










| Time Limit: 1000MS | Memory Limit: 10000K | |
| Total Submissions: 3756 | Accepted: 1483 |
Description
This problem involves neither Zorn's Lemma nor fix-point semantics, but does involve order.
Given a list of variable constraints of the form x < y, you are to write a program that prints all orderings of the variables that are consistent with the constraints.
For example, given the constraints x < y and x < z there are two orderings of the variables x, y, and z that are consistent with these constraints: x y z and x z y.
Input
All variables are single character, lower-case letters. There will be at least two variables, and no more than 20 variables in a specification. There will be at least one constraint, and no more than 50 constraints in a specification. There will be at least one, and no more than 300 orderings consistent with the contraints in a specification.
Input is terminated by end-of-file.
Output
Output for different constraint specifications is separated by a blank line.
Sample Input
a b f g a b b f v w x y z v y x v z v w v
Sample Output
abfg abgf agbf gabf wxzvy wzxvy xwzvy xzwvy zwxvy zxwvy
Source
题目大意:
第一行给出一些字母(各不相同)
第二行给出一些对约束条件,ai、bi表示ai必须在bi的前面;
输出所有的序列;
典型的拓扑排序:
拓扑排序:
对一个有向无环图(Directed Acyclic Graph简称DAG)G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若边(u,v)∈E(G),则u在线性序列中出现在v之前。通常,这样的线性序列称为满足拓扑次序(Topological Order)的序列,简称拓扑序列。简单的说,由某个集合上的一个偏序得到该集合上的一个全序,这个操作称之为拓扑排序。(摘自百度百科)
例如这张图:
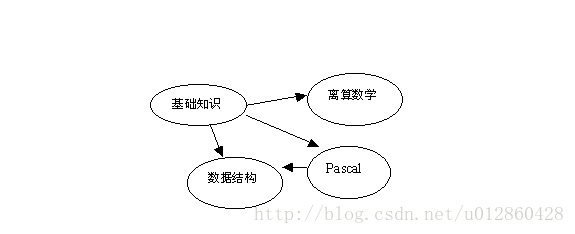
可以看到这是一个有向无环图(有环图无法进行拓扑排序),给他们赋予实际意义就是,例如a->b,表示要先学a才能学b;现在让你安排课程,怎样才能使课程更加合理呢?
我们现根据定义来对这图进行一下拓扑排序如下:
基础知识->离散数学->Pascal->数据结构;
或者是 基础知识->Pascal->离散数学->数据结构;
(拓扑序列并不一定只有一个可以有多个)
进行完拓扑排序后可以发现,按拓扑序列的顺序安排课程比较合理的;
拓扑排序的实现方法:
1、删边法:
找出入度为0的节点,输出这个节点序号,然后删除所有与这个节点相连的边,对应与其连接的节点的度减一;
然后再找一个入度为0 的节点,重复上面的动作直到整个图遍历完成;
一次删边法只能求出一个拓扑序列,通过递归便可得到所有的拓扑排序;
2、DFS搜索
(摘自博客http://blog.csdn.net/dm_vincent/article/details/7714519)
摘录一段维基百科上的伪码:
L ← Empty list that will contain the sorted nodes
S ← Set of all nodes with no outgoing edges
for each node n in S do
visit(n)
function visit(node n)
if n has not been visited yet then
mark n as visited
for each node m with an edgefrom m to ndo
visit(m)
add n to L
DFS的实现更加简单直观,使用递归实现。利用DFS实现拓扑排序,实际上只需要添加一行代码,即上面伪码中的最后一行:add n to L。
需要注意的是,将顶点添加到结果List中的时机是在visit方法即将退出之时。
这个算法的实现非常简单,但是要理解的话就相对复杂一点。
关键在于为什么在visit方法的最后将该顶点添加到一个集合中,就能保证这个集合就是拓扑排序的结果呢?
因为添加顶点到集合中的时机是在dfs方法即将退出之时,而dfs方法本身是个递归方法,只要当前顶点还存在边指向其它任何顶点,它就会递归调用dfs方法,而不会退出。因此,退出dfs方法,意味着当前顶点没有指向其它顶点的边了,即当前顶点是一条路径上的最后一个顶点。
下面简单证明一下它的正确性:
考虑任意的边v->w,当调用dfs(v)的时候,有如下三种情况:
- dfs(w)还没有被调用,即w还没有被mark,此时会调用dfs(w),然后当dfs(w)返回之后,dfs(v)才会返回
- dfs(w)已经被调用并返回了,即w已经被mark
dfs(w)已经被调用但是在此时调用dfs(v)的时候还未返回
需要注意的是,以上第三种情况在拓扑排序的场景下是不可能发生的,因为如果情况3是合法的话,就表示存在一条由w到v的路径。而现在我们的前提条件是由v到w有一条边,这就导致我们的图中存在环路,从而该图就不是一个有向无环图(DAG),而我们已经知道,非有向无环图是不能被拓扑排序的。
那么考虑前两种情况,无论是情况1还是情况2,w都会先于v被添加到结果列表中。所以边v->w总是由结果集中后出现的顶点指向先出现的顶点。为了让结果更自然一些,可以使用栈来作为存储最终结果的数据结构,从而能够保证边v->w总是由结果集中先出现的顶点指向后出现的顶点。
本题代码:
#include <iostream>
#include <string.h>
#include <stdio.h>
#include <string>
#include <sstream>
using namespace std;
int map[27][27];
int degree[30],exit[30];
int totl;
char sss[300];
void DFS(int step)
{
int i,j;
if(step==totl)//totl为总的节点的个数,step表示当前输出数组中的元素的个数,当step==totl时候表明所有的节点都放到了数组sss中,这是便可以输出返回;
{
cout<<sss<<endl;
return ;
}
for(i=0; i<27; i++)//遍历26个字母找到存在的字母编号
{
if(exit[i]&°ree[i]==0)//exit[]数组表示节点i是否存在
{
exit[i]=0;//让该节点消失
sss[step]='a'+i;//存入输出数组
for(j=0;j<27;j++)//找到与i相连的所有节点,并使这些节点的入度减一;
{
if(map[i][j])
degree[j]--;
}
DFS(step+1);//再次进行DFS();//即再次搜索入度为零的节点
for(j=0;j<27;j++)//恢复原来的入度值
{
if(map[i][j])
degree[j]++;
}
exit[i]=1;//将该节点表示为存在
}
}
}
int main()
{
char str[30];
int i,k;
string s;
char x,y;
while(gets(str))
{
memset(map,0,sizeof(map[0])*27);
memset(exit,0,sizeof(exit));
memset(sss,'\0',sizeof(sss));
memset(degree,0,sizeof(degree));
k=strlen(str);
totl=(k+1)/2;
for(i=0; i<k; i++)
{
if(str[i]==32)
continue;
exit[str[i]-'a']=1;//存入数组
}
getline(cin,s);
stringstream sin;//字符串输入输出流
sin<<s;
while(sin>>x>>y)
{
map[x-'a'][y-'a']=1;
degree[y-'a']++;//将度初始化
}
DFS(0);//DFS搜索
printf("\n");
memset(str,'\0',sizeof(str));
}
return 0;
}














 247
247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









