







主成分分析(PCA) 在很多教程中做了介绍,但是为何通过协方差矩阵的特征值分解能够得到数据的主成分?协方差矩阵和特征值为何如此神奇,我却一直没弄清。今天终于把整个过程整理出来,方便自己学习,也和大家交流。
- 提出背景
以二维特征为例,两个特征之间可能存在线性关系的(例如这两个特征分别是运动的时速和秒速度),这样就造成了第二维信息是冗余的。PCA的目标是为了发现这种特征之间的线性关系,检测出这些线性关系,并且去除这线性关系。
还是以二维特征为例,如下图。特征之间可能不存在完全的线性关系,可能只是强的正相关。如果把x-y坐标分解成u1-u2坐标,而u1轴线上反应了特征的主要变化(intrinsic),而u2的特征变化较小,其实可以完全理解为一些噪声的扰动而不去考虑它。PCA的任务就是找到u1和u2。
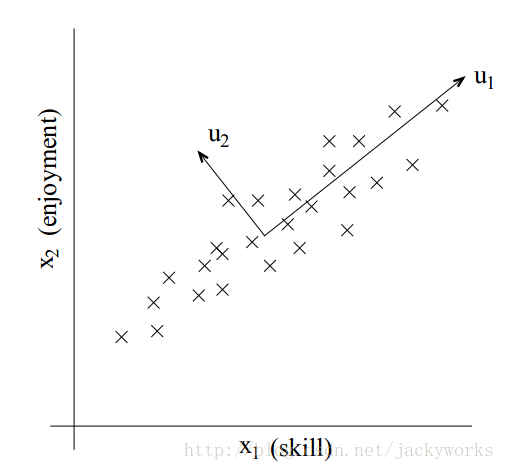
- 预处理:
将每一维特征的均值中心化,方差归一化。
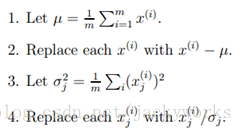
- PCA的数学目标:
特征的主方向,就是特征幅度变化最大的方向(“major>Tu(第一次错误地写成了d=x,感谢@zsfcg的留言,现已改正)。所有的样本点都在一个方向投影后,他们就都在同一条直线上了。而要比较它们之间变化的程度,只要比较d的方差就行。方差最大的u对应的方向就是我们要寻找的主方向。因此,我们的目标函数就成为了:

其中x的上标i表示数据集中的第i个样本,m表示数据集中的样本总数。(因为x已经中心化了,所以xu的均值也为0,因此xu的平方只和就是方差。)
括号中的一项十分熟悉,就是协方差矩阵Σ!终于知道协方差矩阵是怎么来的了。再看一看上面的式子,协方差矩阵与投影的方向无关,之于数据集中的样本有关,因此协方差矩阵完全决定了数据的分布及变化情况(请和自相关矩阵区别)。
目标函数如下:
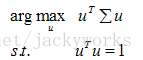
用拉格朗日乘数法求解上面的最大化问题,很容易得到:
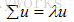
看见没?!u就是Σ的特征向量,λ就是特征值。我们再把(3)代入(2),目标函数就变成了
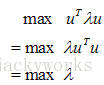
可见,可以通过协方差矩阵的迹衡量方差的大小。最大的特征值λ(以及对应的特征向量u)决定了数据变化最大的方向。u就是这个单位方向。因此PCA的求解过程就是对协方差矩阵进行特征值分解,并找到最大的几个特征值的过程。
再后面的过程就是由最大的k个特征值对应的特征向量组成一组新的基(basis),让原特征对这个新的基投影得到降维后的新特征。这个过程很多教程都介绍的很清楚了,我就不描述了。
不过我还是想补充一下矩阵及其特征值的意义。矩阵应理解为一种空间变换(从一个空间到另一个空间的变换)。矩阵M是m×n维的,如果m=n则变换后空间维数不变,如果n<m则是降维了。我们考虑m=n的方阵。对M进行特征值分解,得到一组新的基,这组基可以理解为m维空间下的一组新的基坐标(引入它是因为这组基坐标是一种更有效的表达Rm维空间的方式),而对应的特征值,就是投影在基坐标下相应维的响应程度。如果特征值为0,代表在这一维下没有相应,不管是多少,乘过来都是0。特征值如果很接近0,那么任何数在这一维下投影后都会变小很多。所以从降维的角度考虑,可以将这一维忽略(也就是PCA中保留前k个特征值的目的)。奇异值分解也是同样的道理。
PCA其实是最简单的降维方法之一了,很明显的劣势是它仅去除数据之间的线性相关性。对线性的改善往往通过kernel技术拓展到非线性的应用上。另外,PCA的这种降维不一定有助于分类,用于分类的降维方法之一就是LDA。从另一方面说,PCA是一种线性投影,保留了数据与数据之间的欧式距离,即原来欧式距离大的两点在降维后的空间中距离也应大(这样才好保证方差大)。而事实上数据有可能呈现某种流型结构,用PCA降维后数据将不能保持原有的流型结构。在这一方面常用的非线性降维方法是Locally linear embedding和Laplacian Eigenmaps,如下图所示:
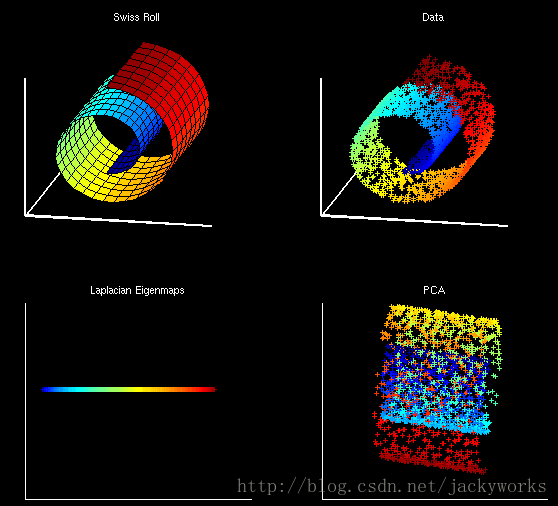
PCA的另一种推导方式是最小化投影后的损失(把降维理解为压缩,压缩后还原所得到的误差最小),在这篇文章中也有具体介绍,我也不多说了。
写到这里,才发现我啥也没说,都是提供了各种文献的链接。
另外,关于特征值和特征向量的更深理解,可以看本文。
--------------------
jiang1st2010
原文地址:http://blog.csdn.net/jiang1st2010/article/details/8935219














 2054
2054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









