







导读
MySql是我们常用的数据库,javaEE常用几款(Oracle,PostgreSQL,DB2或IBM),SQLite是用于嵌入式设备里的小型数据库,例如Android或IOS,而掌握SQL语句,就相当于掌握了所有的常见关系化数据库,需要同学们重点掌握以及经常复习
MySQL数据库服务器、数据库和表的关系
- 一般一个项目建一个数据库,数据库中又有一张张的table,table中的一条数据库语句,相当于java中的实体bean类
- 一个java类 对应数据库中一张数据表,一个java对象 对应数据表中一条数据记录
SQL语言
Structured Query Language(SQL语言),结构化查询语言
非过程性语言为加强SQL的语言能力,各厂商增强了过程性语言的特征
- 如Oracle的PL/SQL 过程性处理能力
- SQL Server、Sybase的T-SQL
SQL是用来存取关系数据库的语言,具有查询、操纵、定义和控制关系型数据库的四方面功能
SQL分类
DDL (数据定义语言)
- 数据定义语言 - Data Definition Language
- 用来定义数据库的对象,如数据表、视图、索引等
- 即操作数据库或表结构的
- 所有数据库相关操作语句,数据库表结构操作语句都属于DDL
DML (数据操纵语言)
- 数据处理语言 - Data Manipulation Language
- 在数据库表中更新,增加和删除记录
- 如 update, insert, delete
DCL (数据控制语言)
- 数据控制语言 – Data Control Language
- 指用于设置用户权限和控制事务语句
- 如grant,revoke,if…else,while,begin transaction
DQL (数据查询语言)
- 数据查询语言 – Data Query Language
- select
SQL语句(重点)
掌握SQL语句,相当于掌握了所有的常见关系化数据库,需要重点掌握以及经常复习
数据库操作建议先在.txt文件,写好再把光标移动语句最后,shift+home复制整句过去
编写sql语句没有大小写之分,注意不要拼错单词
MySQL5中文参考手册 -> 部分不知道的字段可以通过这个文档查询
数据库操作:
一 . 创建数据库
- 语法 : create database 数据库名称; (创建数据库采用数据库服务器默认字符集)
- 复杂写法 : create database 数据库名称 character set 字符集 collate 比较规则;
练习:
1. 创建一个名称为mydb1的数据库。 create database mydb1;
2. 创建一个使用utf8字符集的mydb2数据库。 create database mydb2 character set utf8;
3. 创建一个使用utf8字符集,并带校对规则的mydb3数据库。create database mydb3 character set utf8 collate utf8_bin;
==**补充: 每次创建一个数据库在 数据存放目录中生成一个文件夹 , 每个文件夹中存在 db.opt 存放默认字符集和校对规则
datadir=”C:/Documents and Settings/All Users/Application Data/MySQL/MySQL Server 5.5/Data/”**==
二 . 查询数据库
- 语法 : show databases; —– 查看所有数据库,没有数据库则返回没数据null
- 语法 : show create database 数据库名; —— 查看数据编码集
练习:
1. 查看当前数据库服务器中的所有数据库 show databases;
2. 查看前面创建的mydb2数据库的定义信息 show create database mydb2;
三 . 删除数据库
- 语法 : drop database 数据库名称;
练习:
1. 删除前面创建的mydb1数据库 drop database mydb1;
四 . 修改数据库
- 语法 : alter database 数据库名称 character set 字符集 collate 比较规则;
练习:
1. 修改mydb2字符集为gbk; alter database mydb2 character set gbk;
==补充:==
1. 切换数据库 use db_name; -> 当有多个数据库的情况,需要use db_name; 先切换到要操作的数据库
2. 查看当前正在使用数据库: select database();
数据表操作:
一 . 创建数据表
- 语法 : create table 表名(列名 类型(长度),列名 类型(长度)… );
格式 :
create table 表名(
列名称1 列名称1值类型,
列名称2 列名称2值类型,
列名称3 列名称3值类型,
列名称4 列名称4值类型
);
列名称1值类型 是 mysql 中运行的值的类型
注意最后一句没有 ,
- MySQL 常用数据类型:
| 类型 | 说明 |
|---|---|
| 字符串型—String | Varchar(可变值)、char(固定值) ->若两者最大值都为30,varchar如果数据只有20,最后就为20;char如果数据只有20,会自动补齐,char比varchar效率高点 |
| 大数据类型—字节流,字符流 | BLOB、TEXT |
| 数值型–数值类型 (bit,byte,short,int,long,float,double) | TINYINT 、SMALLINT、INT、BIGINT、FLOAT、DOUBLE |
| 逻辑型 | BIT 存放以为数值 0 或者 1 |
| 日期型 | DATE(只有日期)、TIME(只有时间)、DATETIME(日期和时间)、TIMESTAMP时间可以自动跟新(当前时间) |
练习 :
创建一个员工表employee ---- 查看表结构: desc 表名;
字段 属性
id 整形 int
name 字符型 varchar(30)
gender 字符型 varchar(10)
birthday 日期型 date
entry_date 日期型 date
job 字符型 varchar(50)
salary 小数型 double
resume 大文本型 varchar(255)
create table employee(
id int,
name varchar(30),
gender varchar(10),
birthday date,
entry_date date,
job varchar(50),
salary double,
resume varchar(255)
);
==补充:==
1. 创建表时没有指定字符集,将采用数据库默认字符集
2. 创建表之前 必须使用use db_name 语法指定操作数据库
3. 查看表结构: desc 表名
4. 创建数据表时,只有字符串类型必须写长度,而其他类型都有默认长度
5. 一个java类 对应数据库中一张数据表,一个java对象 对应数据表中一条数据记录
二 . 定义单表字段的约束
约束用来保证数据有效性和完整性
- 有效性: 类似日常生活防止姓名一样,给个身份证号以保证身份的唯一性
- 完整性: 类似生活中一个人不告诉我们姓名就不让他存数据,保证数据的完整性
定义主键约束(唯一,并且非空):
primay key -> 信息记录某个字段可以唯一区分其他信息记录,这个字段就可以是主键
如果列的类型为数值型(int bigint),并且声明为主键,那么通常会加上auto_increment,表示自动增长
唯一约束(不能重复,可以为空):
unique -> 一张表中可以有很多个唯一约束,只能有一个(两个)作为主键约束
非空约束(可以重复,不能为空):
not null
练习:
create table employee2(
id int primary key auto_increment,
name varchar(30) not null,
gender varchar(10) not null,
birthday date,
entry_date date,
job varchar(50),
salary double not null,
resume varchar(255) unique
);
三 . 修改数据表结构
- 增加列 语法: alter table 表名 add 列名 类型(长度) 约束;
- 修改现有列类型、长度和约束 语法:alter table 表名 modify 列名 类型(长度) 约束;
- 修改现有列名称 语法:alter table 表名 change 旧列名 新列名 类型(长度) 约束;
- 删除现有列 语法:alter table 表名 drop 列名;
- 修改表名 rename table 旧表名 to 新表名;
练习:
1. 修改表的字符集:—-alter table student character set utf8;
2. 在上面员工表的基本上增加一个image列: —-alter table employee add image varchar(100);
3. 修改job列,使其长度为60。 —-alter table employee modify job varchar(60) not null;
4. 删除gender列。 —-alter table employee drop gender ;
5. 表名改为user。 —-rename table employee to user;
6. 修改表的字符集为utf8 —- alter table user character set utf8;
7. 列名name修改为username —– alter table user change name username varchar(20) unique not null;
==补充:==
1. 查看当前数据库内所有表:show tables;
2. 查看当前数据表字符集 : show create table user;
3. 查看表结构 : desc 表名;
四 . 删除数据表
- 语法:drop table 表名;
练习:
1. 删除employee2表:drop table employee2;
数据表中数据记录的增删改查操作:
一 . 插入数据:
语法一(全写) :insert into 表名(列名,列名,列名…) values(值,值,值…);
- 如:insert into employee2(id,name,gender,birthday,entry_date,job,salary,resume) values(1,’zs’,’female’,’1995-09-09’,’2015-12-09’,’developer’,15000,’a good developer’);
语法二(只写部分,字段值属性为空的可以不写,不为空的值要写)
- 如:insert into employee2 (id,name,gender,salary,resume) values(null,’haojie’,’male’,17000,’a hansome boy’);
语法三(不写字段名称,只写字段值,但是所有的字段值都要写)
- 如:insert into employee2 values(null,’linpeng’,’male’,’1994-09-09’,’2015-12-22’,’programmer’,16000,’a lady killer’);
==补充:==
1. 插入值 类型必须和 列类型匹配
2. 值长度不能超过 列定义长度
3. 值的顺序和 列顺序对应
4. 字符串和日期型值 必须写 单引号
5. 插入空值 可以写 null
6. 插入记录后,使用select * from 表名; 查看表信息
可能出现的bug:
插入一条中文记录
insert into employee(id,name,job,salary) values(4,'小明','清洁员',1500);
出错了:
ERROR 1366 (HY000): Incorrect string value: '\xC3\xF7' for column 'name' at row 1 ;
错误原因:mysql client 采用默认字符集编码 gbk
查看系统所有字符集 : show variables like 'character%';
解决:修改客户端字符集为gbk
MYSQL中共有6个地方字符集 :client connetion result 和客户端相关 、database server system 和服务器端相关
第一种:
当前窗口临时修改 set names gbk ;
* 只对当前窗口有效,关闭后就会失效
第二种:
配置mysql/my.ini 文件
[mysql] 客户端配置
[mysqld] 服务器端配置
修改客户端字符集 [mysql] 后字符集 default-character-set=gbk
使用mysql -u root -p 密码连入数据库后,如果进行数据库操作,直接操作,如果要进行数据表结构和数据记录操作,必须先切换到操作的数据库 use db;
二 . 数据记录更改操作:
- 语法: update 表名 set 列名=值,列名=值…. where条件语句;
- 如果没有where条件语句,默认修改所有行数据
练习:
1. 将所有员工薪水修改为5000元。 —– update employee set salary = 5000;
2. 将姓名为’zhangsan’的员工薪水修改为3000元。 ——- update employee set salary = 3000 where name=’zhangsan’;
3. 将所有员工薪水修改为5000元。 ——- update employee set salary=4000, job=’ccc’ where name=’lisi’;
4. 将wangwu的薪水在原有基础上增加1000元。 ———— update employee set salary = salary+1000 where name =’wangwu’;
三 . 数据记录的删除操作:
语法:delete from 表名 where条件语句;
- 如果没有where语句,将删除表中 所有记录
语法: truncate table 表名;
练习:
1. 删除表中名称为’zs’的记录。—-delete from employee2 where name=’zs’;
2. 删除表中所有记录(DML语句)。—-delete from employee2;
3. 使用truncate删除表中记录。(先将表摧毁,然后再创建, 属于DDL语句)—-truncate table employee2;
==补充:==
truncate 与 delete区别
1. truncate 删除数据,过程先将整个表删除,再重新创建
2. delete 删除数据,逐行删除记录
3. truncate 属于DDL,delete属于DML——-事务管理只能对DML有效,被事务管理SQL语句可以回滚到SQL执行前状态
4. truncate 效率要好于 delete
四 . 数据表记录的查询(DQL语句):
- 语法一 : select [distinct] * | 列名,列名… from 表名;
- select * from 表名; 查询该表中所有列信息
- select 列名,列名… from 表名; 查询表中指定列的信息
- distinct 用于去重
练习:
create table exam(
id int primary key auto_increment,
name varchar(20) not null,
chinese double,
math double,
english double
);
insert into exam values(null,'关羽',85,76,70);
insert into exam values(null,'张飞',70,75,70);
insert into exam values(null,'赵云',90,65,95);
查询表中所有学生的信息。 --------- select * from exam;
查询表中所有学生的姓名和对应的英语成绩。 ----- select name,english from exam;
过滤表中重复数据 (查询英语成绩,排除完全相同重复数据) ---- select distinct english from exam;
- 语法二 : select 列名 as 别名 from 表名;
练习:
1. 在所有学生分数上加10分特长分。 —- select name,chinese+10,math+10,english+10 from exam;
2. 统计每个学生的总分。——- select name,chinese+math+english from exam;
3. 使用别名表示学生分数。—– select name,chinese+math+english as 总分 from exam;
4. 在对列起别名时,as可以省略 select name,chinese+math+english as 总分 from exam; —— select name,chinese+math+english 总分 from exam;
5. select name,math from exam; 查询name和math两列的值
6. select name math from exam; 查询name列值,起别名math
- 语法三 : select 列名 from 表名 where条件语句
练习:
1. 查询姓名为关羽的学生成绩 ——-select * from exam where name=’关羽’;
2. 查询英语成绩大于90分的同学 —– select * from exam where english > 90;
3. 查询总分大于200分的所有同学 —– select * from exam where chinese+math+english > 200;
- 语法四 : select * from 表名 order by 列名 asc|desc; —- asc升序 desc降序
练习:
1. 对数学成绩排序后输出。———– select * from exam order by math; 默认asc升序
2. 对总分排序按从高到低(降序)的顺序输出 ———— select * from exam order by math+chinese+english desc;
3. 对学生成绩按照英语进行降序排序,英语相同学员按照数学降序 ————- select * from exam order by english desc,math desc;
- 语法五:select 分组函数 from exam group by 列名; 按照某列进行分组统计 分组操作,就是具有相同数据记录分到一组中,便于统计
练习:
create table orders(
id int,
product varchar(20),
price float
);
insert into orders(id,product,price) values(1,'电视',900);
insert into orders(id,product,price) values(2,'洗衣机',100);
insert into orders(id,product,price) values(3,'洗衣粉',90);
insert into orders(id,product,price) values(4,'桔子',9);
insert into orders(id,product,price) values(5,'洗衣粉',90);
对订单表中商品归类后,显示每一类商品的总价 ---- 需要按照商品名称进行分组
select product,sum(price) from orders group by product;
在group by 语句后面 添加having 条件语句 ---- 对分组查询结果进行过滤
查询购买了几类商品,并且每类总价大于100的商品
select product,sum(price) from orders group by product having sum(price) > 100;
运算符:
相等= 不等 <>
between …and… 在两者之间取值 between 70 and 80 等价于 >=70 <=80 —– 注意前面那个数要比后面那个数要小
in(值,值,值) 在指定值中任取一个 in(70,80,90) 值可以是70、80或者90
**like ‘模糊查询pattern’ 进行模糊查询 ,表达式有两个占位符 % 任意字符串 _ 任意单个字符 例如: name like ‘张%’ 所有姓张学员
name like ‘张_’ 所有姓张名字为两个字学员**is null 判断该列值为空
and 逻辑与 or 逻辑或 not 逻辑非
练习:
查询英语分数在 90-100之间的同学。 -------- select * from exam where english>=90 and english <= 100; select * from exam where english between 90 and 100;
查询数学分数为65,75,85的同学。 ---- select * from exam where math in(65,75,85);
查询所有姓赵的学生成绩。---- select * from exam where name like '赵%';
查询英语分>80,语文分>80的同学。 ---- select * from exam where english > 80 and chinese > 80;
insert into exam values(null,'刘备',null,55,38);
查询语文没有成绩学员 select * from exam where chinese is null;
查询语文有成绩学员 select * from exam where chinese is not null;
聚集函数 指SQL语句中内置函数 ———- 分组函数(用于统计):
- count 统计查询结果记录条数 select count(*)|count(列名) from 表名;
练习:
1. 统计一个班级共有多少学生?———— select count( * ) from exam;
2. 统计英语成绩大于90的学生有多少个? ——- select count( * ) from exam where english > 90;
3. 统计总分大于220的人数有多少? ——–select count( * ) from exam where chinese+math+english > 220;
- sum 统计某一列数据的和 select sum(列名) from 表名;
练习:
1. 统计一个班级数学总成绩? —– select sum(math) from exam;
2. 统计一个班级语文、英语、数学各科的总成绩 —- select sum(chinese),sum(math),sum(english) from exam;
3. 统计一个班级语文、英语、数学的成绩总和 select sum(chinese+math+english) from exam; select sum(chinese)+sum(math)+sum(english) from exam;
4. **刘备语文null ,null进行所有运算 结果都是null
select sum(chinese)+sum(math)+sum(english) from exam; 含有刘备英语和数学成绩
select sum(chinese+math+english) from exam; 不含刘备英语和数学成绩**
5. **使用ifnull函数处理 null情况
select sum(ifnull(chinese,0)+ifnull(math,0)+ifnull(english,0)) from exam; 含有刘备英语和数学成绩**
6. 统计一个班级语文成绩平均分 —— select sum(chinese)/count( * ) from exam;
- avg 统计某一列平均值 select avg(列名) from 表名;
练习:
1. 求一个班级数学平均分? —- select avg(math) from exam;
2. 求一个班级总分平均分?—- select avg(ifnull(chinese,0)+ifnull(math,0)+ifnull(english,0)) from exam;
- max 统计一列最大值 min 统计一列最小值
练习:
1. 求班级最高分和最低分(数值范围在统计中特别有用)select max(chinese+math+english) ,min(ifnull(chinese,0)+ifnull(math,0)+ifnull(english,0)) from exam;
==补充:==
where 和 having 条件语句的区别?
1. where 是在分组前进行条件过滤,having 是在分组后进行条件过滤 2. 使用where地方都可以用 having替换,但是having可以使用分组函数,而where后不可以用分组函数
小结select语句:
**S-F-W-G-H-O 组合 select … from … where … group by… having… order by … ;
顺序不能改变**解析顺序 : from - where - group by - having - select - order by
多表设计:
多表设计(外键约束):
create table emp (
id int primary key auto_increment,
name varchar(20),
job varchar(20),
salary double
);
insert into emp values(null,'小丽','人力资源',4500);
insert into emp values(null,'小张','Java工程师',5000);
insert into emp values(null,'老李','财务经理',8000);
insert into emp values(null,'小刘','项目经理',10000);
create table dept(
id int primary key auto_increment,
name varchar(20)
);
insert into dept values(null,'人力资源部');
insert into dept values(null,'财务部');
insert into dept values(null,'技术研发部');
让员工表和部门表发生关系,知道员工属于哪个部门 ,在员工表添加部门id字段
alter table emp add dept_id int ;
update emp set dept_id = 1 where name = '小丽';
update emp set dept_id = 2 where name = '老李';
update emp set dept_id = 3 where name = '小刘';
update emp set dept_id = 3 where name = '小张';
假设公司因为财政问题,解散技术研发部 delete from dept where name ='技术研发部'; ----- 小张和小刘 失去了组织
emp表 中dept_id字段 引用 dept表 id 字段 ------- 添加外键约束 (保证数据有效和完整性)
将emp表中dept_id 设置为外键约束 alter table emp add foreign key(dept_id) references dept(id) ;
无法删除技术研发部,因为小刘和小张信息 依赖技术研发部 记录 !!!!!
多表设计原则(了解):
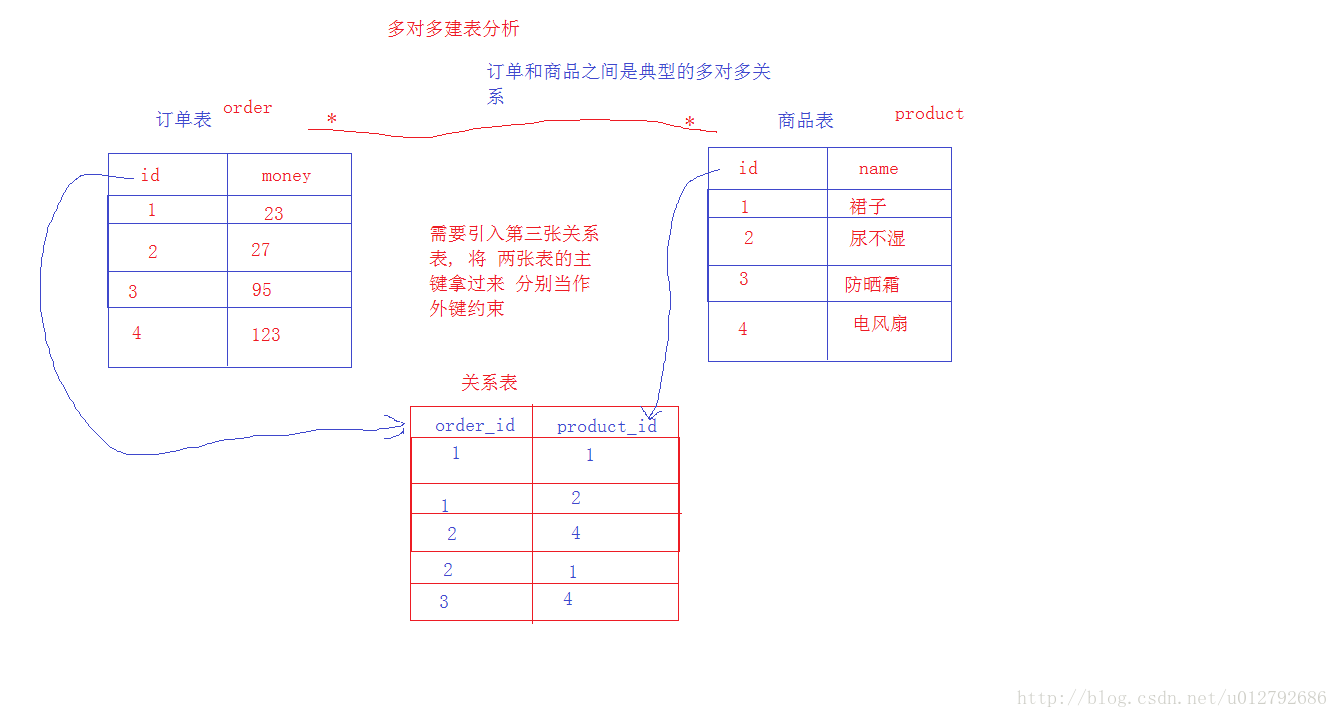
- 多对多关系 : 雇员和项目关系
- 一个雇员可以参与多个项目 , 一个项目可以由多个雇员参与
- 建表原则:必须创建第三张关系表,在关系表中引用两个实体主键 作为外键
- 关系表中每条记录,代表一个雇员参与了一个项目
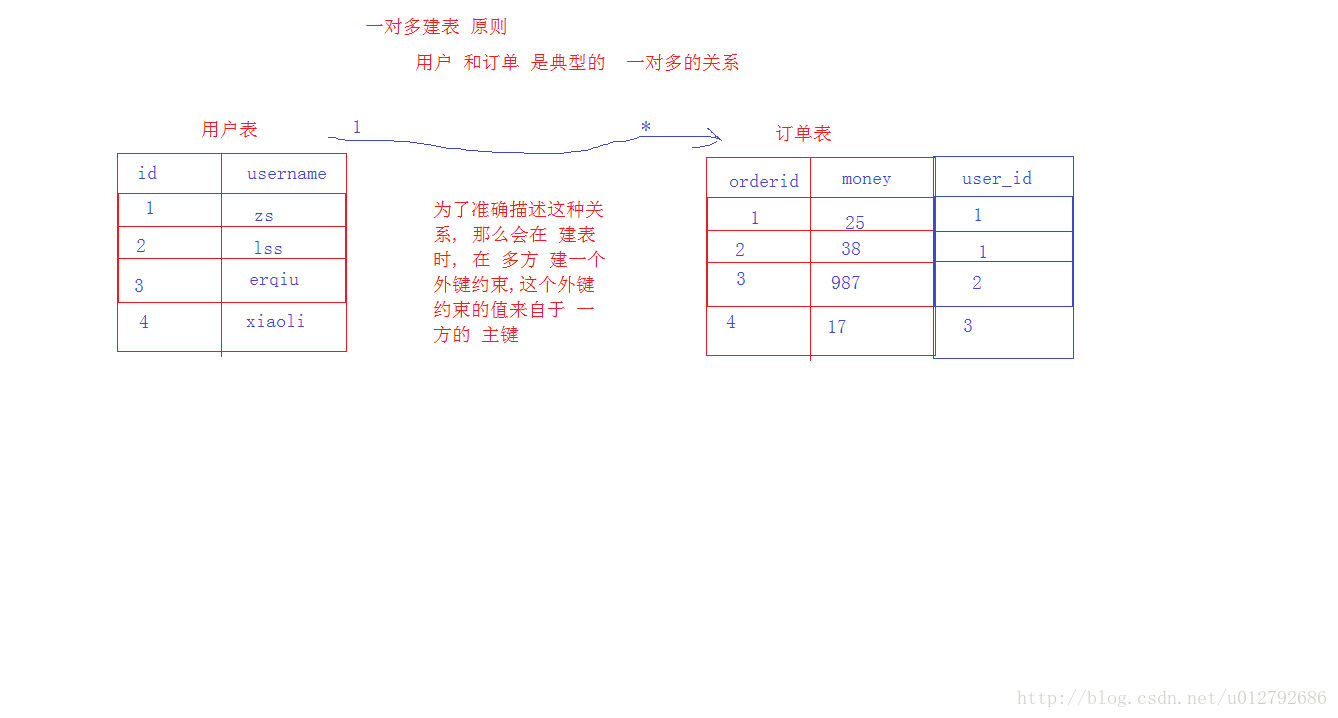
- 一对多关系: 用户和博客关系
- 一个用户可以发表多篇博客 , 一个博客只能由一个作者
- 建表原则:不需要创建第三方关系表,只需要在多方添加 一方主键作为 外键
- 一对一关系 : 这种关系很少见到 负责人和工作室
- 一个负责人 管理一个工作室 , 一个工作室 只有一个负责人
- 建表规则:在任一方添加对方主键 作为外键
笛卡尔积的学习:
多表查询——笛卡尔积
将A表中每条记录 与 B表中每条记录进行 匹配 获得笛卡尔积
select * from emp;
select * from dept;
select * from emp,dept; 显示结果就是笛卡尔积
笛卡尔积结果 就是 两个表记录乘积 例如A 表3条 B表4条 ---- 笛卡尔积 12条
笛卡尔积结果是无效的,必须从笛卡尔积中选取有效的数据结果 !!!
多表查询 连接查询 内连接查询
从A表中选择一条记录,去B表中找对应记录 ----- 内连接
必须A表和B表存在对应记录才会显示
create table A(A_ID int primary key auto_increment,A_NAME varchar(20) not null);
insert into A values(1,'Apple');
insert into A values(2,'Orange');
insert into A values(3,'Peach');
create table B(A_ID int primary key auto_increment,B_PRICE double);
insert into B values(1,2.30);
insert into B values(2,3.50);
insert into B values(4,null);
使用内连接 select * from a,b where a.a_id = b.a_id; 从笛卡尔积中筛选出有效的数据
* 内连接查询结果条数 一定小于 两个表记录较多哪个表 ----- 例如 A表3条 B表5条 ---- 内连接结果条数 <= 5
select * from emp,dept where emp.dept_id = dept.id ; 将emp 表和dept 表进行内连接
在内连接查询时 添加条件,
查询人力资源部有哪些 员工 ??
select * from emp,dept where emp.dept_id = dept.id and dept.name ='人力资源部';
查询工资大于7000员工来自哪个部门?
select * from emp,dept where emp.dept_id = dept.id and emp.salary > 7000;
select * from emp,dept where emp.dept_id = dept.id ; 写法一
select * from emp inner join dept on emp.dept_id = dept.id ; 写法二
扩展内容
MySQL 数据库的备份和恢复
- 备份命令 mysql/bin/mysqldump 将数据库SQL语句导出
- 语法:mysqldump -u 用户名 -p 数据库名 > 磁盘SQL文件路径
例: 备份day12数据库 — c:\day10.sql
cmd > mysqldump -u root -p day10 > c:\day10.sql 回车输入密码**
- 恢复命令 mysql/bin/mysql 将sql文件导入到数据库
- 语法: mysql -u 用户名 -p 数据库名 < 磁盘SQL文件路径
注意:导入SQL 必须手动创建数据库,SQL不会创建数据库
例: 将c:\day10.sql 导入 day10数据库
cmd > mysql -u root -p day10 < c:\day10.sql 回车密码
==补充知识==: 恢复SQL也可以在数据库内部执行 source c:\day10.sql














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









