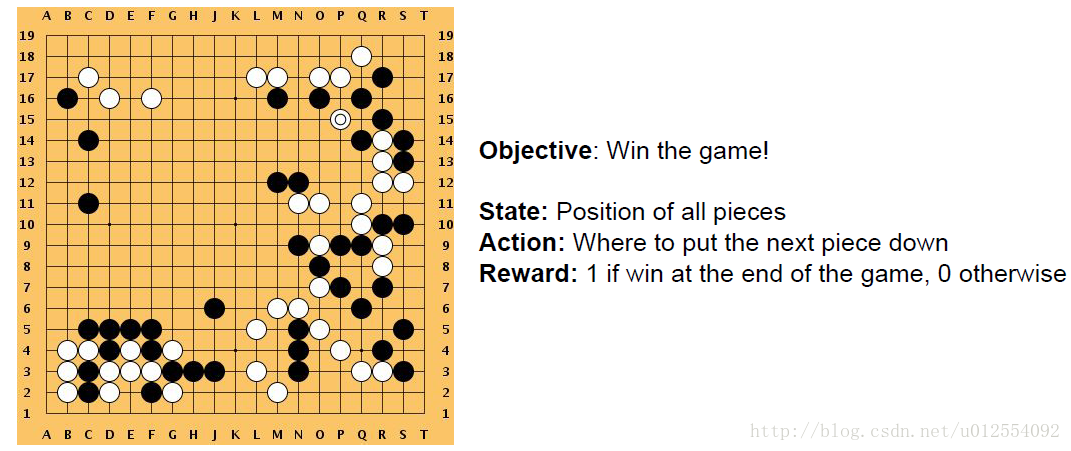
5. REINFORCE 的运用
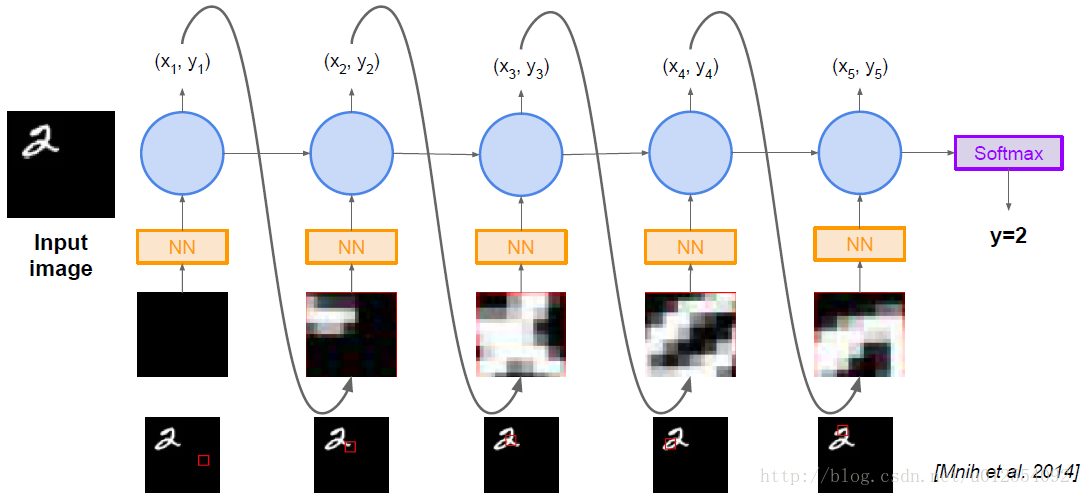
5.1 Recurrent Attention Model (RAM)

效果示意图:

**5.2 AlphaGo**

6. Summary
- Policy gradients: very general but suffer from high variance so requires a lot of samples.
Challenge: sample-efficiency - Q-learning: does not always work but when it works, usually more sample-efficient. Challenge: exploration
- Guarantees:
Policy Gradients: Converges to a local minima of J(θ), often good enough!
Q-learning: Zero guarantees since you are approximating Bellman equation with a complicated function approximator














 677
677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









