







http://dockone.io/article/2288
Kubernetes基础组件概述
【编者的话】最近总有同学问Kubernetes中的各个组件的相关问题,其实这些概念内容在官方文档中都有,奈何我们有些同学可能英文不好,又或者懒得去看,又或者没有找到,今天有时间就专门写了这篇博客。
【深圳站|3天烧脑式Kubernetes训练营】培训内容包括:Kubernetes概述、架构、日志和监控,部署、自动驾驶、服务发现、网络方案等核心机制分析,进阶篇——Kubernetes调度工作原理、资源管理及源码分析等。
本文主要介绍Kubernetes的基础组件,先介绍Master节点上的控制管理组件,再介绍Node节点上的计算组件,最后是附加组件,后边会找时间再写一篇介绍Kubernetes中的各种资源及使用。
kube-proxy本身实际上并不负责请求转发和负载均衡,而时从kube-apiserver获取Service和POD的状态更新,生成对应的DNAT规则到本地的iptabels,最终的转发和负载均衡动作有iptabels实施,所以kube-proxy组件即使出现问题,已经更新到iptabels的转发规则依然能够生效。
有了上边介绍的Master节点组件和Node节点组件后,基础的Kubernetes环境算是已经构建好了:
原生的docker网络结构:docker在启动的时候会创建一个网桥docker0(172.17.0.0),容器启动的时候会创建一对Veth pair,这个Veth pair成对出现用于链接容器与docker0网桥(可以将其理解成一根网线的两个插头,一头插在容器内改名为eth0,另一头插在宿主机的docker0网桥上),这样同一台宿主机上的容器就可以互相访问了,此时的路由表记录:
但是对于不同的宿主机A和宿主机B来说,它们的docker网络一模一样,IP也是一样,网络与网络之间也不通。
Flannel来了之后,在每个宿主机上增加了个P2P的虚拟网卡flannel0(172.17.0.0),一头对接docker0网桥,一头由Flanneld服务监听。Etcd管理着整个Flannel网络的子网分配,宿主机A和宿主机B分别用分到的子网
模拟下Flannel网络下宿主机A上的docker容器(172.17.1.10)发送数据到宿主机B上的docker容器(172.17.2.15)的过程:
Flannel的Github上有张比较详细的原理图:
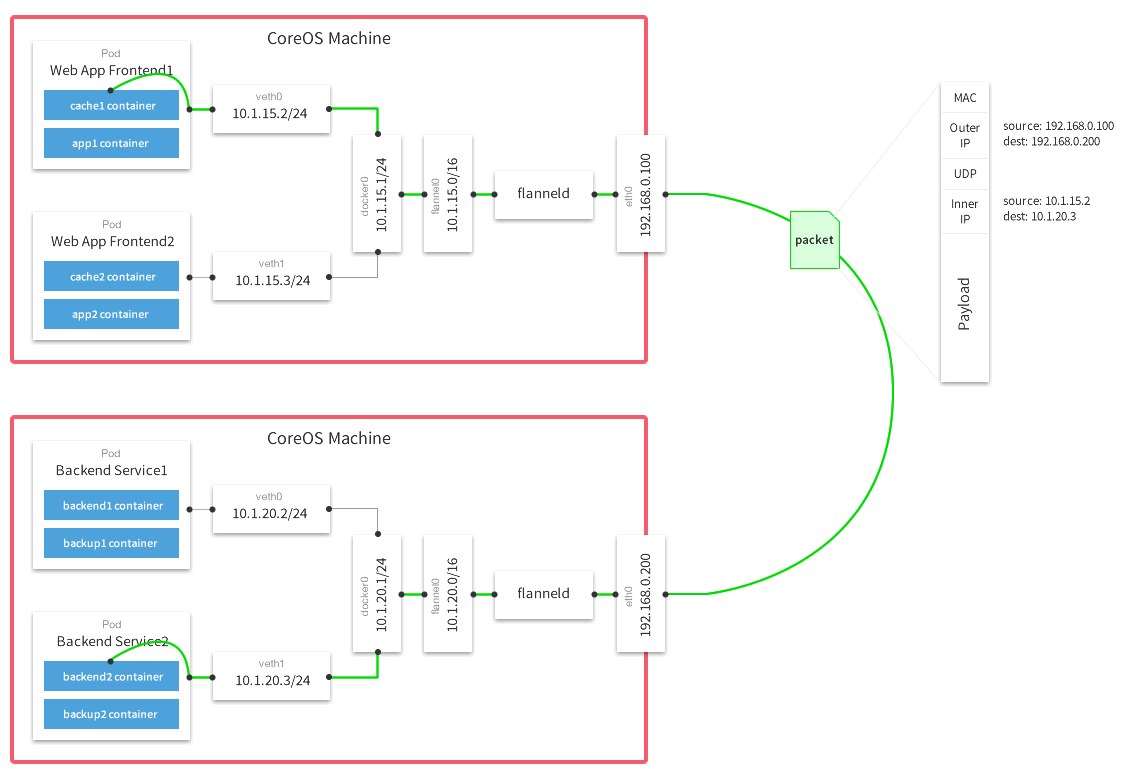
图中的Flanneld运行在每个宿主机上,负责数据的发送、监听、封包、解包等任务。
强调下,Flannel的backend有UDP和VXLAN、GRE等实现,默认使用UDP,性能大约只有本地物理网络的一半,VXLAN推荐使用,性能损耗很小,不过需要3.9+的内核支持。
Clico网络模型的特点:
Calico 的核心组件:
Felix:Calico agent,跑在每台需要运行workload的节点上,主要负责配置路由及 ACLs等信息来确保endpoint的连通状态;
etcd:分布式键值存储,主要负责网络元数据一致性,确保Calico网络状态的准确性;
BGP Client(BIRD):主要负责把Felix写入kernel的路由信息分发到当前Calico网络,确保workload间的通信的有效性;
BGP Route Reflector(BIRD):大规模部署时使用,摒弃所有节点互联的mesh模式,通过一个或者多个BGP Route Reflector来完成集中式的路由分发;
默认的kube-dns的service_ip:10.96.0.10,默认的域名后缀为:cluster.local,如果是kubeadm部署的Kubernetes集群,kubelet的配置参数文件是:
DNS解析的A记录规则为:
POD实例创建后,其中的Container内的resolver.conf的配置如下:
因为添加了search domain,在POD的容器内访问其他Service时可以用缩略域名访问,如访问kube-dns服务:kube-dns(同namespace内访问),kube-dns.kube-system(跨namespace访问)。
可以通过官方提供的YAML模板创建:
【深圳站|3天烧脑式Kubernetes训练营】培训内容包括:Kubernetes概述、架构、日志和监控,部署、自动驾驶、服务发现、网络方案等核心机制分析,进阶篇——Kubernetes调度工作原理、资源管理及源码分析等。
本文主要介绍Kubernetes的基础组件,先介绍Master节点上的控制管理组件,再介绍Node节点上的计算组件,最后是附加组件,后边会找时间再写一篇介绍Kubernetes中的各种资源及使用。
1 Master节点组件
Master节点组件是指运行在Kubernetes集群中的Master节点上,提供整个集群的管理控制功能的组件,例如调度组件(kube-scheduler),接口组件(kube-apiserver)等1.1 kube-apiserver
kube-apiserver主要负责暴露Kubernetes API,不管是kubectl还是HTTP调用来操作Kubernetes集群各种资源,都是通过kube-apiserver提供的接口进行操作的。详细介绍、文档、配置参数: API-Server配置。
1.2 kube-controller-manager
管理控制器负责整个Kubernetes的管理工作,保证集群中各种资源的状态处于期望状态,当监控到集群中某个资源状态不正常时,管理控制器会触发对应的调度操作,主要由以下几部分组成:- 节点控制器(Node Controller)
- 副本控制器(Replication Controller)
- 端点控制器(Endpoints Controller)
- 命名空间控制器(Namespace Controller)
- 身份认证控制器(Serviceaccounts Controller)
详细介绍、文档、配置参数: Controller-Manager配置。
1.3 cloud-controller-manager
云管理控制器是Kubernetes 1.6新加入的组件(组件抽象了一层IaaS平台的接口,具体的实现由各云厂商负责提供),主要负责与基础计算云平台(IaaS)的交互,目前还处于测试开发阶段,我们也还没有使用过该组件。该组件的具体实现包括:- 节点控制器(Node Controller)
- 路由控制器(Route Controller)
- 负载均衡服务控制器(Service Controller)
- 数据卷控制器(Volume Controller)
1.4 kube-scheduler
调度器负责Kubernetes集群的具体调度工作,接收来自于管理控制器(kube-controller-manager)触发的调度操作请求,然后根据请求规格、调度约束、整体资源情况等因素进行调度计算,最后将任务发送到目标节点的kubelet组件执行。详细介绍、文档、配置参数: Scheduler配置。
1.5 etcd
etcd是一款用于共享配置和服务发现的高效KV存储系统,具有分布式、强一致性等特点。在Kubernetes环境中主要用于存储所有需要持久化的数据。2 Node节点组件
Node节点组件是指运行在Node节点上,负责具体POD运行时环境的组件。2.1 kubelet
kubelet是Node节点上最重要的核心组件,负责Kubernetes集群具体的计算任务,具体功能包括:- 监听Scheduler组件的任务分配
- 挂载POD所需Volume
- 下载POD所需Secrets
- 通过与docker daemon的交互运行docker容器
- 定期执行容器健康检查
- 监控、报告POD状态到kube-controller-manager组件
- 监控、报告Node状态到kube-controller-manager组件
2.2 kube-proxy
kube-proxy主要负责Service Endpoint到POD实例的请求转发及负载均衡的规则管理。kube-proxy本身实际上并不负责请求转发和负载均衡,而时从kube-apiserver获取Service和POD的状态更新,生成对应的DNAT规则到本地的iptabels,最终的转发和负载均衡动作有iptabels实施,所以kube-proxy组件即使出现问题,已经更新到iptabels的转发规则依然能够生效。
详细介绍、文档、配置参数: Kube-Proxy配置。
3 附加组件
BTW:所谓的附加组件并不是说这类组件在kunernetes环境中可有可无,只是为了区别于底层的基础计算组件。有了上边介绍的Master节点组件和Node节点组件后,基础的Kubernetes环境算是已经构建好了:
kubectl调用apiserver发送创建pod的请求,scheduler收到调度任务发送到符合要求的node节点,node节点上的kubelet与docker daemon通讯创建docker容器。但是离真正可用的Kubernetes集群还有一定距离,例如Container IP管理,内部DNS解析,简单的管理控制台等。
3.1 Flannel
Flannel是由ConreOS主导设计的用于容器技术的覆盖网络(Overlay Network),在Flannel管理的容器网络中,每一个宿主机都会拥有一个独立子网,用于分配给其上的容器使用。通信方式是基于隧道协议的UDP和VXLAN等方式封包、解包及传输。原生的docker网络结构:docker在启动的时候会创建一个网桥docker0(172.17.0.0),容器启动的时候会创建一对Veth pair,这个Veth pair成对出现用于链接容器与docker0网桥(可以将其理解成一根网线的两个插头,一头插在容器内改名为eth0,另一头插在宿主机的docker0网桥上),这样同一台宿主机上的容器就可以互相访问了,此时的路由表记录:
但是对于不同的宿主机A和宿主机B来说,它们的docker网络一模一样,IP也是一样,网络与网络之间也不通。
Flannel来了之后,在每个宿主机上增加了个P2P的虚拟网卡flannel0(172.17.0.0),一头对接docker0网桥,一头由Flanneld服务监听。Etcd管理着整个Flannel网络的子网分配,宿主机A和宿主机B分别用分到的子网
172.17.1.0和
172.17.2.0创建docker0网桥,然后又悄悄地修改了一下docker daemon的启动参数
--bip=172.17.1.1/24,同时添加路由表记录:
模拟下Flannel网络下宿主机A上的docker容器(172.17.1.10)发送数据到宿主机B上的docker容器(172.17.2.15)的过程:
- 根据源容器和目的容器的IP匹配路由规则,同时匹配两个IP的路由规则是
172.17.0.0/16,如果是同一个宿主机上的容器访问,匹配的是172.17.1.0或者172.17.2.0 - 数据从docker0网桥出来以后投递到flannel0网卡
- 监听flannel0网卡的Flanneld服务收到数据后封装成数据包发送到宿主机B
- 宿主机B上的Flanneld服务接收到数据包后解包还原成原始数据
- Flanneld服务发送数据到flannel0网卡,根据目的容器地址匹配到路由规则
172.17.2.0/24(docker0) - 投递数据到docker0网桥,进而进入到目标容器172.17.2.15。
Flannel的Github上有张比较详细的原理图:
图中的Flanneld运行在每个宿主机上,负责数据的发送、监听、封包、解包等任务。
强调下,Flannel的backend有UDP和VXLAN、GRE等实现,默认使用UDP,性能大约只有本地物理网络的一半,VXLAN推荐使用,性能损耗很小,不过需要3.9+的内核支持。
详细介绍、文档、源码: Flannel Github。
3.2 Calico
Calico是纯三层的SDN实现,它基于BPG协议和Linux的路由转发机制,不依赖特殊硬件,没有使用NAT或Tunnel等技术。能够方便的部署在物理服务器,虚拟机(如OpenStack)或者容器环境下,可以无缝集成像OpenStack这种IaaS云架构,能够提供可控的VM、容器、裸机之间的IP通信,同时它自带的基于Iptables的ACL管理组件非常灵活,能够满足比较复杂的安全隔离需求。Clico网络模型的特点:
- 在Calico中的数据包并不需要进行封包和解封。
- Calico中的数据包,只要被policy允许,就可以在不同租户中的workloads间传递或直接接入互联网或从互联网中进到Calico网络中,并不需要像overlay方案中,数据包必须经过一些特定的节点去修改某些属性。
- 因为是直接基于三层网络进行数据传输,TroubleShooting会更加容易,同时用户也可以直接用一般的工具进行操作与管理,比如ping、Whireshark等,无需考虑解包之类的事情。
- 网络安全策略使用ACL定义,基于iptables实现,比起overlay方案中的复杂机制更直观和容易操作。
Calico 的核心组件:
Felix:Calico agent,跑在每台需要运行workload的节点上,主要负责配置路由及 ACLs等信息来确保endpoint的连通状态;
etcd:分布式键值存储,主要负责网络元数据一致性,确保Calico网络状态的准确性;
BGP Client(BIRD):主要负责把Felix写入kernel的路由信息分发到当前Calico网络,确保workload间的通信的有效性;
BGP Route Reflector(BIRD):大规模部署时使用,摒弃所有节点互联的mesh模式,通过一个或者多个BGP Route Reflector来完成集中式的路由分发;
详细介绍、文档、源码: Calico Github。
3.3 DNS
kube-dns负责Kubernetes集群内的域名解析,解析服务通过dnsmasq实现。通过官方提供的Deployment和Service模板,可以很方便地部署kube-dns服务,并且可以任意伸缩POD实例来保证其高可用性。默认的kube-dns的service_ip:10.96.0.10,默认的域名后缀为:cluster.local,如果是kubeadm部署的Kubernetes集群,kubelet的配置参数文件是:
/etc/systemd/system/kubelet.service.d/10-kubeadm.conf。
DNS解析的A记录规则为:
my-svc.my-namespace.svc.cluster.local,例如kube-dns的service的A记录为:
kube-dns.kube-system.svc.cluster.local。
POD实例创建后,其中的Container内的resolver.conf的配置如下:
因为添加了search domain,在POD的容器内访问其他Service时可以用缩略域名访问,如访问kube-dns服务:kube-dns(同namespace内访问),kube-dns.kube-system(跨namespace访问)。
详细介绍、文档: Kube-Dns文档。
3.4 Dashboard
Dashboard是官方提供的kubernetes集群的UI界面,提供了一些基础的查看及简单操作,随便用用还行。可以通过官方提供的YAML模板创建:
kubectl create -f https://rawgit.com/kubernetes/dashboard/master/src/deploy/kubernetes-dashboard.yaml。
详细介绍、文档: Kube-Dashboard文档。














 891
891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









