








Ruby 字符串(String)
Ruby 中的 String 对象存储并操作一个或多个字节的任意序列,通常表示那些代表人类语言的字符。
最简单的字符串是括在单引号(单引号字符)内。
在引号标记内的文本是字符串的值:
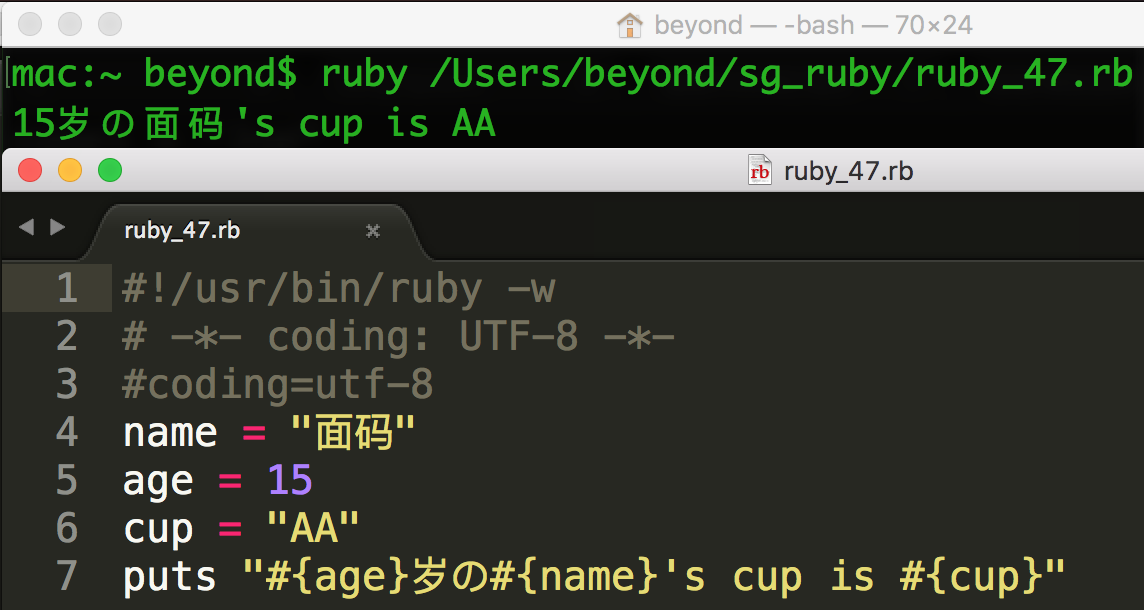
'这是一个 Ruby 程序的字符串'如果您需要在单引号字符串内使用单引号字符,那么需要在单引号字符串使用反斜杠,
这样 Ruby 解释器就不会认为这个单引号字符会终止字符串:
'girl\'s cup is F'
反斜杠也能转义另一个反斜杠,这样第二个反斜杠本身不会解释为转义字符。
以下是 Ruby 中字符串相关的特性。
双引号字符串
在双引号字符串中我们可以使用 #{ } 井号和大括号来计算表达式的值:
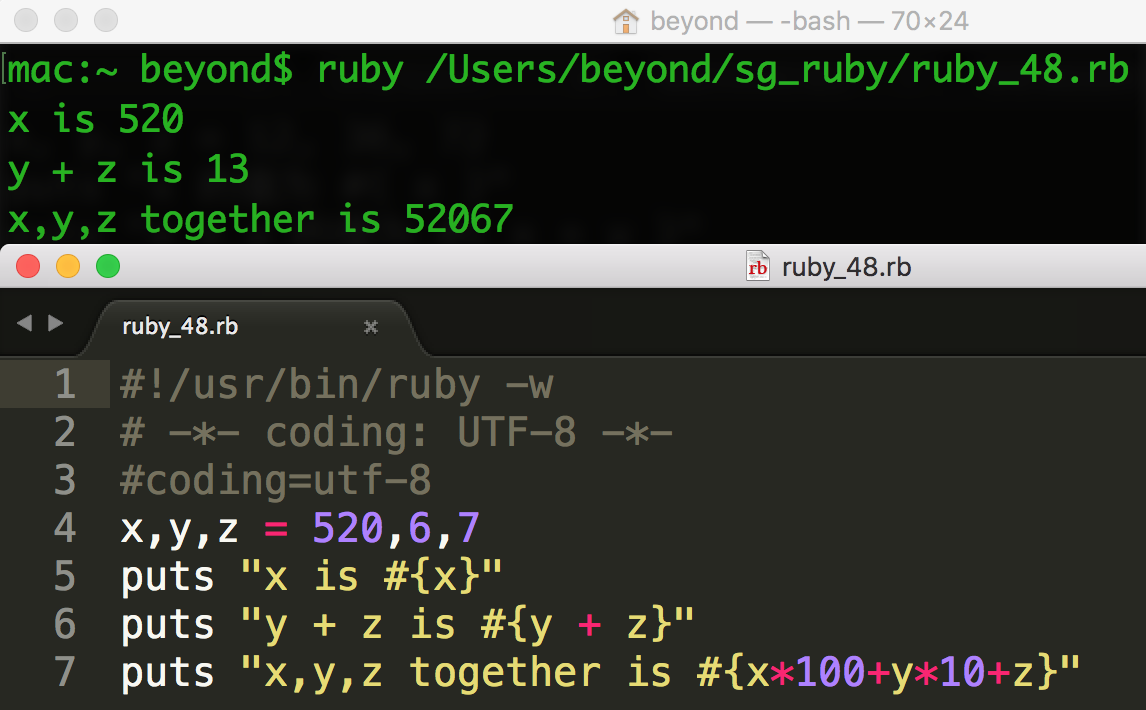
字符串中嵌入变量:
字符串中进行数学运算:
Ruby 中还支持一种采用%Q 和 %q 来引导的字符串变量,
%Q 是双引号引用规则,
而%q 使用的是单引号引用规则,
后面再接一个 ( ! [ { 等等 的开始界定符 和 与 } ] ) 等等的末尾界定符。
跟在q或Q后面的那个字符是 分界符.
分界符 可以是任意一个非字母数字的 单字节字符 如:[ { ( < !等
字符串会一直读取到发现相匹配的结束符为止
#!/usr/bin/ruby
# -*- coding: UTF-8 -*-
desc1 = %Q{Ruby 的字符串可以使用 '' 和 ""。}
desc2 = %q|Ruby 的字符串可以使用 '' 和 ""。|
puts desc1
puts desc2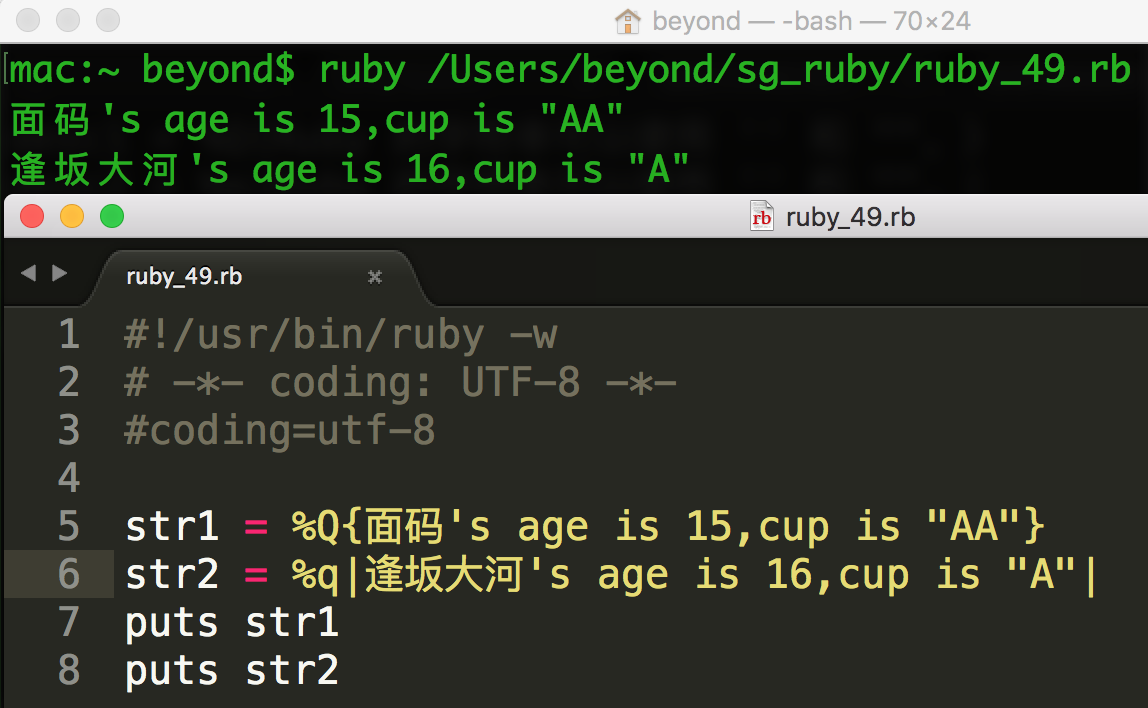
转义字符
下标列出了可使用反斜杠符号转义的 转义字符 或 非打印字符。
注意:
在一个双引号括起的字符串内,转义字符会被解释;
在一个单引号括起的字符串内,转义字符会被保留。
| 反斜杠符号 | 十六进制字符 | 描述 |
|---|---|---|
| \a | 0x07 | 报警符 alert |
| \b | 0x08 | 退格键 backspace |
| \cx | Control-x | |
| \C-x | Control-x | |
| \e | 0x1b | 转义符 |
| \f | 0x0c | 换页符 |
| \M-\C-x | Meta-Control-x | |
| \n | 0x0a | 换行符 nextLine |
| \nnn | 八进制表示法,其中 n 的范围为 0.7 | |
| \r | 0x0d | 回车符 return |
| \s | 0x20 | 空格符 space |
| \t | 0x09 | 制表符 tab |
| \v | 0x0b | 垂直制表符 vertical |
| \x | 字符 x | |
| \xnn | 十六进制表示法,其中 n 的范围为 0.9、 a.f 或 A.F |
字符编码
Ruby 的默认字符集是 ASCII,字符可用单个字节表示。
如果您使用 UTF-8 或其他现代的字符集,字符可能是用一个到四个字节表示。
您可以在程序开头使用 $KCODE 改变字符集,如下所示:
$KCODE = 'u'
下面是 $KCODE 可能的值。
| 编码 | 描述 |
|---|---|
| a | ASCII (与 none 相同)。这是默认的。 |
| e | EUC。 |
| n | None (与 ASCII 相同)。 |
| u | UTF-8。 |
字符串内建方法
我们需要有一个 String 对象的实例来调用 String 方法。
下面是创建 String 对象实例的方式:???Excuse Me???
new [String.new(str="")]
这将返回一个包含 str 副本的新的字符串对象。
现在,使用 str 对象,我们可以调用任意可用的实例方法。
例如:
#!/usr/bin/ruby
str = String.new("BEYOND")
str2 = str.downcase
puts "#{str2}"
这将产生以下结果:
beyond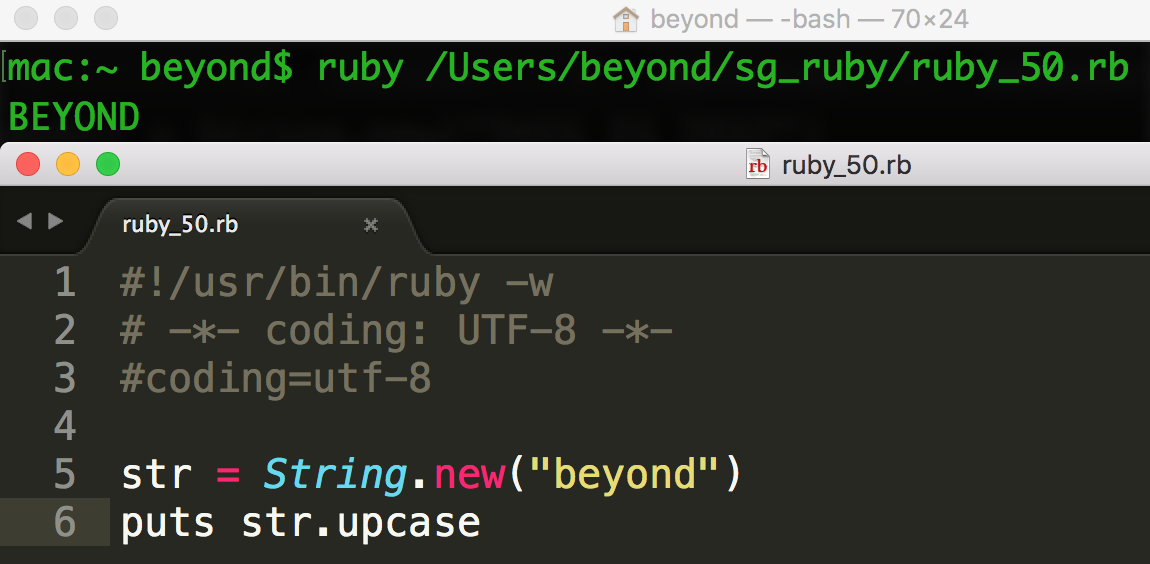
字符串类的公共方法,见本文末尾
Ruby 数组(Array)
Ruby 数组是任何对象的有序的、整数索引的集合。
数组中的每个元素都与一个索引相关,并可通过索引进行获取。
数组的索引从 0 开始,这与 C 或 Java 中一样。
一个负数的索引时相对于数组的末尾计数的,也就是说,索引为 -1 表示数组的最后一个元素,-2 表示数组中的倒数第二个元素,依此类推。
Ruby 数组可存储诸如 String、 Integer、 Fixnum、 Hash、 Symbol 等对象,甚至可以是其他 Array 对象。
Ruby 数组不像其他语言中的数组那么刚性。当向数组添加元素时,Ruby 数组会自动增长。
创建数组
有多种方式创建或初始化数组。一种方式是通过 new 类方法:
modelArr = Array.new
您可以在创建数组的同时设置数组的大小:
modelArr = Array.new(20)
数组 modelArr 的大小或长度为 20 个元素。
您可以使用 size 或 length 方法返回数组的大小:
#!/usr/bin/ruby
modelArr = Array.new(20)
puts modelArr.size # 返回 20
puts modelArr.length # 返回 20
这将产生以下结果:
20
20
您可以一次性给数组中的每个元素赋值,如下所示:
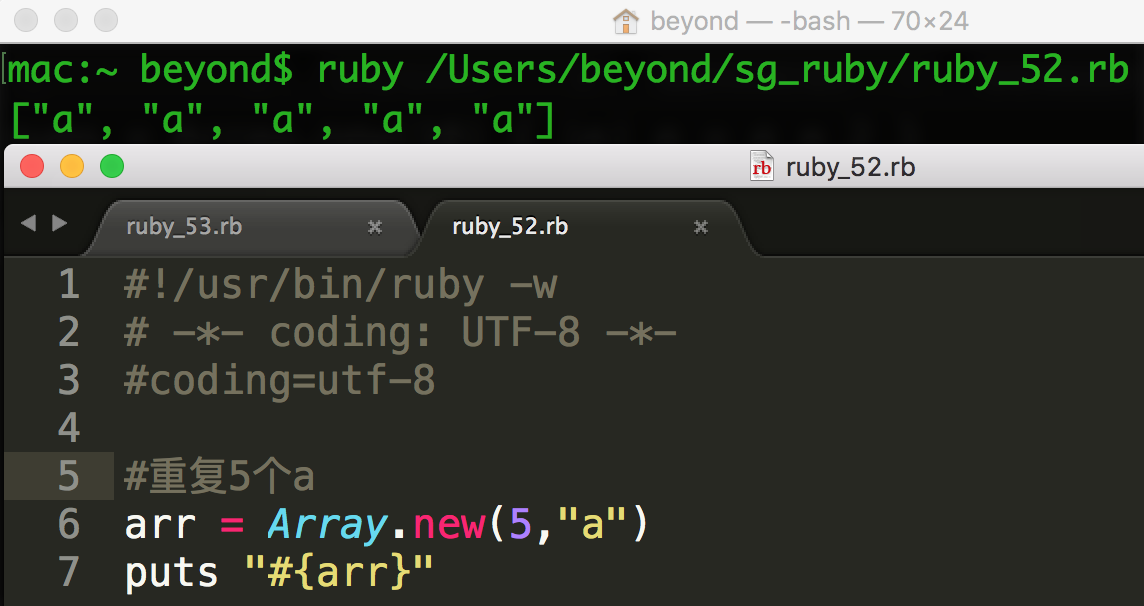
您也可以使用带有 new 的块,每个元素使用块中的计算结果来填充:
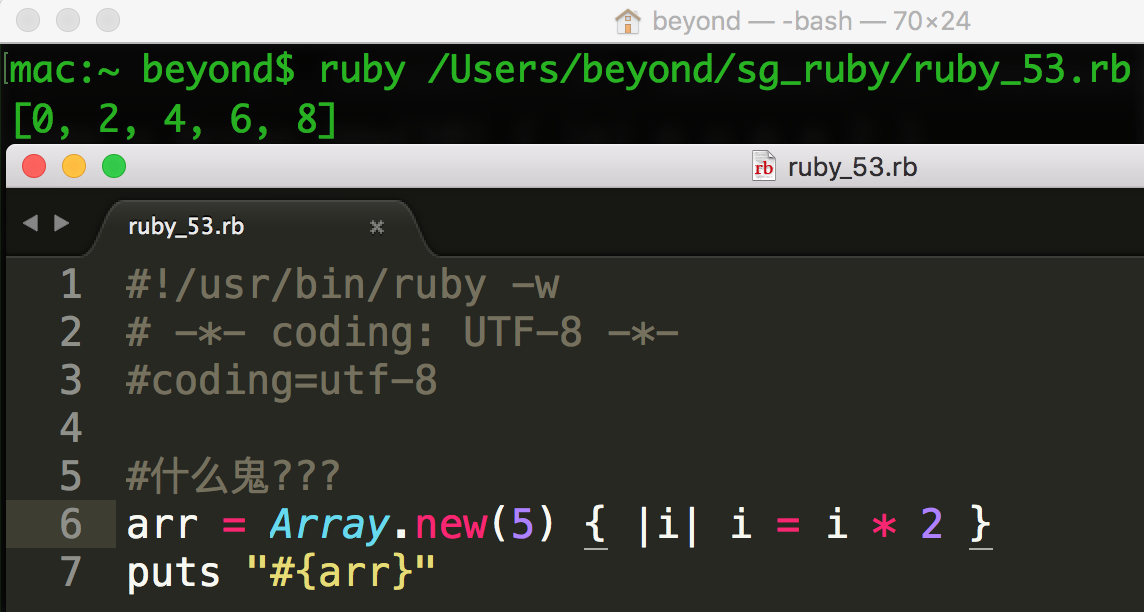
数组还有另一种方法,[],如下所示:
nums = Array.[](1, 2, 3, 4,5)
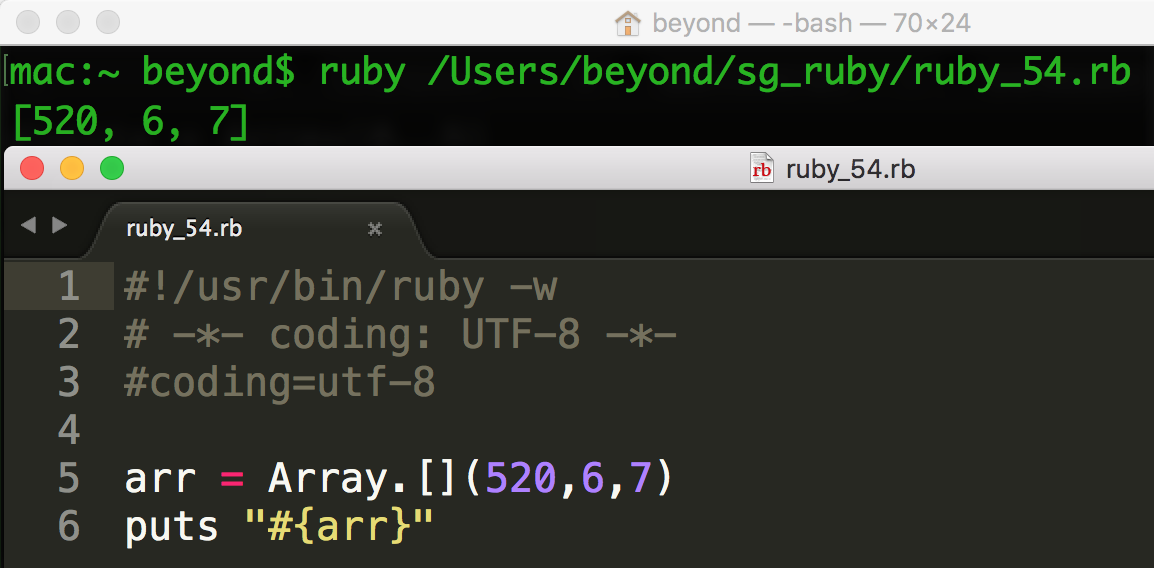
数组创建的另一种形式如下所示:
nums = Array[1, 2, 3, 4,5]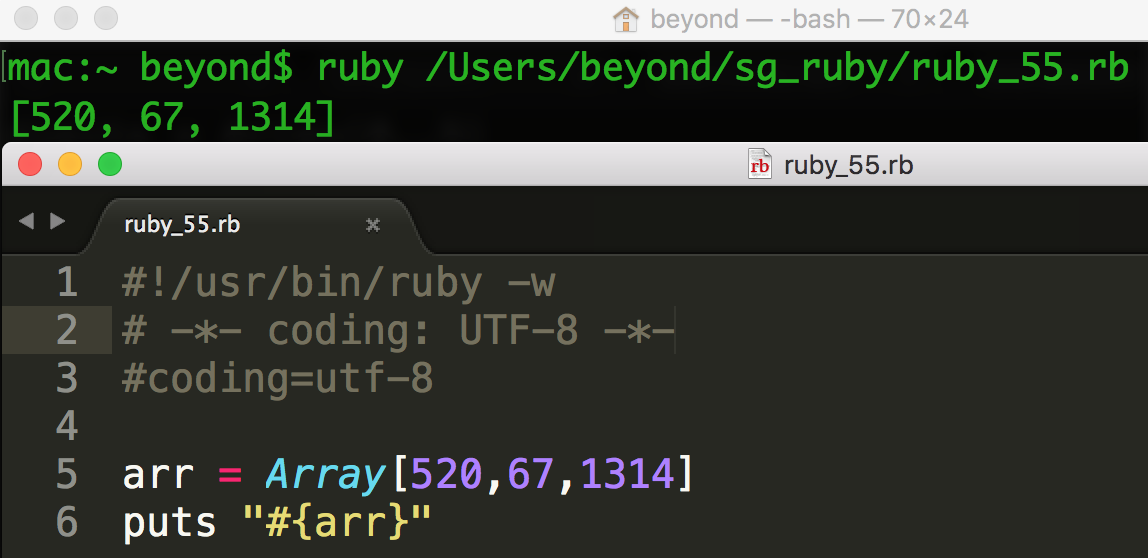
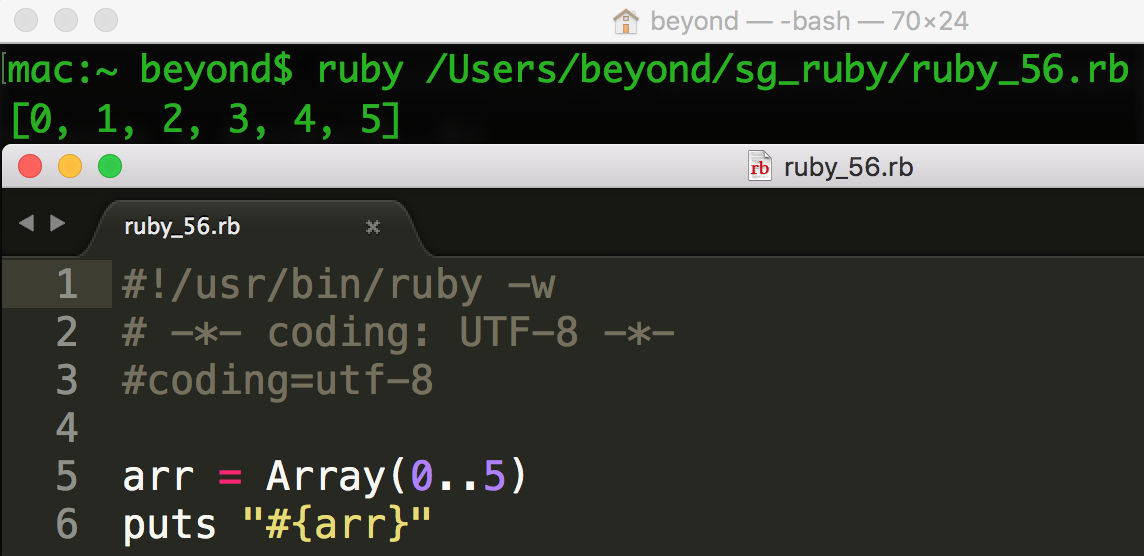
在 Ruby 核心模块中,可以有一个只接收单个参数的 Array 方法,该方法使用一个范围作为参数来创建一个数字数组:
数组内建方法
我们需要有一个 Array 对象的实例来调用 Array 方法。
下面是创建 Array 对象实例的方式:
Array.[](...) [or] Array[...] [or] [...]
这将返回一个使用给定对象进行填充的新的数组。
现在,使用创建的对象,我们可以调用任意可用的实例方法。
例如:
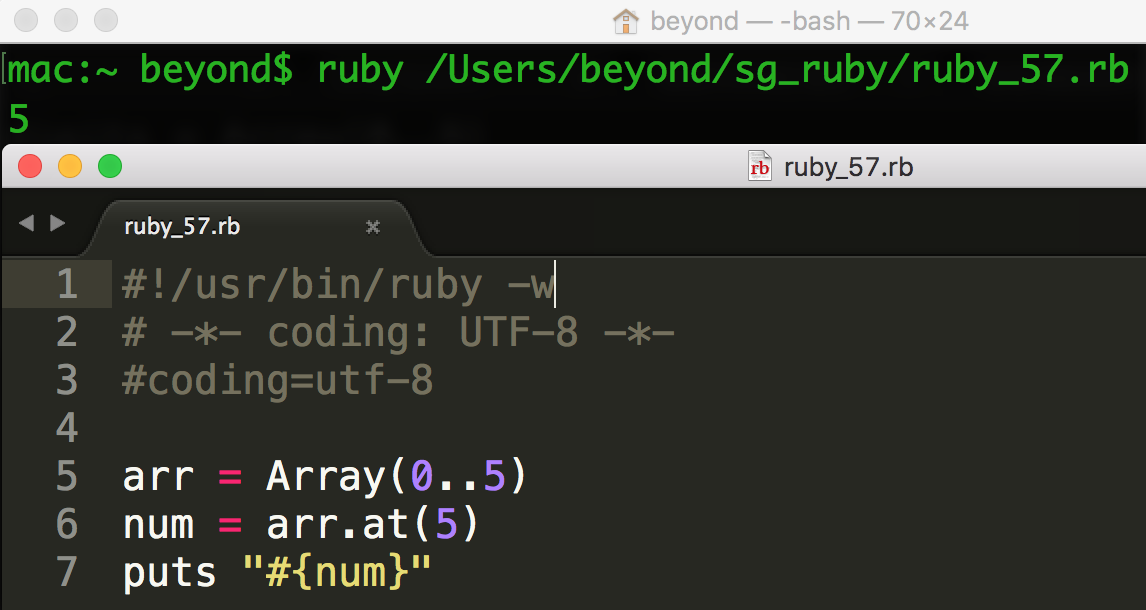
数组类的公共方法见文章末尾
Ruby 哈希(Hash)
哈希(Hash)是类似 "employee" => "salary" 这样的键值对的集合。
哈希的索引是通过任何对象类型的任意键来完成的,而不是一个整数索引,其他与数组相似。
通过键或值遍历哈希的顺序看起来是随意的,且通常不是按照插入顺序。
如果您尝试通过一个不存在的键访问哈希,则方法会返回 nil。
创建哈希
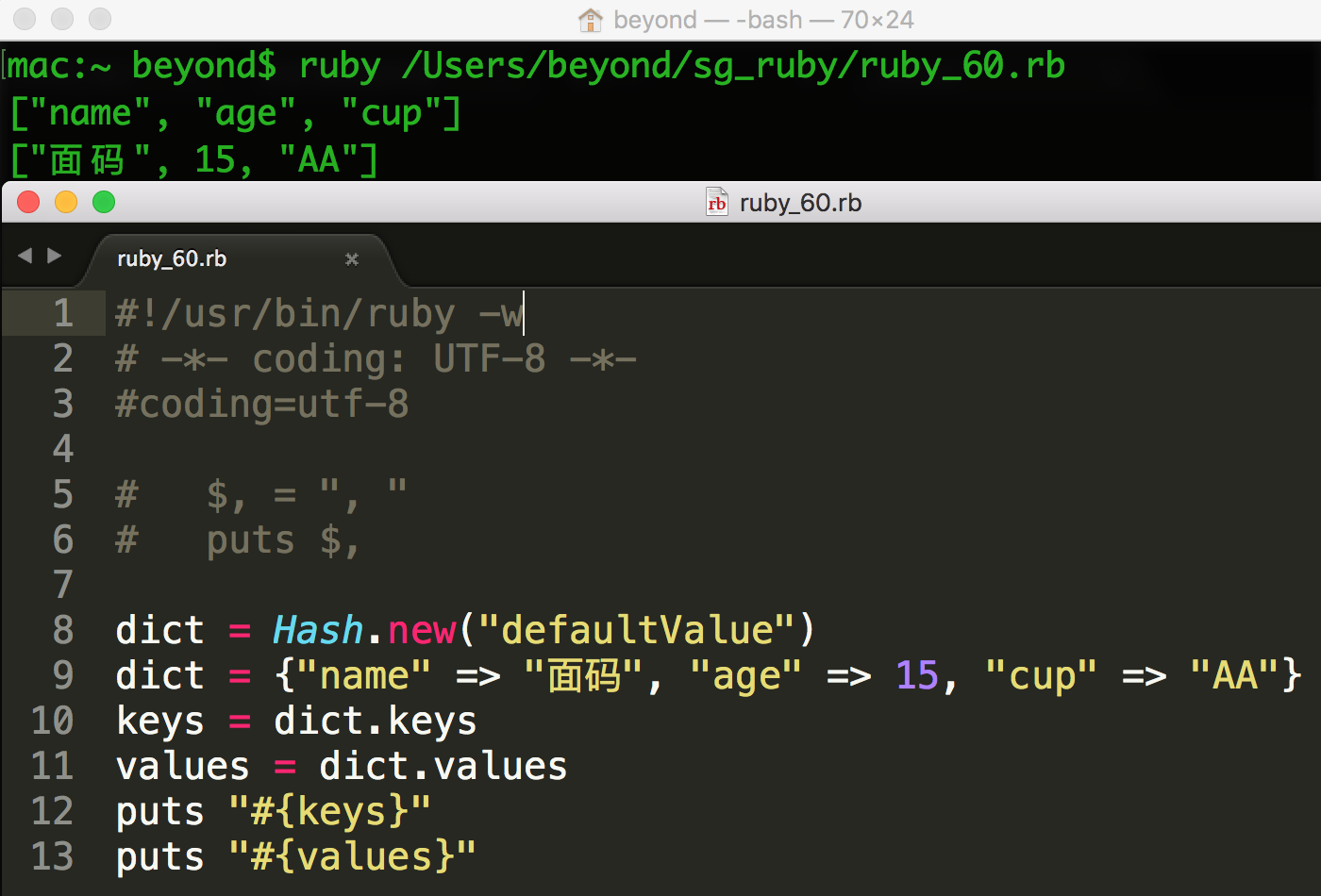
与数组一样,有各种不同的方式来创建哈希。您可以通过 new 类方法创建一个空的哈希:
months = Hash.new
您也可以使用 new 创建带有默认值的哈希,不带默认值的哈希是 nil:
dict = Hash.new( "defaultValue" )
或
dict = Hash.new "defaultValue"
当您访问带有默认值的哈希中的任意键时,如果键或值不存在,访问哈希将返回默认值:
#!/usr/bin/ruby
dict = Hash.new( "defaultValue" )
puts "#{dict[0]}"
puts "#{dict[67]}"
这将产生以下结果:
defaultValue
defaultValue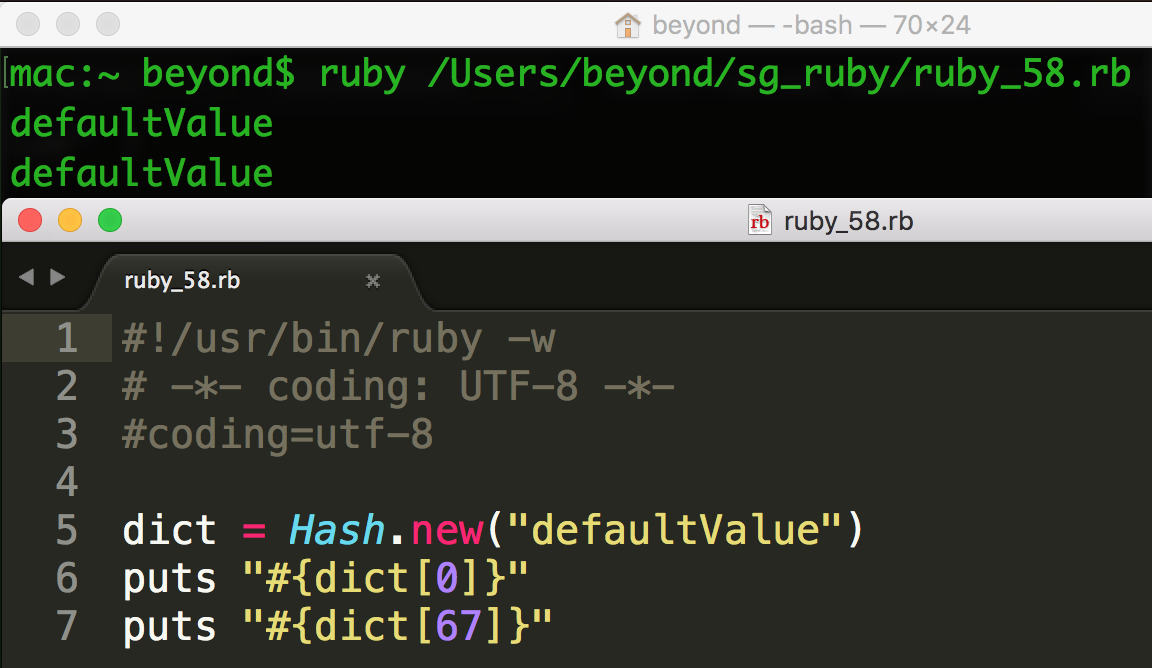
#!/usr/bin/ruby
dict = Hash["a" => 67, "b" => 520]
puts "#{dict['a']}"
puts "#{dict['b']}"
这将产生以下结果:
67
520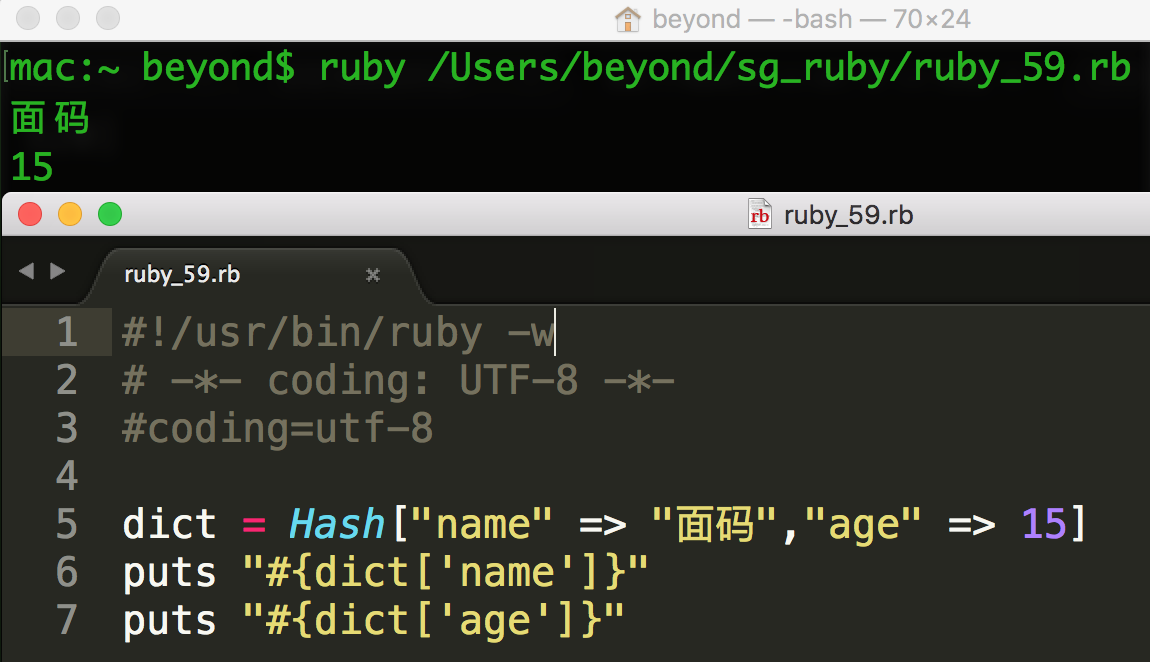
您可以使用任何的 Ruby 对象作为键或值,甚至可以使用数组,
所以下面的实例是一个有效的实例:
[1,"jan"] => "January" ???有病???
哈希内置方法
我们需要有一个 Hash 对象的实例来调用 Hash 方法。
下面是创建 Hash 对象实例的方式:
Hash[[key =>|, value]* ] or
Hash.new [or] Hash.new(obj) [or]
Hash.new { |hash, key| block }
这将返回一个使用给定对象进行填充的新的哈希。
现在,使用创建的对象,我们可以调用任意可用的实例方法。
例如:
哈希类的公共方法见文章最后
Ruby 日期 & 时间(Date & Time)
Time 类在 Ruby 中用于表示日期和时间。
它是基于操作系统提供的系统日期和时间之上。该类可能无法表示 1970 年之前或者 2038 年之后的日期。
本教程将让您熟悉日期和时间的所有重要的概念。
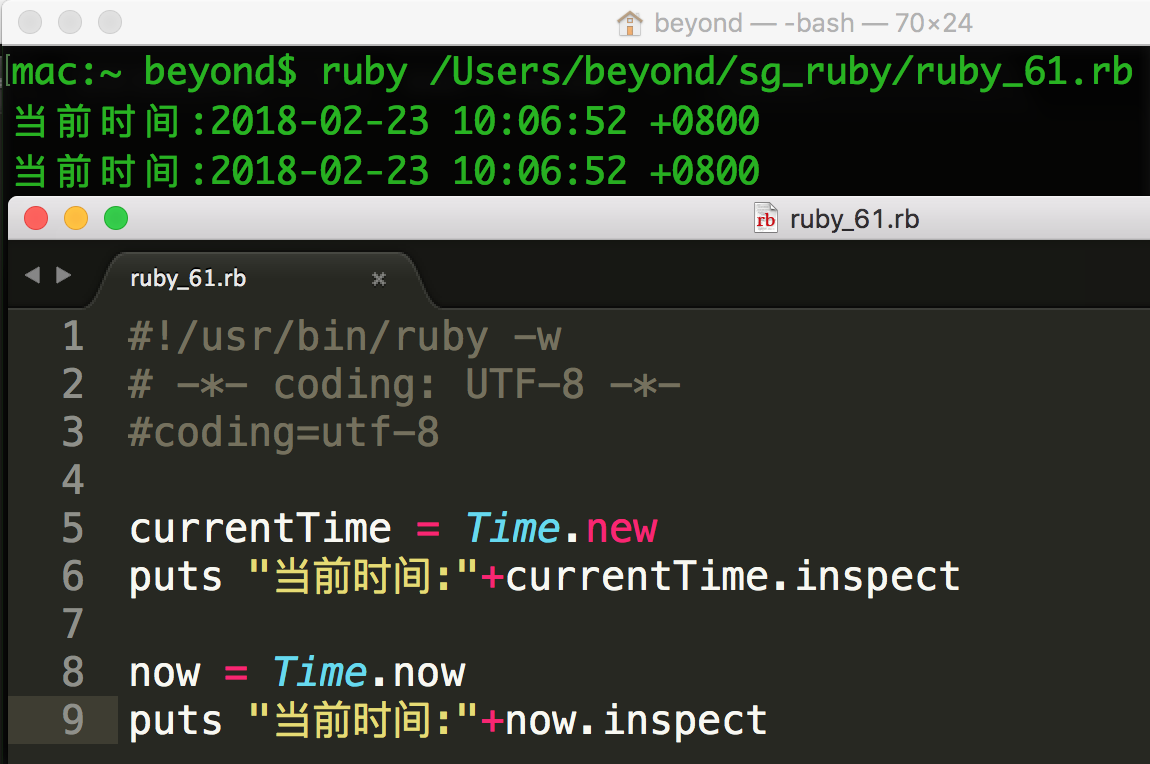
创建当前的日期和时间
下面是获取当前的日期和时间的简单实例:
获取 Date & Time 组件
我们可以使用 Time 对象来获取各种日期和时间的组件。
请看下面的实例:
#!/usr/bin/ruby -w
# -*- coding: UTF-8 -*-
time = Time.new
# Time 的组件
puts "当前时间 : " + time.inspect
puts time.year # => 日期的年份
puts time.month # => 日期的月份(1 到 12)
puts time.day # => 一个月中的第几天(1 到 31)
puts time.wday # => 一周中的星期几(0 是星期日)
puts time.yday # => 365:一年中的第几天
puts time.hour # => 23:24 小时制
puts time.min # => 59
puts time.sec # => 59
puts time.usec # => 999999:微秒
puts time.zone # => "UTC":时区名称这将产生以下结果:
当前时间 : 2015-09-17 15:24:44 +0800
2015
9
17
4
260
15
24
44
921519
CST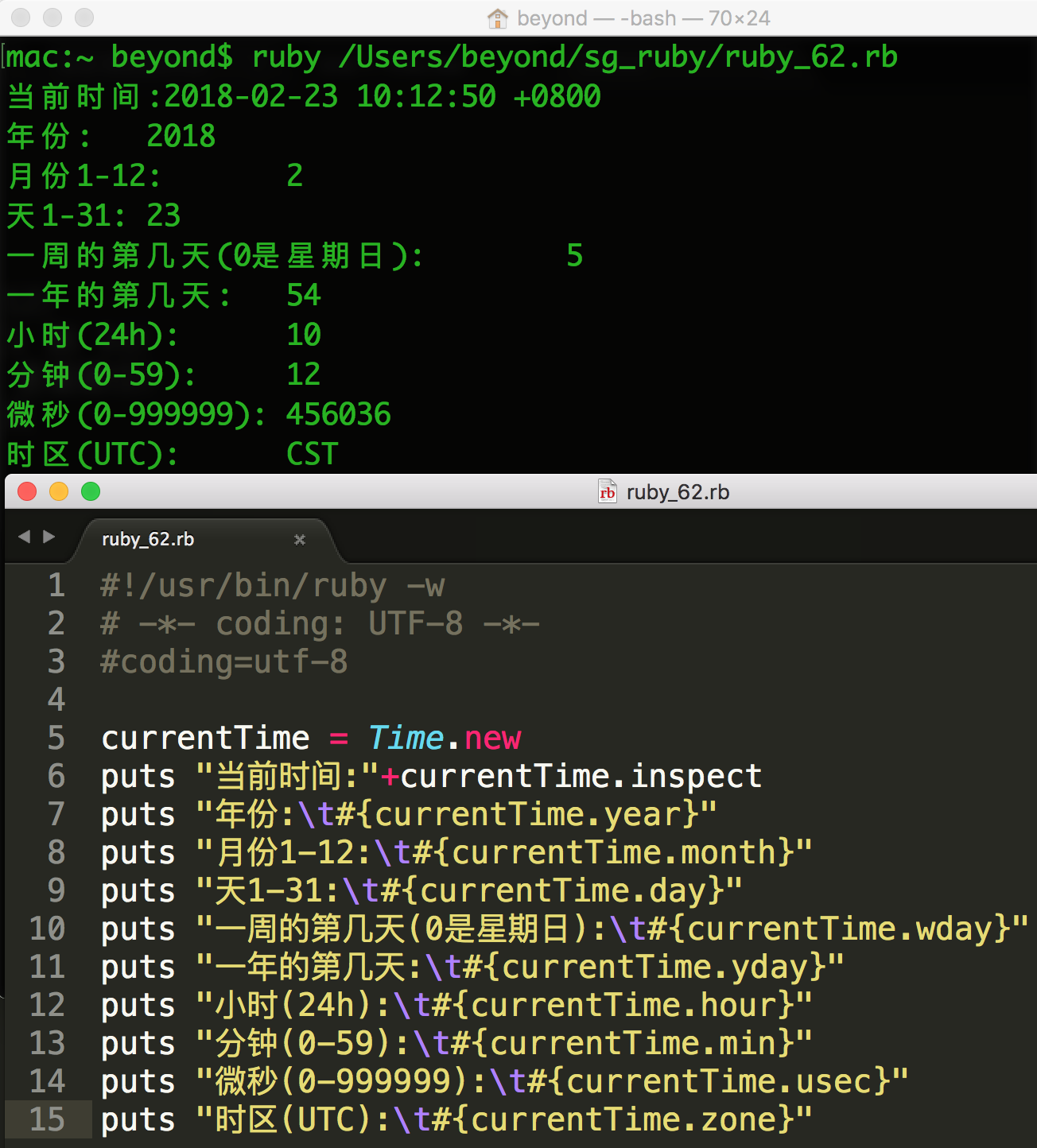
Time.utc、Time.gm 和 Time.local 函数
这些函数可用于格式化标准格式的日期,如下所示:
# July 8, 2018
Time.local(2018, 7, 8)
# July 8, 2018, 09:10am,本地时间
Time.local(2018, 7, 8, 9, 10)
# July 8, 2018, 09:10 UTC
Time.utc(2018, 7, 8, 9, 10)
# July 8, 2018, 09:10:11 GMT (与 UTC 相同)
Time.gm(2018, 7, 8, 9, 10, 11)
下面可在currentTime.to_a的数组中获取所有的组件:
[sec,min,hour,day,month,year,wday,yday,isdst,zone]
isdst结果为false表示:如果 UTC 没有 DST(夏令时)
尝试下面的实例:
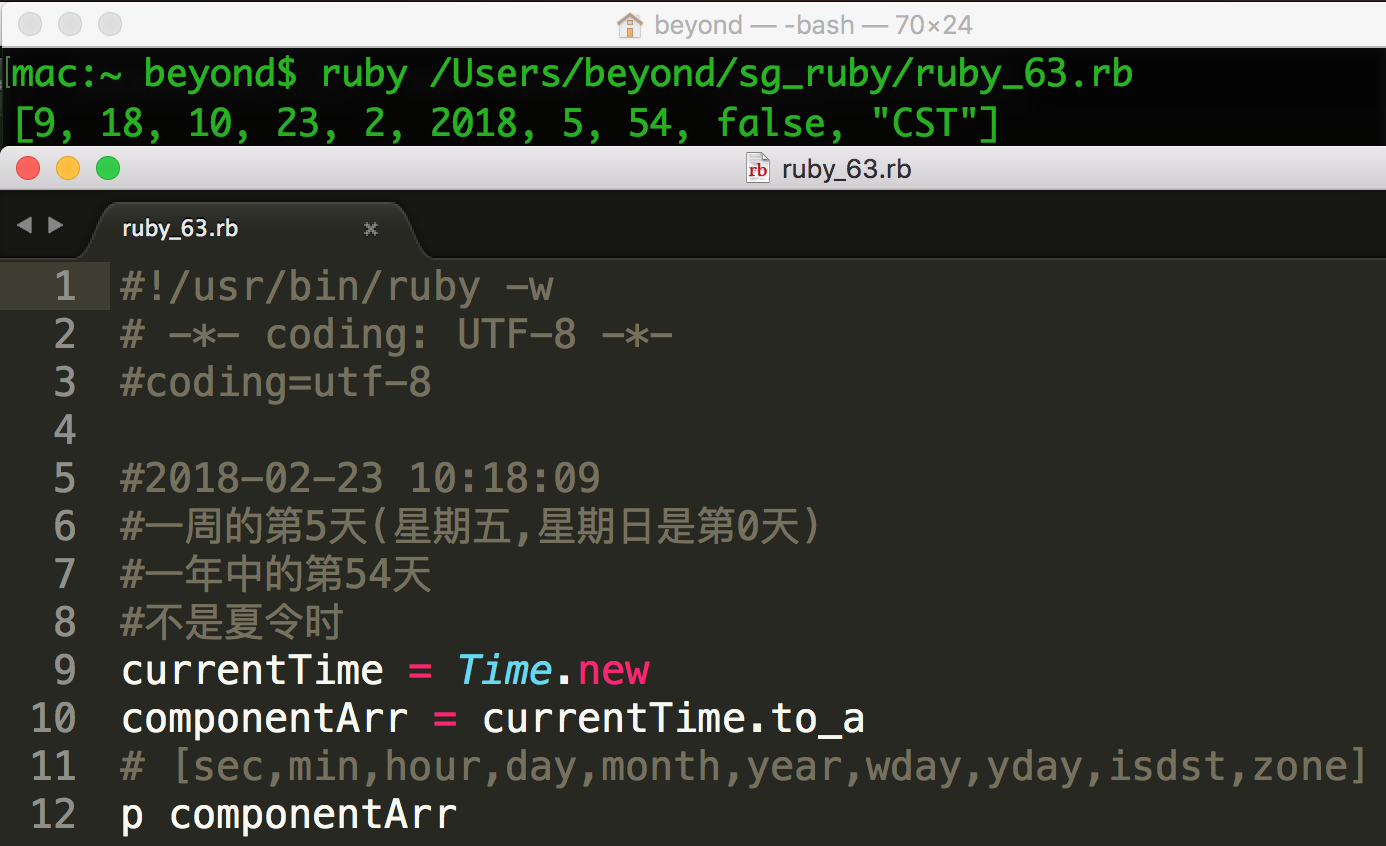
该数组可被传到 Time.utc 或 Time.local 函数来获取日期的不同格式,
如下所示:
#!/usr/bin/ruby -w
currentTime = Time.new
componentArr = currentTime.to_a
puts Time.utc(*componentArr) ???Excuse Me???以上实例运行输出结果为:
2015-09-17 15:26:09 UTC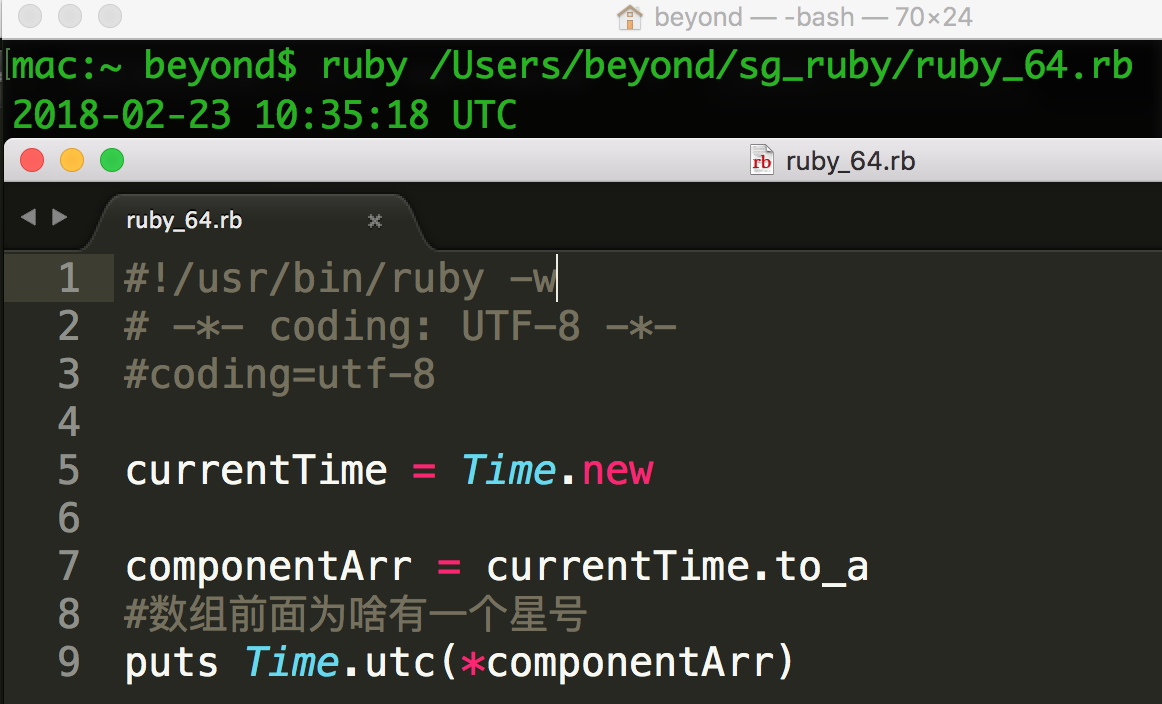
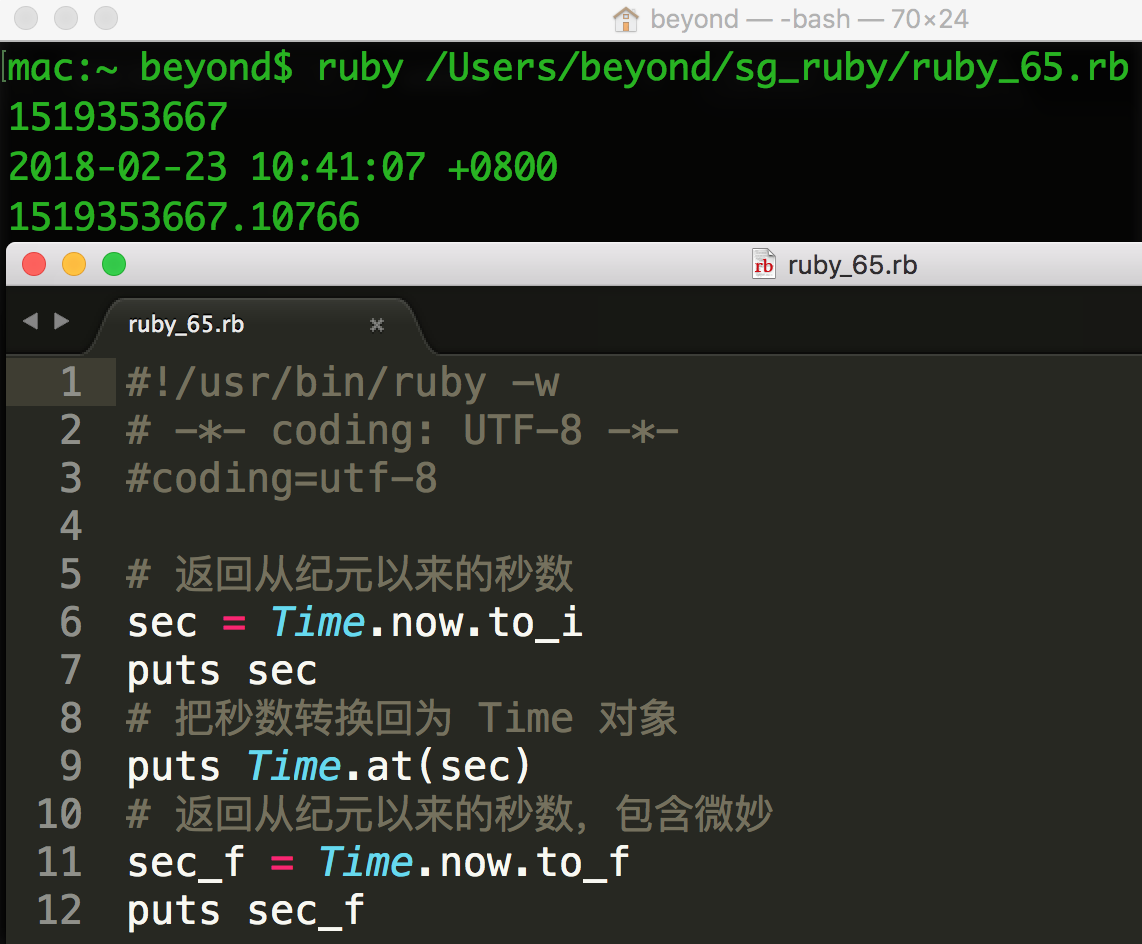
下面是获取时间的方式,从纪元以来的秒数(平台相关):
# 返回从纪元以来的秒数
sec = Time.now.to_i
# 把秒数转换为 Time 对象
Time.at(sec)
# 返回从纪元以来的秒数,包含微妙
sec_f = Time.now.to_f
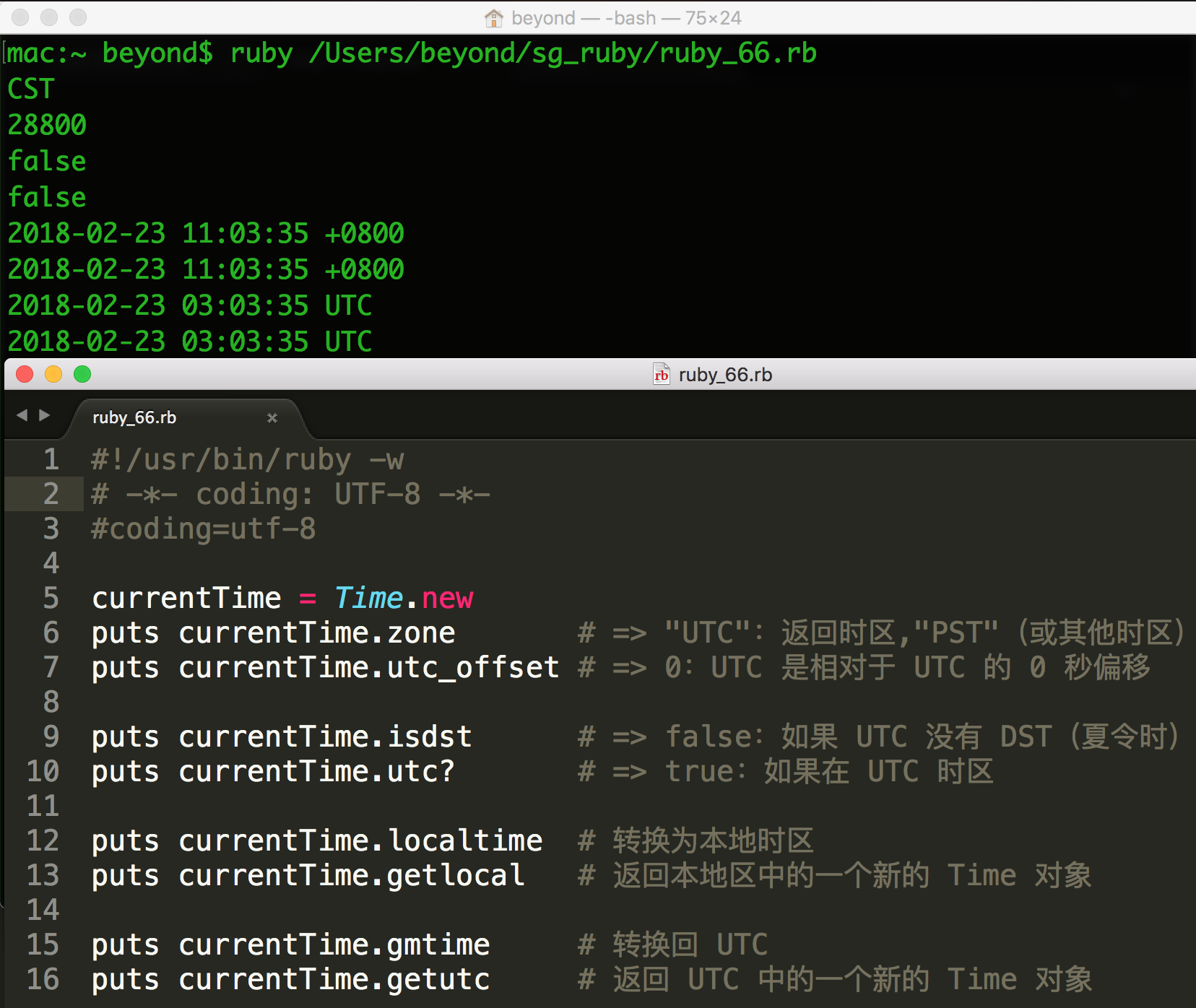
时区和夏令时
您可以使用 Time 对象来获取与时区和夏令时有关的所有信息,如下所示:
time = Time.new
# 这里是解释
time.zone # => "UTC":返回时区
time.utc_offset # => 0:UTC 是相对于 UTC 的 0 秒偏移
time.isdst # => false:如果 UTC 没有 DST(夏令时)
time.utc? # => true:如果在 UTC 时区
time.localtime # 转换为本地时区
time.gmtime # 转换回 UTC
time.getlocal # 返回本地区中的一个新的 Time 对象
time.getutc # 返回 UTC 中的一个新的 Time 对象
格式化时间和日期
有多种方式格式化日期和时间。
下面的实例演示了其中一部分:
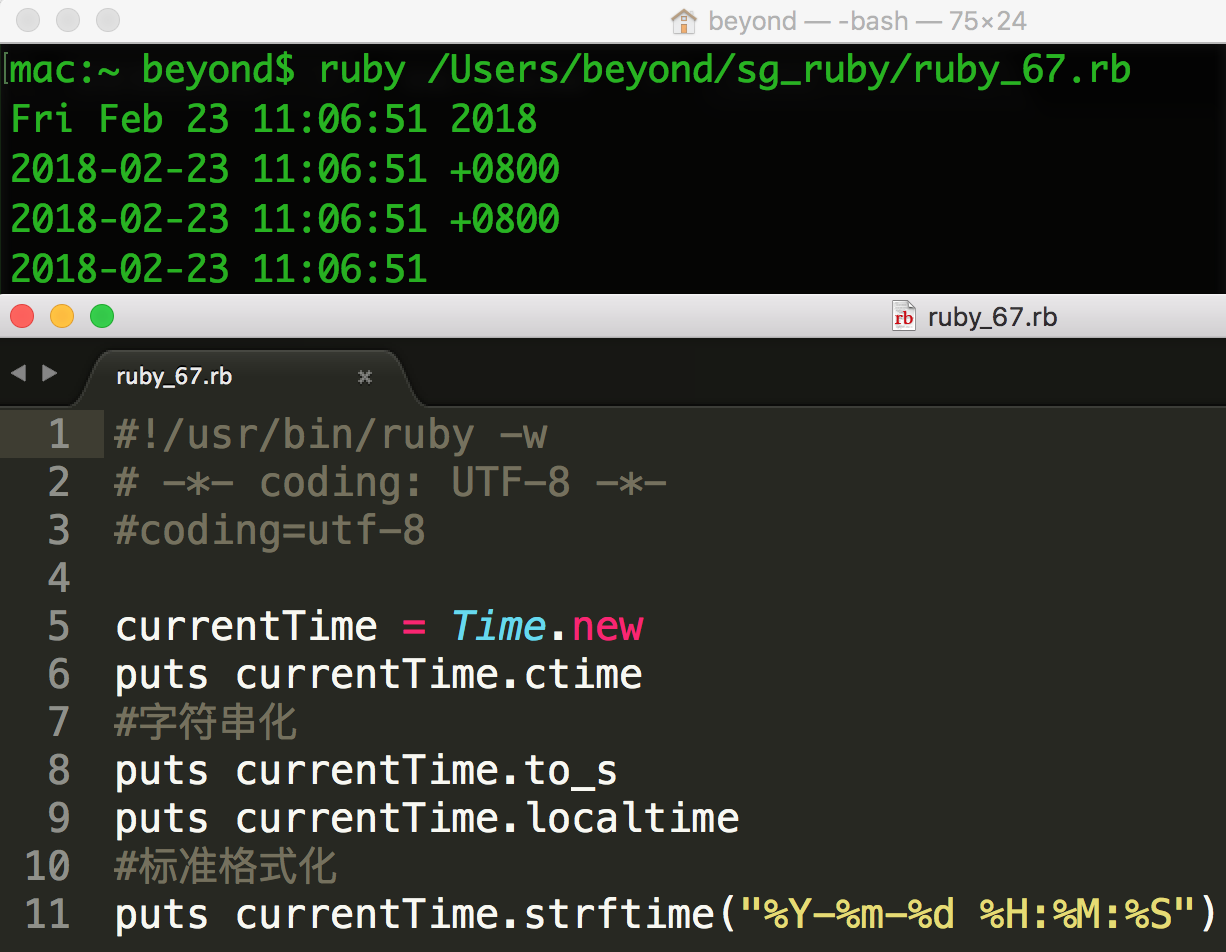
时间格式化指令
下表所列出的指令与方法 Time.strftime 一起使用。
| 指令 | 描述 |
|---|---|
| %a | 星期几名称的缩写(比如 Sun)。 |
| %A | 星期几名称的全称(比如 Sunday)。 |
| %b | 月份名称的缩写(比如 Jan)。 |
| %B | 月份名称的全称(比如 January)。 |
| %c | 优选的本地日期和时间表示法。 |
| %d | 一个月中的第几天(01 到 31)。 |
| %H | 一天中的第几小时,24 小时制(00 到 23)。 |
| %I | 一天中的第几小时,12 小时制(01 到 12)。 |
| %j | 一年中的第几天(001 到 366)。 |
| %m | 一年中的第几月(01 到 12)。 |
| %M | 小时中的第几分钟(00 到 59)。 |
| %p | 子午线指示(AM 或 PM)。 |
| %S | 分钟中的第几秒(00 或 60)。 |
| %U | 当前年中的周数,从第一个星期日(作为第一周的第一天)开始(00 到 53)。 |
| %W | 当前年中的周数,从第一个星期一(作为第一周的第一天)开始(00 到 53)。 |
| %w | 一星期中的第几天(Sunday 是 0,0 到 6)。 |
| %x | 只有日期没有时间的优先表示法。 |
| %X | 只有时间没有日期的优先表示法。 |
| %y | 不带世纪的年份表示(00 到 99)。 |
| %Y | 带有世纪的年份。 |
| %Z | 时区名称。 |
| %% | % 字符。 |
时间算法
您可以用时间做一些简单的算术,如下所示:
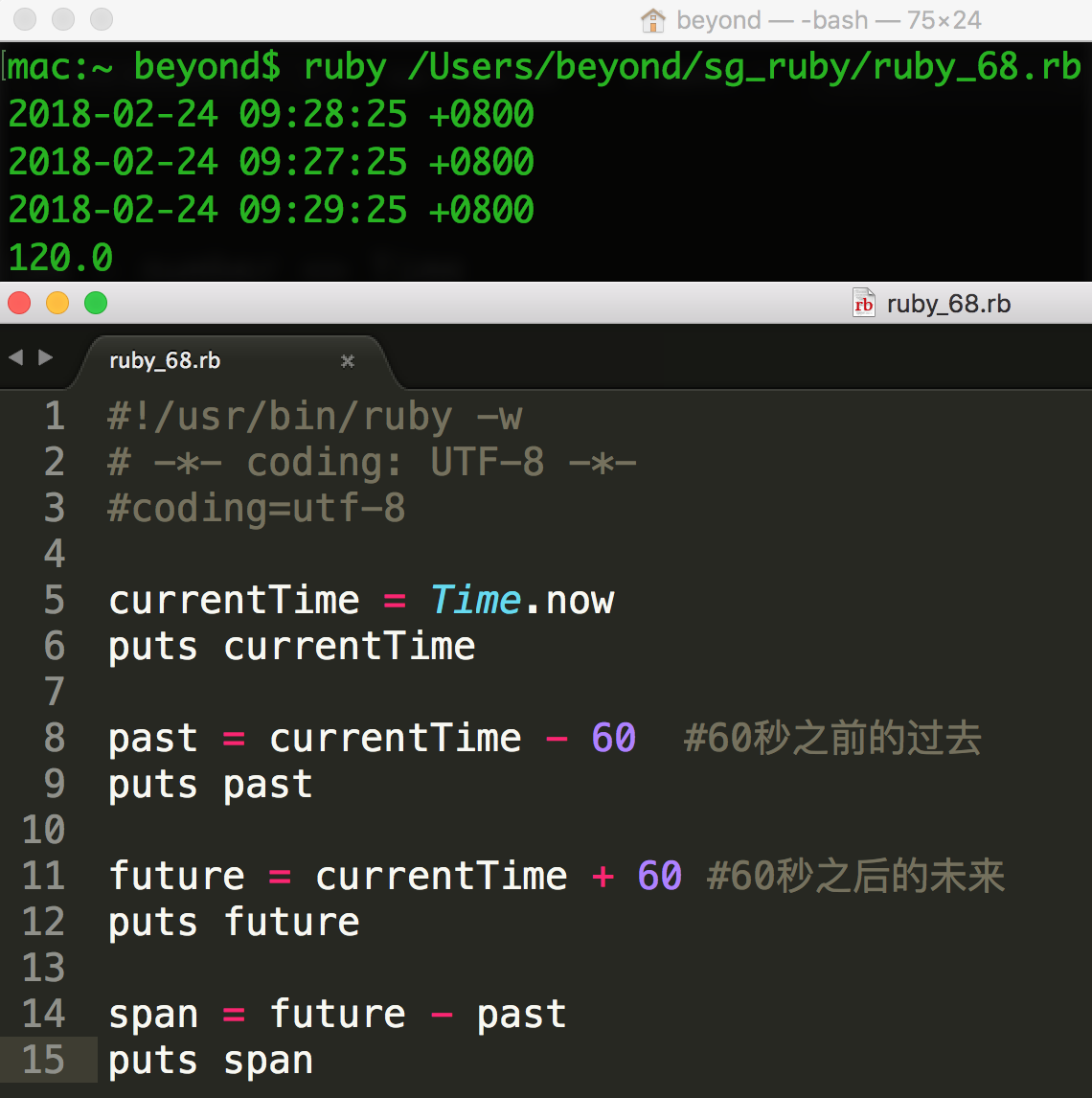
Ruby 范围(Range)
范围(Range)无处不在:January 到 December、 0 到 9、等等。
Ruby 支持范围,并允许我们以不同的方式使用范围:
- 作为序列的范围
- 作为条件的范围
- 作为间隔的范围
作为序列的范围
范围的第一个也是最常见的用途是表达序列。
序列有一个起点、一个终点和一个在序列产生连续值的方式。
Ruby 使用 ''..'' 和 ''...'' 范围运算符创建这些序列。
两点形式创建一个包含指定的最高值的范围,
三点形式创建一个不包含指定的最高值的范围。
(1..5) #==> 1, 2, 3, 4, 5
(1...5) #==> 1, 2, 3, 4
('a'..'d') #==> 'a', 'b', 'c', 'd'
序列 1..100 是一个 Range 对象,包含了两个 Fixnum 对象的引用。
如果需要,您可以使用 to_a 方法把范围转换为列表。尝试下面的实例:
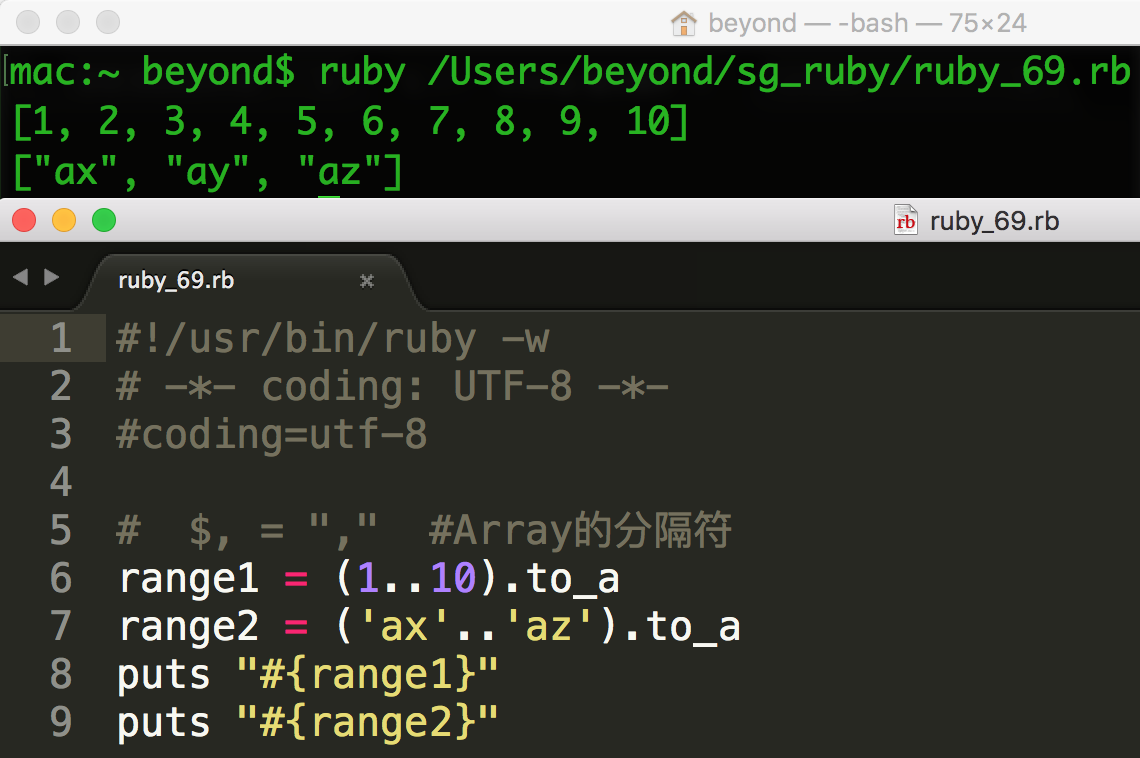
范围实现了让您可以遍历它们的方法,您可以通过多种方式检查它们的内容:
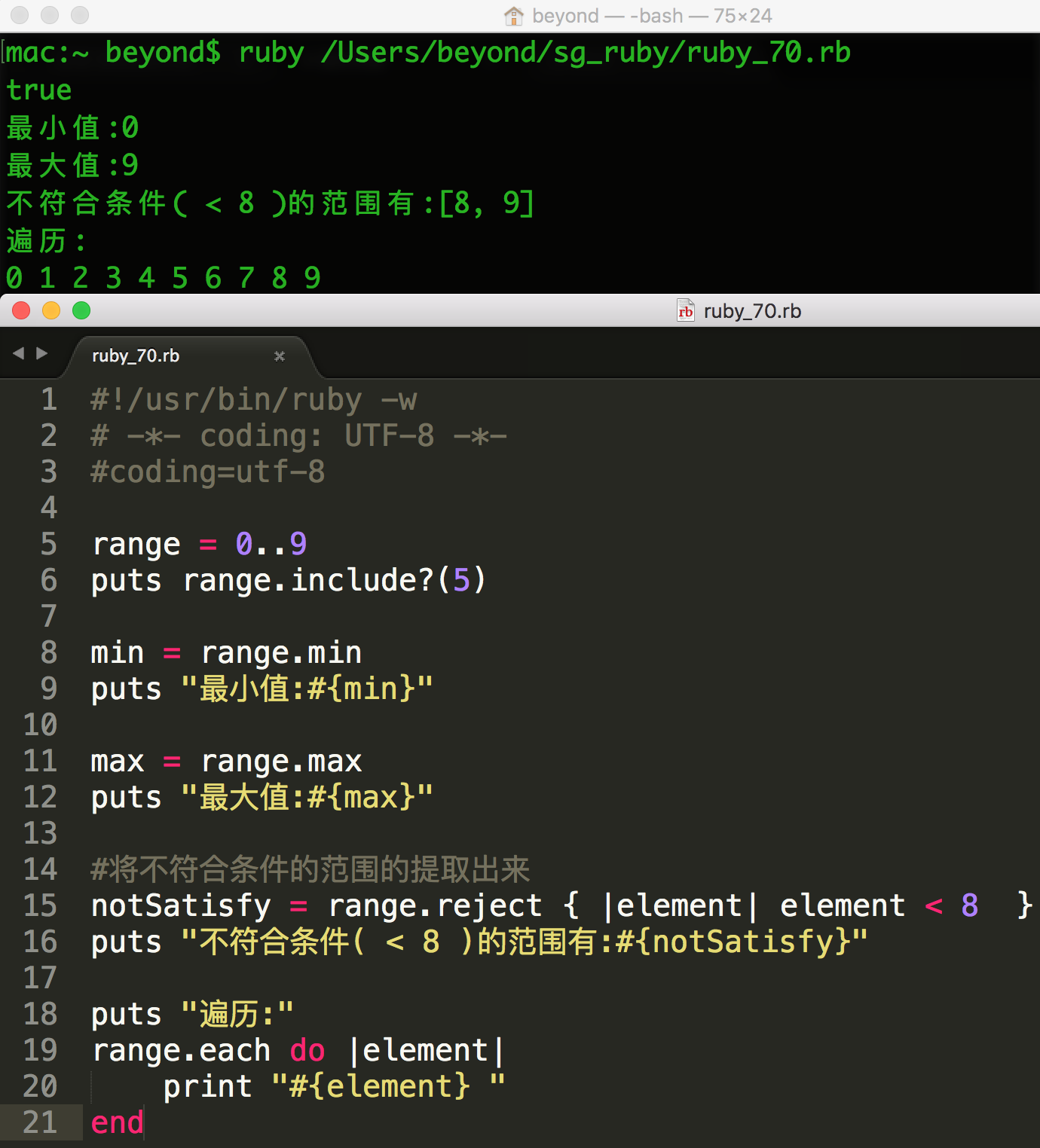
作为条件的范围
范围也可以用作条件表达式。
例如,下面的代码片段从标准输入打印行,其中每个集合的第一行包含单词 start,最后一行包含单词 end
???Excuse Me???
while gets
print if /start/../end/
end
范围可以用在 case 语句中:
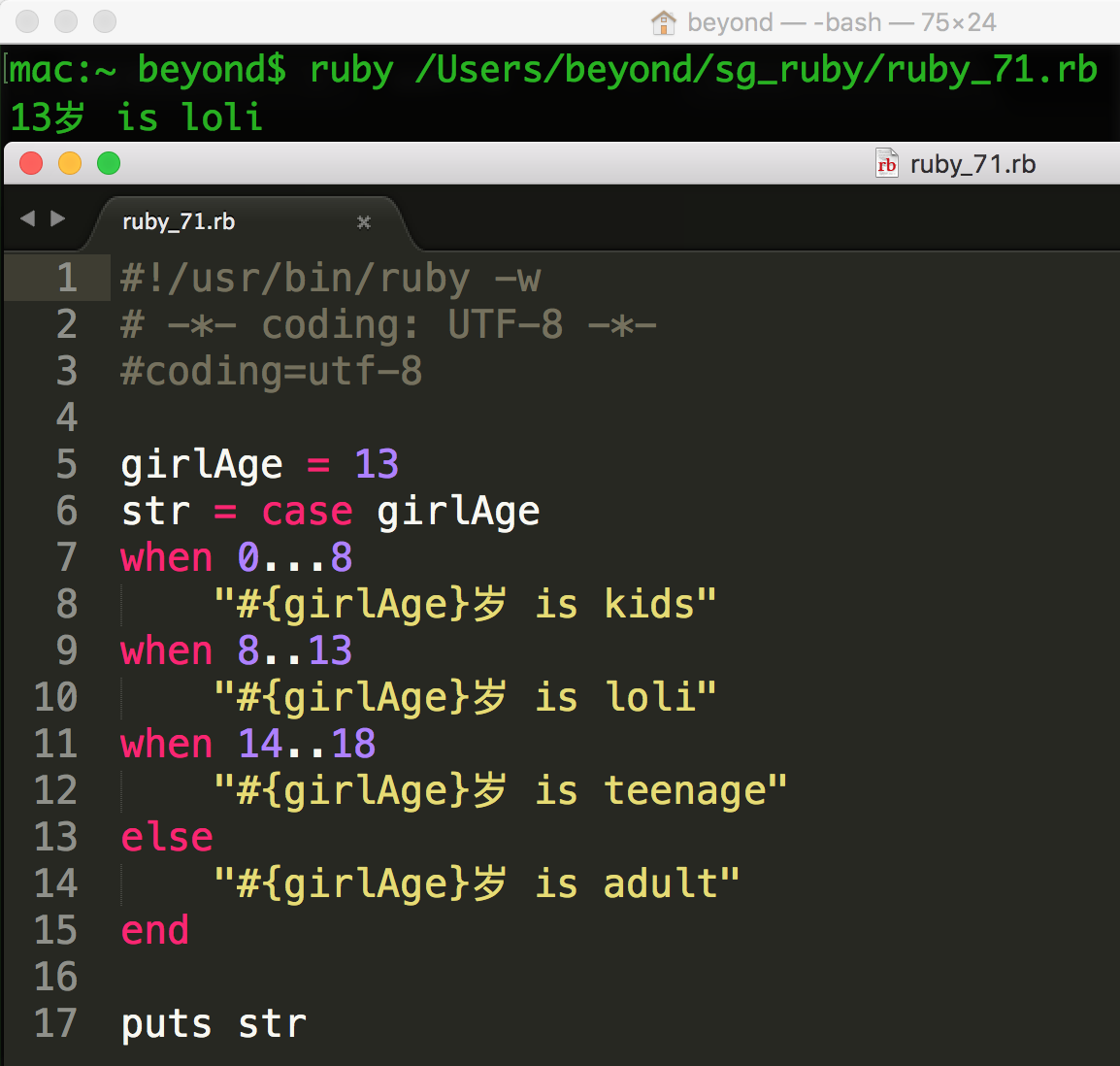
作为间隔的范围
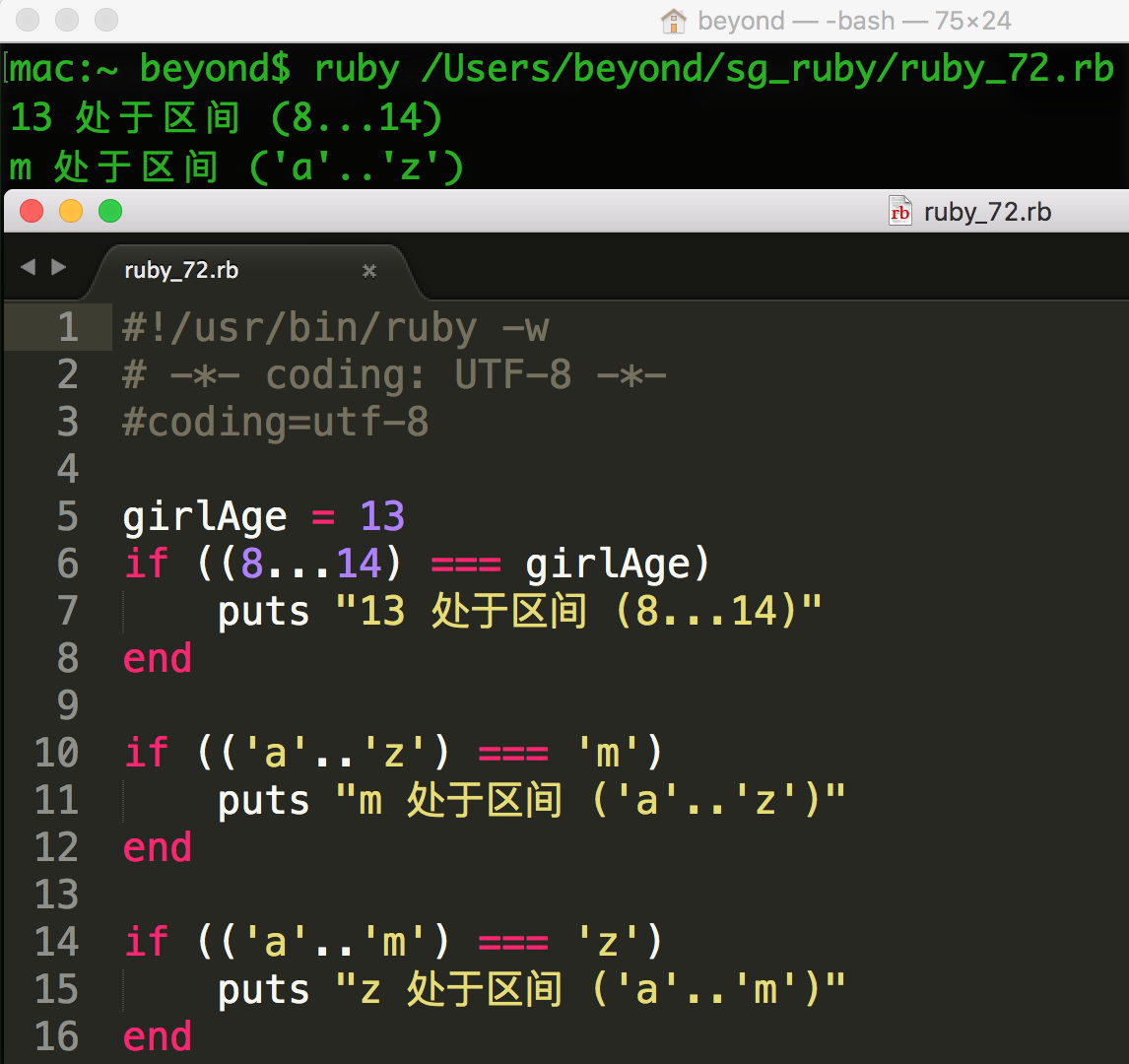
范围的最后一个用途是间隔测试:检查某些值是否落在范围表示的间隔里。
这是使用 === 相等运算符来完成计算
Ruby 迭代器 iterator
迭代器是集合支持的方法。
存储一组数据成员的对象称为集合。
在 Ruby 中,数组和散列可以称之为集合。
迭代器返回集合的所有元素,一个接着一个。
在这里我们将讨论两种迭代器,each 和 collect。
Ruby each 迭代器
each 迭代器返回数组或哈希的所有元素。
语法
collection.each do |element|
code
end
为集合中的每个元素执行 code。在这里,集合可以是数组或哈希。
实例
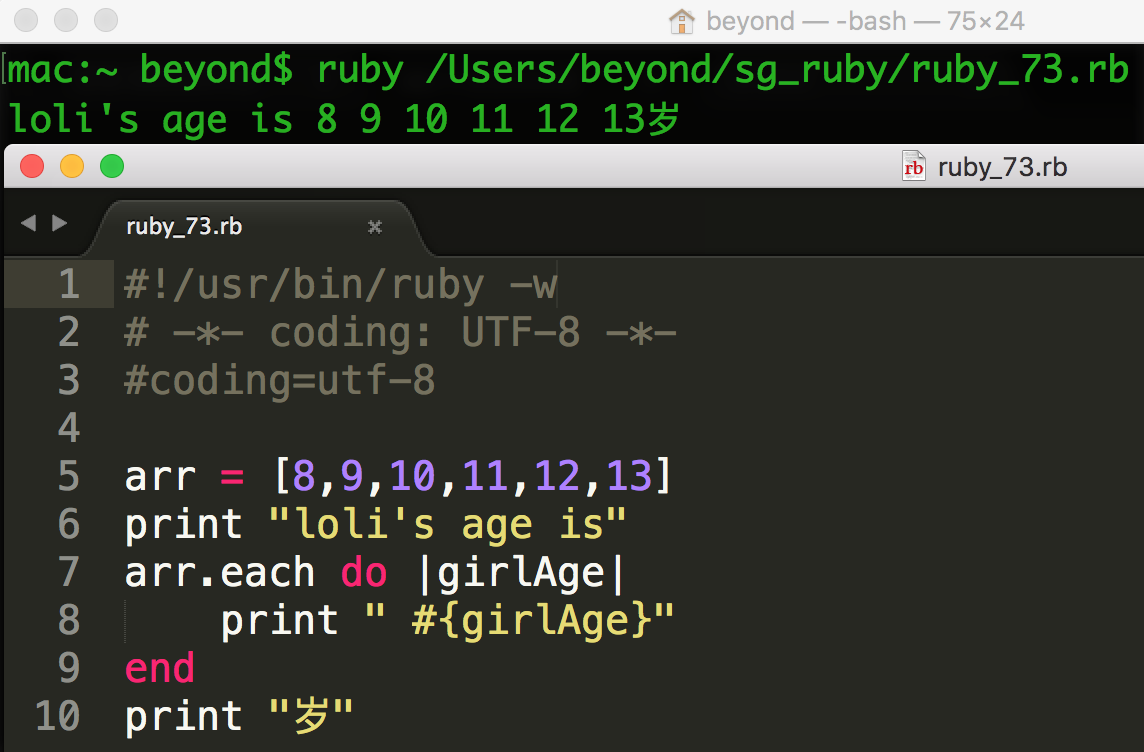
each 迭代器总是与一个块关联。
它向块返回数组的每个值,一个接着一个。
值被存储在变量 element 中,然后显示在屏幕上。
Ruby collect 迭代器 enumerator
collect 迭代器返回集合的所有元素。
语法
collection = collection.collect
collect 方法不需要总是与一个块关联。
collect 方法返回整个集合,不管它是数组或者是哈希。
实例
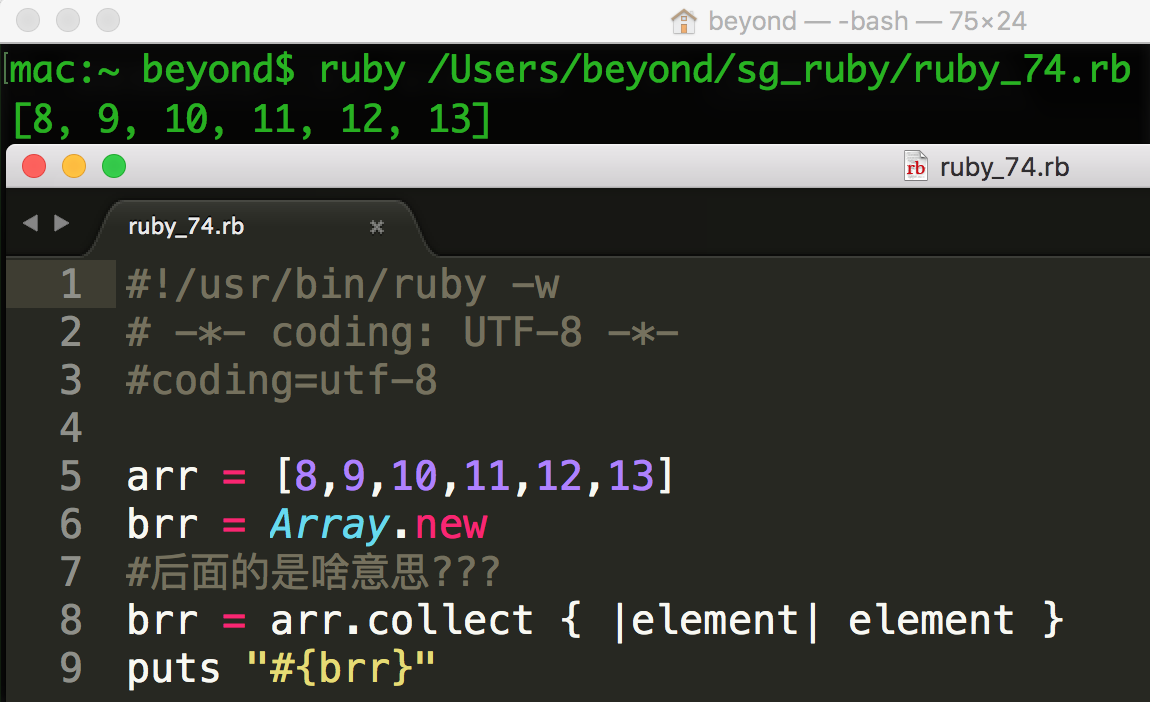
注意:collect 方法不是数组间进行复制的正确方式。
这里有另一个称为 clone 的方法,用于复制一个数组到另一个数组。
当您想要对每个值进行一些操作以便获得新的数组时,您通常使用 collect 方法。
例如,下面的代码会生成一个数组,其值是 a 中每个值的 10 倍。
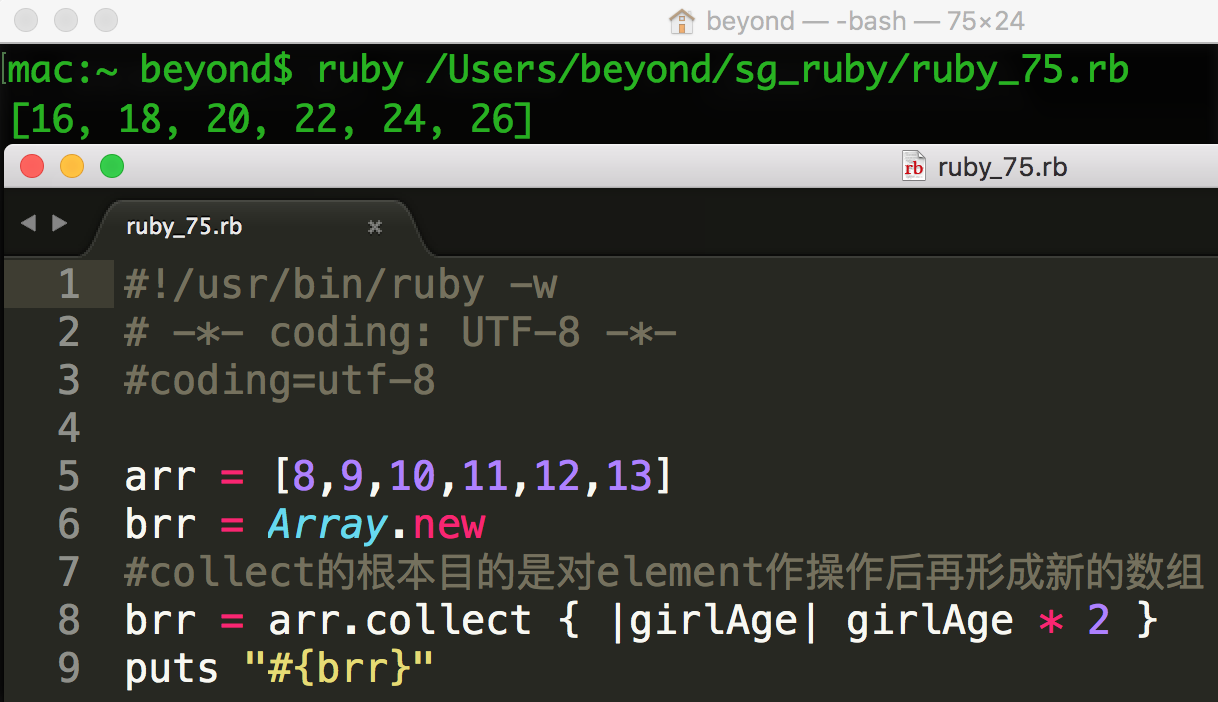
未完待续,下一章节,つづく
附录1:
下面是公共的字符串方法(假设 str 是一个 String 对象):
| 序号 | 方法 & 描述 |
|---|---|
| 1 | str % arg 使用格式规范格式化字符串。如果 arg 包含一个以上的替代,那么 arg 必须是一个数组。如需了解更多格式规范的信息,请查看"内核模块"下的 sprintf。 |
| 2 | str * integer 返回一个包含 integer 个 str 的新的字符串。换句话说,str 被重复了 integer 次。 |
| 3 | str + other_str 连接 other_str 到 str。 |
| 4 | str << obj 连接一个对象到字符串。如果对象是范围为 0.255 之间的固定数字 Fixnum,则它会被转换为一个字符。把它与 concat 进行比较。 |
| 5 | str <=> other_str 把 str 与 other_str 进行比较,返回 -1(小于)、0(等于)或 1(大于)。比较是区分大小写的。 |
| 6 | str == obj 检查 str 和 obj 的相等性。如果 obj 不是字符串,则返回 false,如果 str <=> obj,则返回 true,返回 0。 |
| 7 | str =~ obj 根据正则表达式模式 obj 匹配 str。返回匹配开始的位置,否则返回 false。 |
| 8 | str =~ obj 根据正则表达式模式 obj 匹配 str。返回匹配开始的位置,否则返回 false。 |
| 9 | str.capitalize 把字符串转换为首字母大写字母显示。 |
| 10 | str.capitalize! 与 capitalize 相同,但是 str 会发生变化并返回。 |
| 11 | str.casecmp 不区分大小写的字符串比较。 |
| 12 | str.center 居中字符串。 |
| 13 | str.chomp 从字符串末尾移除记录分隔符($/),通常是 \n。如果没有记录分隔符,则不进行任何操作。 |
| 14 | str.chomp! 与 chomp 相同,但是 str 会发生变化并返回。 |
| 15 | str.chop 移除 str 中的最后一个字符。 |
| 16 | str.chop! 与 chop 相同,但是 str 会发生变化并返回。 |
| 17 | str.concat(other_str) 连接 other_str 到 str。 |
| 18 | str.count(str, ...) 给一个或多个字符集计数。如果有多个字符集,则给这些集合的交集计数。 |
| 19 | str.crypt(other_str) 对 str 应用单向加密哈希。参数是两个字符长的字符串,每个字符的范围为 a.z、 A.Z、 0.9、 . 或 /。 |
| 20 | str.delete(other_str, ...) 返回 str 的副本,参数交集中的所有字符会被删除。 |
| 21 | str.delete!(other_str, ...) 与 delete 相同,但是 str 会发生变化并返回。 |
| 22 | str.downcase 返回 str 的副本,所有的大写字母会被替换为小写字母。 |
| 23 | str.downcase! 与 downcase 相同,但是 str 会发生变化并返回。 |
| 24 | str.dump 返回 str 的版本,所有的非打印字符被替换为 \nnn 符号,所有的特殊字符被转义。 |
| 25 | str.each(separator=$/) { |substr| block } 使用参数作为记录分隔符(默认是 $/)分隔 str,传递每个子字符串给被提供的块。 |
| 26 | str.each_byte { |fixnum| block } 传递 str 的每个字节给 block,以字节的十进制表示法返回每个字节。 |
| 27 | str.each_line(separator=$/) { |substr| block } 使用参数作为记录分隔符(默认是 $/)分隔 str,传递每个子字符串给被提供的 block。 |
| 28 | str.empty? 如果 str 为空(即长度为 0),则返回 true。 |
| 29 | str.eql?(other) 如果两个字符串有相同的长度和内容,则这两个字符串相等。 |
| 30 | str.gsub(pattern, replacement) [or] str.gsub(pattern) { |match| block } 返回 str 的副本,pattern 的所有出现都替换为 replacement 或 block 的值。pattern 通常是一个正则表达式 Regexp;如果是一个字符串 String,则没有正则表达式元字符被解释(即,/\d/ 将匹配一个数字,但 '\d' 将匹配一个反斜杠后跟一个 'd')。 |
| 31 | str[fixnum] [or] str[fixnum,fixnum] [or] str[range] [or] str[regexp] [or] str[regexp, fixnum] [or] str[other_str] 使用下列的参数引用 str:参数为一个 Fixnum,则返回 fixnum 的字符编码;参数为两个 Fixnum,则返回一个从偏移(第一个 fixnum)开始截至到长度(第二个 fixnum)为止的子字符串;参数为 range,则返回该范围内的一个子字符串;参数为 regexp,则返回匹配字符串的部分;参数为带有 fixnum 的 regexp,则返回 fixnum 位置的匹配数据;参数为 other_str,则返回匹配 other_str 的子字符串。一个负数的 Fixnum 从字符串的末尾 -1 开始。 |
| 32 | str[fixnum] = fixnum [or] str[fixnum] = new_str [or] str[fixnum, fixnum] = new_str [or] str[range] = aString [or] str[regexp] =new_str [or] str[regexp, fixnum] =new_str [or] str[other_str] = new_str ] 替换整个字符串或部分字符串。与 slice! 同义。 |
| 33 | str.gsub!(pattern, replacement) [or] str.gsub!(pattern) { |match| block } 执行 String#gsub 的替换,返回 str,如果没有替换被执行则返回 nil。 |
| 34 | str.hash 返回一个基于字符串长度和内容的哈希。 |
| 35 | str.hex 把 str 的前导字符当作十六进制数字的字符串(一个可选的符号和一个可选的 0x),并返回相对应的数字。如果错误则返回零。 |
| 36 | str.include? other_str [or] str.include? fixnum 如果 str 包含给定的字符串或字符,则返回 true。 |
| 37 | str.index(substring [, offset]) [or] str.index(fixnum [, offset]) [or] str.index(regexp [, offset]) 返回给定子字符串、字符(fixnum)或模式(regexp)在 str 中第一次出现的索引。如果未找到则返回 nil。如果提供了第二个参数,则指定在字符串中开始搜索的位置。 |
| 38 | str.insert(index, other_str) 在给定索引的字符前插入 other_str,修改 str。负值索引从字符串的末尾开始计数,并在给定字符后插入。其意图是在给定的索引处开始插入一个字符串。 |
| 39 | str.inspect 返回 str 的可打印版本,带有转义的特殊字符。 |
| 40 | str.intern [or] str.to_sym 返回与 str 相对应的符号,如果之前不存在,则创建符号。 |
| 41 | str.length 返回 str 的长度。把它与 size 进行比较。 |
| 42 | str.ljust(integer, padstr=' ') 如果 integer 大于 str 的长度,则返回长度为 integer 的新字符串,新字符串以 str 左对齐,并以 padstr 作为填充。否则,返回 str。 |
| 43 | str.lstrip 返回 str 的副本,移除了前导的空格。 |
| 44 | str.lstrip! 从 str 中移除前导的空格,如果没有变化则返回 nil。 |
| 45 | str.match(pattern) 如果 pattern 不是正则表达式,则把 pattern 转换为正则表达式 Regexp,然后在 str 上调用它的匹配方法。 |
| 46 | str.oct 把 str 的前导字符当作十进制数字的字符串(一个可选的符号),并返回相对应的数字。如果转换失败,则返回 0。 |
| 47 | str.replace(other_str) 把 str 中的内容替换为 other_str 中的相对应的值。 |
| 48 | str.reverse 返回一个新字符串,新字符串是 str 的倒序。 |
| 49 | str.reverse! 逆转 str,str 会发生变化并返回。 |
| 50 | str.rindex(substring [, fixnum]) [or] str.rindex(fixnum [, fixnum]) [or] str.rindex(regexp [, fixnum]) 返回给定子字符串、字符(fixnum)或模式(regexp)在 str 中最后一次出现的索引。如果未找到则返回 nil。如果提供了第二个参数,则指定在字符串中结束搜索的位置。超出该点的字符将不被考虑。 |
| 51 | str.rjust(integer, padstr=' ') 如果 integer 大于 str 的长度,则返回长度为 integer 的新字符串,新字符串以 str 右对齐,并以 padstr 作为填充。否则,返回 str。 |
| 52 | str.rstrip 返回 str 的副本,移除了尾随的空格。 |
| 53 | str.rstrip! 从 str 中移除尾随的空格,如果没有变化则返回 nil。 |
| 54 | str.scan(pattern) [or] str.scan(pattern) { |match, ...| block } 两种形式匹配 pattern(可以是一个正则表达式 Regexp 或一个字符串 String)遍历 str。针对每个匹配,会生成一个结果,结果会添加到结果数组中或传递给 block。如果 pattern 不包含分组,则每个独立的结果由匹配的字符串、$& 组成。如果 pattern 包含分组,每个独立的结果是一个包含每个分组入口的数组。 |
| 55 | str.slice(fixnum) [or] str.slice(fixnum, fixnum) [or] str.slice(range) [or] str.slice(regexp) [or] str.slice(regexp, fixnum) [or] str.slice(other_str) See str[fixnum], etc. str.slice!(fixnum) [or] str.slice!(fixnum, fixnum) [or] str.slice!(range) [or] str.slice!(regexp) [or] str.slice!(other_str) 从 str 中删除指定的部分,并返回删除的部分。如果值超出范围,参数带有 Fixnum 的形式,将生成一个 IndexError。参数为 range 的形式,将生成一个 RangeError,参数为 Regexp 和 String 的形式,将忽略执行动作。 |
| 56 | str.split(pattern=$;, [limit]) 基于分隔符,把 str 分成子字符串,并返回这些子字符串的数组。 如果 pattern 是一个字符串 String,那么在分割 str 时,它将作为分隔符使用。如果 pattern 是一个单一的空格,那么 str 是基于空格进行分割,会忽略前导空格和连续空格字符。 如果 pattern 是一个正则表达式 Regexp,则 str 在 pattern 匹配的地方被分割。当 pattern 匹配一个玲长度的字符串时,str 被分割成单个字符。 如果省略了 pattern 参数,则使用 $; 的值。如果 $; 为 nil(默认的),str 基于空格进行分割,就像是指定了 ` ` 作为分隔符一样。 如果省略了 limit 参数,会抑制尾随的 null 字段。如果 limit 是一个正数,则最多返回该数量的字段(如果 limit 为 1,则返回整个字符串作为数组中的唯一入口)。如果 limit 是一个负数,则返回的字段数量不限制,且不抑制尾随的 null 字段。 |
| 57 | str.squeeze([other_str]*) 使用为 String#count 描述的程序从 other_str 参数建立一系列字符。返回一个新的字符串,其中集合中出现的相同的字符会被替换为单个字符。如果没有给出参数,则所有相同的字符都被替换为单个字符。 |
| 58 | str.squeeze!([other_str]*) 与 squeeze 相同,但是 str 会发生变化并返回,如果没有变化则返回 nil。 |
| 59 | str.strip 返回 str 的副本,移除了前导的空格和尾随的空格。 |
| 60 | str.strip! 从 str 中移除前导的空格和尾随的空格,如果没有变化则返回 nil。 |
| 61 | str.sub(pattern, replacement) [or] str.sub(pattern) { |match| block } 返回 str 的副本,pattern 的第一次出现会被替换为 replacement 或 block 的值。pattern 通常是一个正则表达式 Regexp;如果是一个字符串 String,则没有正则表达式元字符被解释。 |
| 62 | str.sub!(pattern, replacement) [or] str.sub!(pattern) { |match| block } 执行 String#sub 替换,并返回 str,如果没有替换执行,则返回 nil。 |
| 63 | str.succ [or] str.next 返回 str 的继承。 |
| 64 | str.succ! [or] str.next! 相当于 String#succ,但是 str 会发生变化并返回。 |
| 65 | str.sum(n=16) 返回 str 中字符的 n-bit 校验和,其中 n 是可选的 Fixnum 参数,默认为 16。结果是简单地把 str 中每个字符的二进制值的总和,以 2n - 1 为模。这不是一个特别好的校验和。 |
| 66 | str.swapcase 返回 str 的副本,所有的大写字母转换为小写字母,所有的小写字母转换为大写字母。 |
| 67 | str.swapcase! 相当于 String#swapcase,但是 str 会发生变化并返回,如果没有变化则返回 nil。 |
| 68 | str.to_f 返回把 str 中的前导字符解释为浮点数的结果。超出有效数字的末尾的多余字符会被忽略。如果在 str 的开头没有有效数字,则返回 0.0。该方法不会生成异常。 |
| 69 | str.to_i(base=10) 返回把 str 中的前导字符解释为整数基数(基数为 2、 8、 10 或 16)的结果。超出有效数字的末尾的多余字符会被忽略。如果在 str 的开头没有有效数字,则返回 0。该方法不会生成异常。 |
| 70 | str.to_s [or] str.to_str 返回接收的值。 |
| 71 | str.tr(from_str, to_str) 返回 str 的副本,把 from_str 中的字符替换为 to_str 中相对应的字符。如果 to_str 比 from_str 短,那么它会以最后一个字符进行填充。两个字符串都可以使用 c1.c2 符号表示字符的范围。如果 from_str 以 ^ 开头,则表示除了所列出的字符以外的所有字符。 |
| 72 | str.tr!(from_str, to_str) 相当于 String#tr,但是 str 会发生变化并返回,如果没有变化则返回 nil。 |
| 73 | str.tr_s(from_str, to_str) 把 str 按照 String#tr 描述的规则进行处理,然后移除会影响翻译的重复字符。 |
| 74 | str.tr_s!(from_str, to_str) 相当于 String#tr_s,但是 str 会发生变化并返回,如果没有变化则返回 nil。 |
| 75 | str.unpack(format) 根据 format 字符串解码 str(可能包含二进制数据),返回被提取的每个值的数组。format 字符由一系列单字符指令组成。每个指令后可以跟着一个数字,表示重复该指令的次数。星号(*)将使用所有剩余的元素。指令 sSiIlL 每个后可能都跟着一个下划线(_),为指定类型使用底层平台的本地尺寸大小,否则使用独立于平台的一致的尺寸大小。format 字符串中的空格会被忽略。 |
| 76 | str.upcase 返回 str 的副本,所有的小写字母会被替换为大写字母。操作是环境不敏感的,只有字符 a 到 z 会受影响。 |
| 77 | str.upcase! 改变 str 的内容为大写,如果没有变化则返回 nil。 |
| 78 | str.upto(other_str) { |s| block } 遍历连续值,以 str 开始,以 other_str 结束(包含),轮流传递每个值给 block。String#succ 方法用于生成每个值。 |
字符串 unpack 指令
下表列出了方法 String#unpack 的解压指令。
| 指令 | 返回 | 描述 |
|---|---|---|
| A | String | 移除尾随的 null 和空格。 |
| a | String | 字符串。 |
| B | String | 从每个字符中提取位(首先是最高有效位)。 |
| b | String | 从每个字符中提取位(首先是最低有效位)。 |
| C | Fixnum | 提取一个字符作为无符号整数。 |
| c | Fixnum | 提取一个字符作为整数。 |
| D, d | Float | 把 sizeof(double) 长度的字符当作原生的 double。 |
| E | Float | 把 sizeof(double) 长度的字符当作 littleendian 字节顺序的 double。 |
| e | Float | 把 sizeof(float) 长度的字符当作 littleendian 字节顺序的 float。 |
| F, f | Float | 把 sizeof(float) 长度的字符当作原生的 float。 |
| G | Float | 把 sizeof(double) 长度的字符当作 network 字节顺序的 double。 |
| g | Float | 把 sizeof(float) 长度的字符当作 network 字节顺序的 float。 |
| H | String | 从每个字符中提取十六进制(首先是最高有效位)。 |
| h | String | 从每个字符中提取十六进制(首先是最低有效位)。 |
| I | Integer | 把 sizeof(int) 长度(通过 _ 修改)的连续字符当作原生的 integer。 |
| i | Integer | 把 sizeof(int) 长度(通过 _ 修改)的连续字符当作有符号的原生的 integer。 |
| L | Integer | 把四个(通过 _ 修改)连续字符当作无符号的原生的 long integer。 |
| l | Integer | 把四个(通过 _ 修改)连续字符当作有符号的原生的 long integer。 |
| M | String | 引用可打印的。 |
| m | String | Base64 编码。 |
| N | Integer | 把四个字符当作 network 字节顺序的无符号的 long。 |
| n | Fixnum | 把两个字符当作 network 字节顺序的无符号的 short。 |
| P | String | 把 sizeof(char *) 长度的字符当作指针,并从引用的位置返回 \emph{len} 字符。 |
| p | String | 把 sizeof(char *) 长度的字符当作一个空结束字符的指针。 |
| Q | Integer | 把八个字符当作无符号的 quad word(64 位)。 |
| q | Integer | 把八个字符当作有符号的 quad word(64 位)。 |
| S | Fixnum | 把两个(如果使用 _ 则不同)连续字符当作 native 字节顺序的无符号的 short。 |
| s | Fixnum | 把两个(如果使用 _ 则不同)连续字符当作 native 字节顺序的有符号的 short。 |
| U | Integer | UTF-8 字符,作为无符号整数。 |
| u | String | UU 编码。 |
| V | Fixnum | 把四个字符当作 little-endian 字节顺序的无符号的 long。 |
| v | Fixnum | 把两个字符当作 little-endian 字节顺序的无符号的 short。 |
| w | Integer | BER 压缩的整数。 |
| X | 向后跳过一个字符。 | |
| x | 向前跳过一个字符。 | |
| Z | String | 和 * 一起使用,移除尾随的 null 直到第一个 null。 |
| @ | 跳过 length 参数给定的偏移量。 |
实例
尝试下面的实例,解压各种数据。 ???Excuse Me???
"abc abc ".unpack('A6Z6') #=> ["abc", "abc "]
"abc ".unpack('a3a3') #=> ["abc", " 0000"]
"abc abc ".unpack('Z*Z*') #=> ["abc ", "abc "]
"aa".unpack('b8B8') #=> ["10000110", "01100001"]
"aaa".unpack('h2H2c') #=> ["16", "61", 97]
"\xfe\xff\xfe\xff".unpack('sS') #=> [-2, 65534]
"now=20is".unpack('M*') #=> ["now is"]
"whole".unpack('xax2aX2aX1aX2a') #=> ["h", "e", "l", "l", "o"]下面是公共的数组方法(假设 array 是一个 Array 对象):
| 序号 | 方法 & 描述 |
|---|---|
| 1 | array & other_array 返回一个新的数组,包含两个数组中共同的元素,没有重复。 |
| 2 | array * int [or] array * str 返回一个新的数组,新数组通过连接 self 的 int 副本创建的。带有 String 参数时,相当于 self.join(str)。 |
| 3 | array + other_array 返回一个新的数组,新数组通过连接两个数组产生第三个数组创建的。 |
| 4 | array - other_array 返回一个新的数组,新数组是从初始数组中移除了在 other_array 中出现的项的副本。 |
| 5 | str <=> other_str 把 str 与 other_str 进行比较,返回 -1(小于)、0(等于)或 1(大于)。比较是区分大小写的。 |
| 6 | array | other_array 通过把 other_array 加入 array 中,移除重复项,返回一个新的数组。 |
| 7 | array << obj 把给定的对象附加到数组的末尾。该表达式返回数组本身,所以几个附加可以连在一起。 |
| 8 | array <=> other_array 如果数组小于、等于或大于 other_array,则返回一个整数(-1、 0 或 +1)。 |
| 9 | array == other_array 如果两个数组包含相同的元素个数,且每个元素与另一个数组中相对应的元素相等(根据 Object.==),那么这两个数组相等。 |
| 10 | array[index] [or] array[start, length] [or] array[range] [or] array.slice(index) [or] array.slice(start, length) [or] array.slice(range) 返回索引为 index 的元素,或者返回从 start 开始直至 length 个元素的子数组,或者返回 range 指定的子数组。负值索引从数组末尾开始计数(-1 是最后一个元素)。如果 index(或开始索引)超出范围,则返回 nil。 |
| 11 | array[index] = obj [or] array[start, length] = obj or an_array or nil [or] array[range] = obj or an_array or nil 设置索引为 index 的元素,或者替换从 start 开始直至 length 个元素的子数组,或者替换 range 指定的子数组。如果索引大于数组的当前容量,那么数组会自动增长。负值索引从数组末尾开始计数。如果 length 为零则插入元素。如果在第二种或第三种形式中使用了 nil,则从 self 删除元素。 |
| 12 | array.abbrev(pattern = nil) 为 self 中的字符串计算明确的缩写集合。如果传递一个模式或一个字符串,只考虑当字符串匹配模式或者以该字符串开始时的情况。 |
| 13 | array.assoc(obj) 搜索一个数组,其元素也是数组,使用 obj.== 把 obj 与每个包含的数组的第一个元素进行比较。如果匹配则返回第一个包含的数组,如果未找到匹配则返回 nil。 |
| 14 | array.at(index) 返回索引为 index 的元素。一个负值索引从 self 的末尾开始计数。如果索引超出范围则返回 nil。 |
| 15 | array.clear 从数组中移除所有的元素。 |
| 16 | array.collect { |item| block } [or] array.map { |item| block } 为 self 中的每个元素调用一次 block。创建一个新的数组,包含 block 返回的值。 |
| 17 | array.collect! { |item| block } [or] array.map! { |item| block } 为 self 中的每个元素调用一次 block,把元素替换为 block 返回的值。 |
| 18 | array.compact 返回 self 的副本,移除了所有的 nil 元素。 |
| 19 | array.compact! 从数组中移除所有的 nil 元素。如果没有变化则返回 nil。 |
| 20 | array.concat(other_array) 追加 other_array 中的元素到 self 中。 |
| 21 | array.delete(obj) [or] array.delete(obj) { block } 从 self 中删除等于 obj 的项。如果未找到相等项,则返回 nil。如果未找到相等项且给出了可选的代码 block,则返回 block 的结果。 |
| 22 | array.delete_at(index) 删除指定的 index 处的元素,并返回该元素。如果 index 超出范围,则返回 nil。 |
| 23 | array.delete_if { |item| block } 当 block 为 true 时,删除 self 的每个元素。 |
| 24 | array.each { |item| block } 为 self 中的每个元素调用一次 block,传递该元素作为参数。 |
| 25 | array.each_index { |index| block } 与 Array#each 相同,但是传递元素的 index,而不是传递元素本身。 |
| 26 | array.empty? 如果数组本身没有包含元素,则返回 true。 |
| 27 | array.eql?(other) 如果 array 和 other 是相同的对象,或者两个数组带有相同的内容,则返回 true。 |
| 28 | array.fetch(index) [or] array.fetch(index, default) [or] array.fetch(index) { |index| block } 尝试返回位置 index 处的元素。如果 index 位于数组外部,则第一种形式会抛出 IndexError 异常,第二种形式会返回 default,第三种形式会返回调用 block 传入 index 的值。负值的 index 从数组末尾开始计数。 |
| 29 | array.fill(obj) [or] array.fill(obj, start [, length]) [or] array.fill(obj, range) [or] array.fill { |index| block } [or] array.fill(start [, length] ) { |index| block } [or] array.fill(range) { |index| block } 前面三种形式设置 self 的被选元素为 obj。以 nil 开头相当于零。nil 的长度相当于 self.length。最后三种形式用 block 的值填充数组。block 通过带有被填充的每个元素的绝对索引来传递。 |
| 30 | array.first [or] array.first(n) 返回数组的第一个元素或前 n 个元素。如果数组为空,则第一种形式返回 nil,第二种形式返回一个空的数组。 |
| 31 | array.flatten 返回一个新的数组,新数组是一个一维的扁平化的数组(递归)。 |
| 32 | array.flatten! 把 array 进行扁平化。如果没有变化则返回 nil。(数组不包含子数组。) |
| 33 | array.frozen? 如果 array 被冻结(或排序时暂时冻结),则返回 true。 |
| 34 | array.hash 计算数组的哈希代码。两个具有相同内容的数组将具有相同的哈希代码。 |
| 35 | array.include?(obj) 如果 self 中包含 obj,则返回 true,否则返回 false。 |
| 36 | array.index(obj) 返回 self 中第一个等于 obj 的对象的 index。如果未找到匹配则返回 nil。 |
| 37 | array.indexes(i1, i2, ... iN) [or] array.indices(i1, i2, ... iN) 该方法在 Ruby 的最新版本中被废弃,所以请使用 Array#values_at。 |
| 38 | array.indices(i1, i2, ... iN) [or] array.indexes(i1, i2, ... iN) 该方法在 Ruby 的最新版本中被废弃,所以请使用 Array#values_at。 |
| 39 | array.insert(index, obj...) 在给定的 index 的元素前插入给定的值,index 可以是负值。 |
| 40 | array.inspect 创建一个数组的可打印版本。 |
| 41 | array.join(sep=$,) 返回一个字符串,通过把数组的每个元素转换为字符串,并使用 sep 分隔进行创建的。 |
| 42 | array.last [or] array.last(n) 返回 self 的最后一个元素。如果数组为空,则第一种形式返回 nil。 |
| 43 | array.length 返回 self 中元素的个数。可能为零。 |
| 44 | array.map { |item| block } [or] array.collect { |item| block } 为 self 的每个元素调用一次 block。创建一个新的数组,包含 block 返回的值。 |
| 45 | array.map! { |item| block } [or] array.collect! { |item| block } 为 array 的每个元素调用一次 block,把元素替换为 block 返回的值。 |
| 46 | array.nitems 返回 self 中 non-nil 元素的个数。可能为零。 |
| 47 | array.pack(aTemplateString) 根据 aTemplateString 中的指令,把数组的内容压缩为二进制序列。指令 A、 a 和 Z 后可以跟一个表示结果字段宽度的数字。剩余的指令也可以带有一个表示要转换的数组元素个数的数字。如果数字是一个星号(*),则所有剩余的数组元素都将被转换。任何指令后都可以跟一个下划线(_),表示指定类型使用底层平台的本地尺寸大小,否则使用独立于平台的一致的尺寸大小。在模板字符串中空格会被忽略。 |
| 48 | array.pop 从 array 中移除最后一个元素,并返回该元素。如果 array 为空则返回 nil。 |
| 49 | array.push(obj, ...) 把给定的 obj 附加到数组的末尾。该表达式返回数组本身,所以几个附加可以连在一起。 |
| 50 | array.rassoc(key) 搜索一个数组,其元素也是数组,使用 == 把 key 与每个包含的数组的第二个元素进行比较。如果匹配则返回第一个包含的数组。 |
| 51 | array.reject { |item| block } 返回一个新的数组,包含当 block 不为 true 时的数组项。 |
| 52 | array.reject! { |item| block } 当 block 为真时,从 array 删除元素,如果没有变化则返回 nil。相当于 Array#delete_if。 |
| 53 | array.replace(other_array) 把 array 的内容替换为 other_array 的内容,必要的时候进行截断或扩充。 |
| 54 | array.reverse 返回一个新的数组,包含倒序排列的数组元素。 |
| 55 | array.reverse! 把 array 进行逆转。 |
| 56 | array.reverse_each {|item| block } 与 Array#each 相同,但是把 array 进行逆转。 |
| 57 | array.rindex(obj) 返回 array 中最后一个等于 obj 的对象的索引。如果未找到匹配,则返回 nil。 |
| 58 | array.select {|item| block } 调用从数组传入连续元素的 block,返回一个数组,包含 block 返回 true 值时的元素。 |
| 59 | array.shift 返回 self 的第一个元素,并移除该元素(把所有的其他元素下移一位)。如果数组为空,则返回 nil。 |
| 60 | array.size 返回 array 的长度(元素的个数)。length 的别名。 |
| 61 | array.slice(index) [or] array.slice(start, length) [or] array.slice(range) [or] array[index] [or] array[start, length] [or] array[range] 返回索引为 index 的元素,或者返回从 start 开始直至 length 个元素的子数组,或者返回 range 指定的子数组。负值索引从数组末尾开始计数(-1 是最后一个元素)。如果 index(或开始索引)超出范围,则返回 nil。 |
| 62 | array.slice!(index) [or] array.slice!(start, length) [or] array.slice!(range) 删除 index(长度是可选的)或 range 指定的元素。返回被删除的对象、子数组,如果 index 超出范围,则返回 nil。 |
| 63 | array.sort [or] array.sort { | a,b | block } 返回一个排序的数组。 |
| 64 | array.sort! [or] array.sort! { | a,b | block } 把数组进行排序。 |
| 65 | array.to_a 返回 self。如果在 Array 的子类上调用,则把接收参数转换为一个 Array 对象。 |
| 66 | array.to_ary 返回 self。 |
| 67 | array.to_s 返回 self.join。 |
| 68 | array.transpose 假设 self 是数组的数组,且置换行和列。 |
| 69 | array.uniq 返回一个新的数组,移除了 array 中的重复值。 |
| 70 | array.uniq! 从 self 中移除重复元素。如果没有变化(也就是说,未找到重复),则返回 nil。 |
| 71 | array.unshift(obj, ...) 把对象前置在数组的前面,其他元素上移一位。 |
| 72 | array.values_at(selector,...) 返回一个数组,包含 self 中与给定的 selector(一个或多个)相对应的元素。选择器可以是整数索引或者范围。 |
| 73 | array.zip(arg, ...) [or] array.zip(arg, ...){ | arr | block } 把任何参数转换为数组,然后把 array 的元素与每个参数中相对应的元素合并。 |
数组 pack 指令
下表列出了方法 Array#pack 的压缩指令。
| 指令 | 描述 |
|---|---|
| @ | 移动到绝对位置。 |
| A | ASCII 字符串(填充 space,count 是宽度)。 |
| a | ASCII 字符串(填充 null,count 是宽度)。 |
| B | 位字符串(降序) |
| b | 位字符串(升序)。 |
| C | 无符号字符。 |
| c | 字符。 |
| D, d | 双精度浮点数,原生格式。 |
| E | 双精度浮点数,little-endian 字节顺序。 |
| e | 单精度浮点数,little-endian 字节顺序。 |
| F, f | 单精度浮点数,原生格式。 |
| G | 双精度浮点数,network(big-endian)字节顺序。 |
| g | 单精度浮点数,network(big-endian)字节顺序。 |
| H | 十六进制字符串(高位优先)。 |
| h | 十六进制字符串(低位优先)。 |
| I | 无符号整数。 |
| i | 整数。 |
| L | 无符号 long。 |
| l | Long。 |
| M | 引用可打印的,MIME 编码。 |
| m | Base64 编码字符串。 |
| N | Long,network(big-endian)字节顺序。 |
| n | Short,network(big-endian)字节顺序。 |
| P | 指向一个结构(固定长度的字符串)。 |
| p | 指向一个空结束字符串。 |
| Q, q | 64 位数字。 |
| S | 无符号 short。 |
| s | Short。 |
| U | UTF-8。 |
| u | UU 编码字符串。 |
| V | Long,little-endian 字节顺序。 |
| v | Short,little-endian 字节顺序。 |
| w | BER 压缩的整数 \fnm。 |
| X | 向后跳过一个字节。 |
| x | Null 字节。 |
| Z | 与 a 相同,除了 null 会被加上 *。 |
实例
尝试下面的实例,压缩各种数据。
a = [ "a", "b", "c" ]
n = [ 65, 66, 67 ]
puts a.pack("A3A3A3") #=> "a b c "
puts a.pack("a3a3a3") #=> "a0000b0000c0000"
puts n.pack("ccc") #=> "ABC"
这将产生以下结果:
a b c
abc
ABC下面是公共的哈希方法(假设 hash 是一个 Hash 对象):
| 序号 | 方法 & 描述 |
|---|---|
| 1 | hash == other_hash 检查两个哈希是否具有相同的键值对个数,键值对是否相互匹配,来判断两个哈希是否相等。 |
| 2 | hash.[key] 使用键,从哈希引用值。如果未找到键,则返回默认值。 |
| 3 | hash.[key]=value 把 value 给定的值与 key 给定的键进行关联。 |
| 4 | hash.clear 从哈希中移除所有的键值对。 |
| 5 | hash.default(key = nil) 返回 hash 的默认值,如果未通过 default= 进行设置,则返回 nil。(如果键在 hash 中不存在,则 [] 返回一个默认值。) |
| 6 | hash.default = obj 为 hash 设置默认值。 |
| 7 | hash.default_proc 如果 hash 通过块来创建,则返回块。 |
| 8 | hash.delete(key) [or] array.delete(key) { |key| block } 通过 key 从 hash 中删除键值对。如果使用了块 且未找到匹配的键值对,则返回块的结果。把它与 delete_if 进行比较。 |
| 9 | hash.delete_if { |key,value| block } 为 block 为 true 的每个块,从 hash 中删除键值对。 |
| 10 | hash.each { |key,value| block } 遍历 hash,为每个 key 调用一次 block,传递 key-value 作为一个二元素数组。 |
| 11 | hash.each_key { |key| block } 遍历 hash,为每个 key 调用一次 block,传递 key 作为参数。 |
| 12 | hash.each_key { |key_value_array| block } 遍历 hash,为每个 key 调用一次 block,传递 key 和 value 作为参数。 |
| 13 | hash.each_key { |value| block } 遍历 hash,为每个 key 调用一次 block,传递 value 作为参数。 |
| 14 | hash.empty? 检查 hash 是否为空(不包含键值对),返回 true 或 false。 |
| 15 | hash.fetch(key [, default] ) [or] hash.fetch(key) { | key | block } 通过给定的 key 从 hash 返回值。如果未找到 key,且未提供其他参数,则抛出 IndexError 异常;如果给出了 default,则返回 default;如果指定了可选的 block,则返回 block 的结果。 |
| 16 | hash.has_key?(key) [or] hash.include?(key) [or] hash.key?(key) [or] hash.member?(key) 检查给定的 key 是否存在于哈希中,返回 true 或 false。 |
| 17 | hash.has_value?(value) 检查哈希是否包含给定的 value。 |
| 18 | hash.index(value) 为给定的 value 返回哈希中的 key,如果未找到匹配值则返回 nil。 |
| 19 | hash.indexes(keys) 返回一个新的数组,由给定的键的值组成。找不到的键将插入默认值。该方法已被废弃,请使用 select。 |
| 20 | hash.indices(keys) 返回一个新的数组,由给定的键的值组成。找不到的键将插入默认值。该方法已被废弃,请使用 select。 |
| 21 | hash.inspect 返回哈希的打印字符串版本。 |
| 22 | hash.invert 创建一个新的 hash,倒置 hash 中的 keys 和 values。也就是说,在新的哈希中,hash 中的键将变成值,值将变成键。 |
| 23 | hash.keys 创建一个新的数组,带有 hash 中的键。/td> |
| 24 | hash.length 以整数形式返回 hash 的大小或长度。 |
| 25 | hash.merge(other_hash) [or] hash.merge(other_hash) { |key, oldval, newval| block } 返回一个新的哈希,包含 hash 和 other_hash 的内容,重写 hash 中与 other_hash 带有重复键的键值对。 |
| 26 | hash.merge!(other_hash) [or] hash.merge!(other_hash) { |key, oldval, newval| block } 与 merge 相同,但实际上 hash 发生了变化。 |
| 27 | hash.rehash 基于每个 key 的当前值重新建立 hash。如果插入后值发生了改变,该方法会重新索引 hash。 |
| 28 | hash.reject { |key, value| block } 为 block 为 true 的每个键值对创建一个新的 hash。 |
| 29 | hash.reject! { |key, value| block } 与 reject 相同,但实际上 hash 发生了变化。 |
| 30 | hash.replace(other_hash) 把 hash 的内容替换为 other_hash 的内容。 |
| 31 | hash.select { |key, value| block } 返回一个新的数组,由 block 返回 true 的 hash 中的键值对组成。 |
| 32 | hash.shift 从 hash 中移除一个键值对,并把该键值对作为二元素数组返回。 |
| 33 | hash.size 以整数形式返回 hash 的 size 或 length。 |
| 34 | hash.sort 把 hash 转换为一个包含键值对数组的二维数组,然后进行排序。 |
| 35 | hash.store(key, value) 存储 hash 中的一个键值对。 |
| 36 | hash.to_a 从 hash 中创建一个二维数组。每个键值对转换为一个数组,所有这些数组都存储在一个数组中。 |
| 37 | hash.to_hash 返回 hash(self)。 |
| 38 | hash.to_s 把 hash 转换为一个数组,然后把该数组转换为一个字符串。 |
| 39 | hash.update(other_hash) [or] hash.update(other_hash) {|key, oldval, newval| block} 返回一个新的哈希,包含 hash 和 other_hash 的内容,重写 hash 中与 other_hash 带有重复键的键值对。 |
| 40 | hash.value?(value) 检查 hash 是否包含给定的 value。 |
| 41 | hash.values 返回一个新的数组,包含 hash 的所有值。 |
| 42 | hash.values_at(obj, ...) 返回一个新的数组,包含 hash 中与给定的键相关的值。 |
未完待续,下一章节,つづく














 437
437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









