







之前一直在看机器学习,遇到了一些需要爬取数据的内容,于是稍微看了看Python爬虫,在此适当做一个记录。我也没有深入研究爬虫,大部分均是参考了网上的资源。
先推荐两个Python爬虫的教程,网址分别是http://cuiqingcai.com/1052.html 和 http://ddswhu.com/2015/03/25/python-downloadhelper-premium/ ,我就是看这两个当做基本的入门。
有兴趣才有动力,既然学了爬虫,那就先爬取美女照片吧。当然,这里先并不是爬取好友的照片了,比如QQ空间、人人之类的,因为这些还涉及模拟登录之类的操作。为了方便,还是爬取贴吧里的图片。主要是参考了Github上这个项目:https://github.com/Yixiaohan/show-me-the-code (Python 练习册,每天一个小项目),感觉还是很不错的。
先来看上面那个项目里的第13题,要求是爬取这个网址中的图片:http://tieba.baidu.com/p/2166231880,参考了网友renzongxian 的代码(使用版本为Python 3.4),如下:
# 爬取贴吧图片,网址:http://tieba.baidu.com/p/2166231880
import urllib.request
import re
import os
def fetch_pictures(url):
html_content = urllib.request.urlopen(url).read()
r = re.compile('<img pic_type="0" class="BDE_Image" src="(.*?)"')
picture_url_list = r.findall(html_content.decode('utf-8'))
os.mkdir('pictures')
os.chdir(os.path.join(os.getcwd(), 'pictures'))
for i in range(len(picture_url_list)):
picture_name = str(i) + '.jpg'
try:
urllib.request.urlretrieve(picture_url_list[i], picture_name)
print("Success to download " + picture_url_list[i])
except:
print("Fail to download " + picture_url_list[i])
if __name__ == '__main__':
fetch_pictures("http://tieba.baidu.com/p/2166231880")运行之后,会生成一个名为pictures的文件夹,自动下载图片并存放进去(图片就不截图了)。
为了测试该程序,我看了另一个Python爬虫的代码,准备把网址替换一下,即爬取这个网址中的图片:http://tieba.baidu.com/p/2460150866 ,只需要将上述代码稍作修改(把网址换一下,文件夹改一下)即可,如下
# 爬取贴吧图片,网址:http://tieba.baidu.com/p/2460150866
import urllib.request
import re
import os
def fetch_pictures(url):
html_content = urllib.request.urlopen(url).read()
r = re.compile('<img pic_type="0" class="BDE_Image" src="(.*?)"')
picture_url_list = r.findall(html_content.decode('utf-8'))
os.mkdir('photos')
os.chdir(os.path.join(os.getcwd(), 'photos'))
for i in range(len(picture_url_list)):
picture_name = str(i) + '.jpg'
try:
urllib.request.urlretrieve(picture_url_list[i], picture_name)
print("Success to download " + picture_url_list[i])
except:
print("Fail to download " + picture_url_list[i])
if __name__ == '__main__':
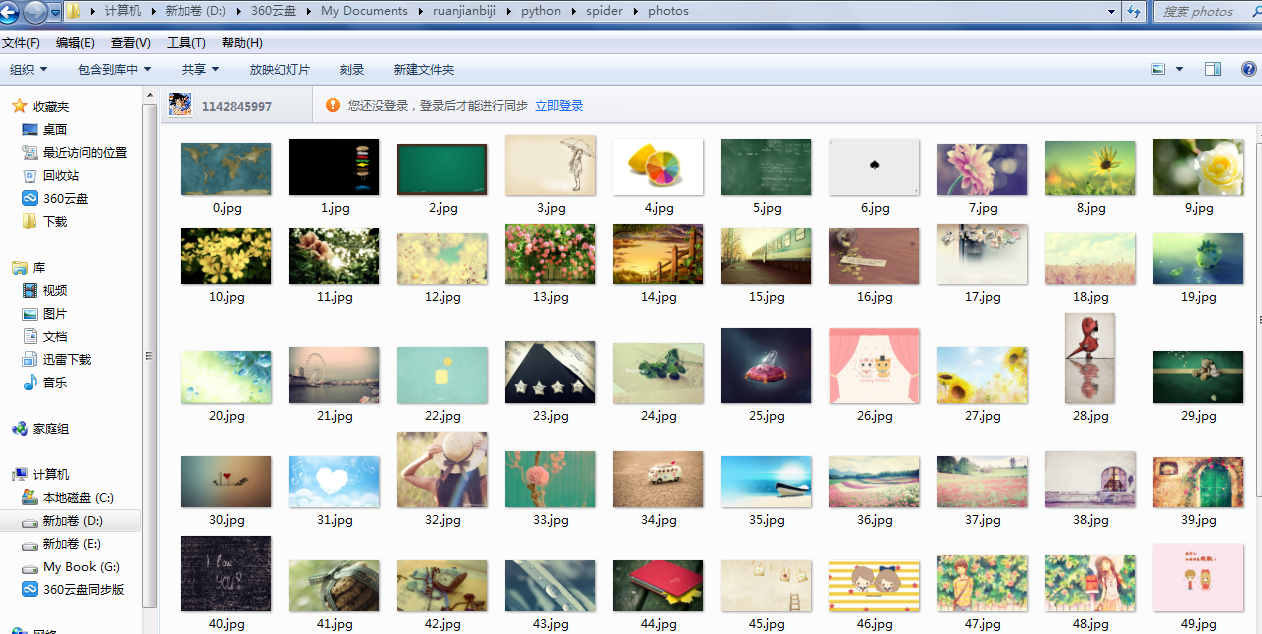
fetch_pictures("http://tieba.baidu.com/p/2460150866")爬取的图片会存放在photos文件夹中,截图如下:
好的,那下面就来爬取一组明星的图片吧,比如刘诗诗,网址如下:http://tieba.baidu.com/p/2854146750 ,如果仍然直接把代码中的网址和文件夹名改一下,会发现并没有下载成功。所以,编程还是得老老实实看代码啊,光想着直接换个网址实在太偷懒(当然,想法可以有,这样才可以写出更智能、更进步的程序嘛)。
代码在抓取网页之后,利用正则表达式找到了图片的网址(URL),即关键在代码的这一行
r = re.compile('<img pic_type="0" class="BDE_Image" src="(.*?)"')上面那两个例子之所以会成功,是因为网页源代码中(可以用谷歌浏览器查看)图片的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1729
1729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









