







1. 引言
模式识别是根据对象特征值将其分类,下面介绍的方法以特征值的统计概率为基础。本文是《模式识别》第2章的笔记。
1.1 为什么可用Bayes决策理论分类?
人们根据不确定性信息作出推理和决策需要对各种结论的概率作出估计,这类推理称为概率推理。贝叶斯推理的问题是条件概率推理问题,这一领域的探讨对揭示人们对概率信息的认知加工过程与规律、指导人们进行有效的学习和判断决策都具有十分重要的理论意义和实践意义。
(1)样本的不确定性
1. 样本从总体中抽取,特征值都是随机变量,在相同条件下重复观测取值不同,故x为随机向量。
2. 特征选择的不完善引起的不确定性。
3. 测量中有随机噪声存在
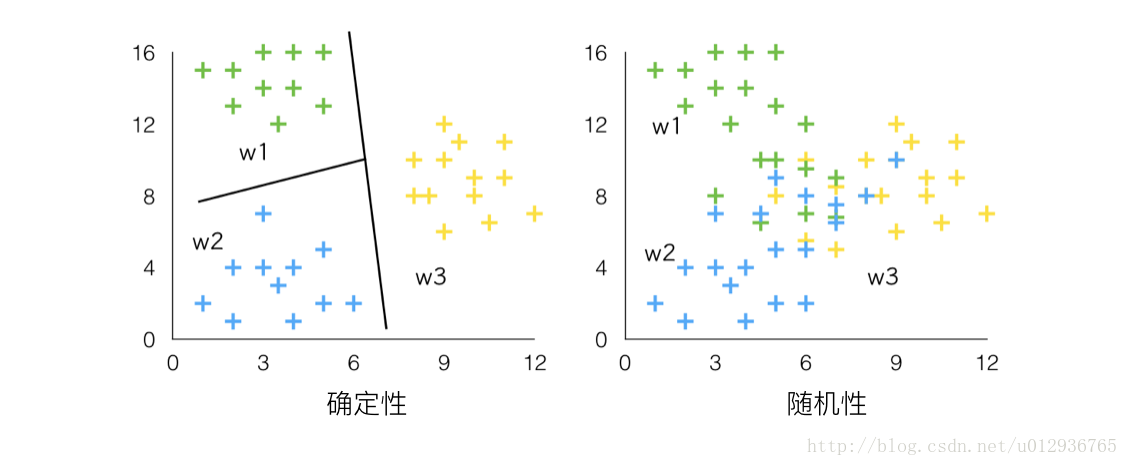
(2)样本的可分性
1. 当各类模式特征之间有明显的可分性时,可用直线或曲线(面)设计分类器,有较好的效果。
此分类决策为确定性分类决策,当样本属于某类时,其特征向量一定会落入对应的决策区域中,当样本不属于某类时,其特征向量一定不会落入对应的决策区域中。现有待识别的样本特征落入了某决策区域中,则它一定属于对应的类。
2. 当各类别出现混淆现象时,则分类困难。这时需要采用统计方法,对模式样本的统计特性进行观测,分析属于哪一类的概率最大,然后按照某种判据分类,如分类错误发生的概率最小,或者是分类的风险最小。
此分类决策为随机性分类决策。特征空间中有多个类,当样本属于某类时,其特征向量会以一定的概率取得不同的值,现有待识别的样本特征向量取得某值,则它按不同概率有可能属于不同的类,分类决策将它按概率的大小划归到某一类别中。
1.2 三个重要的概率和概率密度
1.2.1 先验概率 P(ωi)
由样本的先验知识得到先验概率,可由训练集样本估算出来。
例如,三类一共10个训练样本,属于w1的有2个,属于w2的有3个,属于w4的有5个,则先验概率:
1.2.2 类条件概率密度函数 p(x|ωi)
类条件概率密度函数用来描述每一类中特征向量的分布情况。是样本 x 在
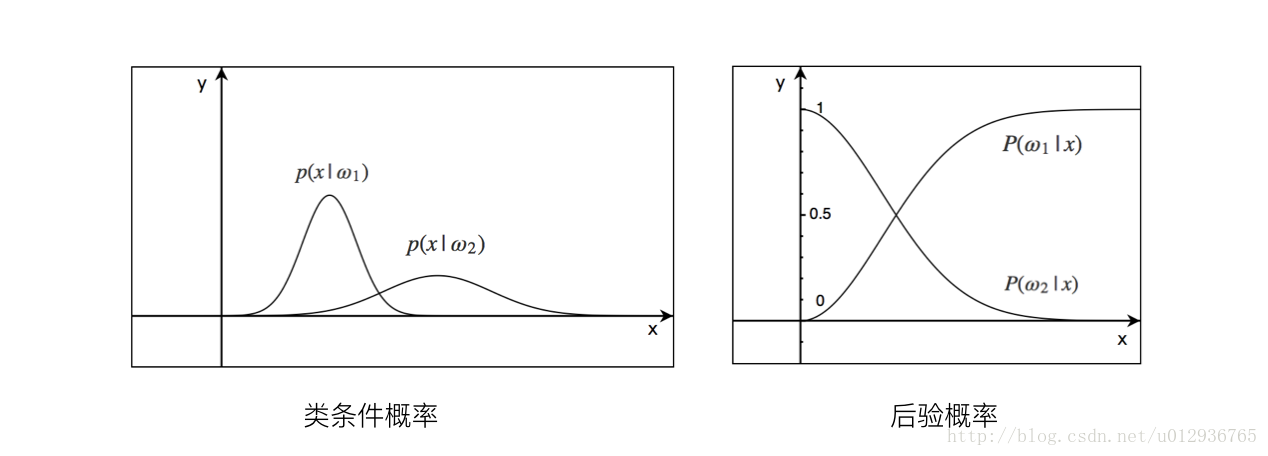
1.2.3 后验概率
p(ωi|x)
后验概率为某个样本 x , 属于
ωi
类的概率, i=1,……,c ωi 是离散变量
如果用先验概率 P(ωi) 来确定待分样本的类别,依据是非常不充分的,需用类条件密度 p(x|ωi) 来修正。
2. 贝叶斯决策理论
贝叶斯决策理论是用概率统计方法研究决策问题。其基本思想是: 已知类条件概率密度和先验概率,然后利用贝叶斯公式转换成后验概率,根据后验概率大小进行决策分类。
2.1 贝叶斯分类
2.1.1 贝叶斯公式
概率推理:
如有条件B,则可能会出现结果A;现出现结果A,则条件B有存在的可能。
设试验E的样本空间为 S ,
A
为 E 的事件,
B1,B2,……,Bc
为 S 的一个划分,且
P(A)>0
, P(Bi)>0 ,则
P(Bi|A)=P(A|Bi)P(Bi)∑cj=1P(A|Bj)P(Bj)=P(A|Bi)P(Bi)P(A)
其中:
P(Bi|A) 为后验概率,表示事件A(结果A)出现后,各不相容的条件 Bi 存在的概率,它是在结果出现后才计算得到的,因此称为“后验”。
P(A|Bj) 为类条件概率,表示在各条件 Bi 存在时,结果事件A发生的概率。
P(Bj) 称为先验概率,表示各不相容的条件 Bi 出现的概率,它与结果A是否出现无关,仅表示根据先验知识或主观推断。
P(A) 表达了结果A在各种条件下的总体概率。
这里A对应特征向量 x, Bi 对应 ωi 2.1.2 贝叶斯决策理论的已知条件
1. 已知决策分类的类别数为 c ,各类别的状态为:
ωi,i=1,……,c
2. 已知各类别总体的概率分布(各个类别的先验概率和类条件概率密度函数)
P(ωi),p(x|ωi),i=1,……,c
2.1.3 贝叶斯决策理论欲解决的问题
如果在特征空间中观察到某一个(随机)向量,
x=(x1,x2,……,xd)T
那么,应该将 x 分到哪一个类才是最合理的? 2.2 各种贝叶斯分类器
2.2.1 最小错误率贝叶斯分类器
当已知类别出现的先验概率
P(ωi)
和每个类中的样本分布的类条件概率密度 P(x|ωi) 时,可以求得一个待分类样本属于每类的后验概率 P(ωi|x) 。
决策规则:
两类问题中,当 P(ωi|x)>P(ωj|x) , 判决 x∈ωi;
多类问题中,当 P(ωi|x)=max1≤j≤cP(ωj|x) 时,判决 x∈ωi;
上述的分类决策规则实为“最大后验概率分类器”,它与“最小错误率分类器”的关系可以简单分析如下:
什么是分类错误率呢?:
分类错误率是指一个分类器按照其分类决策规则对样本进行分类,在结果中发生错误的概率,此处记为 P(e|x) ,即在随机向量x值已知的情况下,发生分类错误的概率。
对于随机向量 x 的每一个取值,都存在一个分类错误率
P(e|x=xi)
对于总体而言,错误率P(e)即为每一点分类错误率对随机向量x的期望,即:
P(e)=Ex(P(e|x))=∫P(e|x)p(x)dx
对于 二分类而言:
P(e|x)={
P(ω1|x),P(ω2|x),当P(ω2|x)>P(ω1|x)当P(ω1|x)>P(ω2|x)
则
P(e)=∫P(e|x)p(x)dx=∫R1P(ω2|x)p(x)dx+∫R2P(ω1|x)p(x)dx
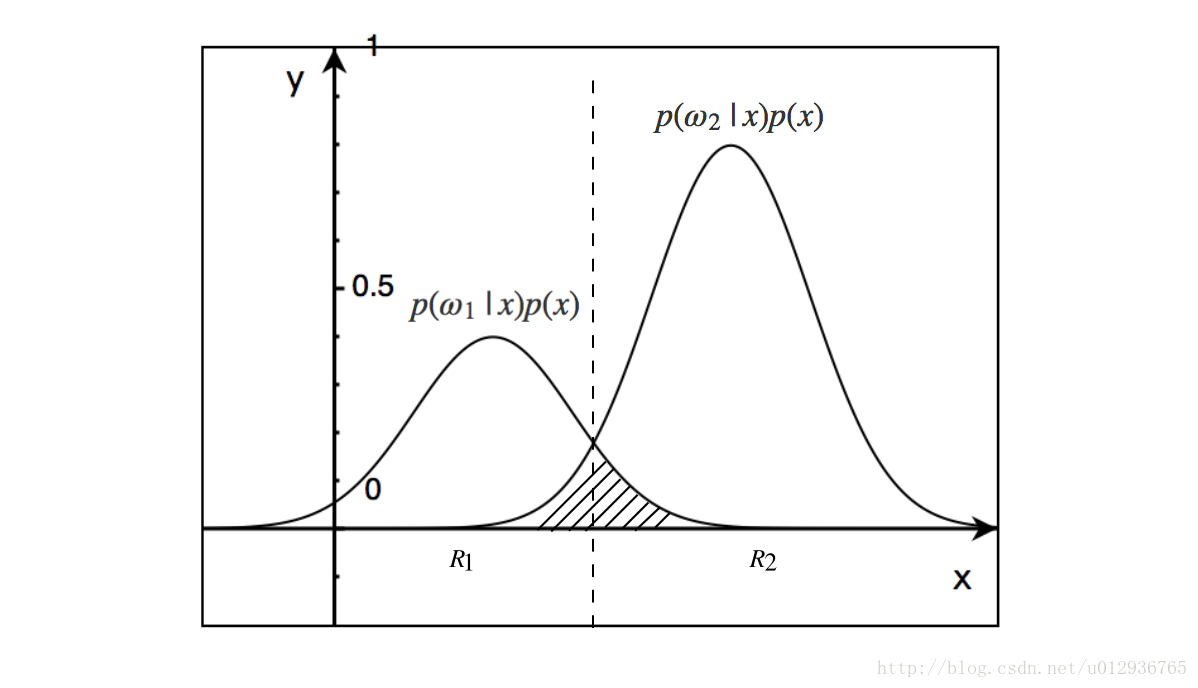
其中, R1 为判定为 ω1 的随机向量 x 的区域,
R2
为判定为 ω2 的随机向量 x 的区域。即为图中阴影部分的区域面积。
最小化错误率即对于每一个判定区域,取得令
P(e|x)
值最小的类,则阴影区域面积最小。
对于 c类的多分类而言:
正确的分类结果是未知的,但是判定错误时,正确结果一定在除了判定类别的其他类别中, 所以:
P(e|x)=1−P(ωi|x)P(ωi|x)=max1≤j≤cP(ωj|x)
则
P(e)=∫P(e|x)p(x)dx=∑i=1c∫Ri(1−P(ωi|x))p(x)dx
对每个点都采取相同的策略,取最大后验概率,即最大后验概率分类器即为最小分类错误分类器。 直接估算后验概率比较困难,通常利用贝叶斯公式,用先验概率和似然函数计算出来。
P(ωi|x)=P(ωi)p(x|ωi)p(x)
而 p(x) 只与数据集的分布有关,与类别 ωi 无关,最大后验概率,即为最大 P(ωi)p(x|ωi) 。
最大后验概率的其他等价形式:
1. 当 p(x|ωi)P(ωi)=max1≤j≤np(x|ωj)P(ωj) 时,判决 x∈ωi;
2. 对于所有的类别 ωj(j≠i) 都有, l(x)=p(x|ωi)p(x|ωj)>P(ωj)P(ωi) 。
l(x) 称为似然比,所以又叫最大似然比。
P(ωj)P(ωi) 称为似然比阈值。
3. h(x)=−ln[l(x)]=−ln(p(x|ωi))+ln(p(x|ωj))<
如果用先验概率 P(ωi) 来确定待分样本的类别,依据是非常不充分的,需用类条件密度 p(x|ωi) 来修正。
如有条件B,则可能会出现结果A;现出现结果A,则条件B有存在的可能。
设试验E的样本空间为 S ,
两类问题中,当 P(ωi|x)>P(ωj|x) , 判决 x∈ωi;
多类问题中,当 P(ωi|x)=max1≤j≤cP(ωj|x) 时,判决 x∈ωi;
上述的分类决策规则实为“最大后验概率分类器”,它与“最小错误率分类器”的关系可以简单分析如下:
什么是分类错误率呢?:
分类错误率是指一个分类器按照其分类决策规则对样本进行分类,在结果中发生错误的概率,此处记为 P(e|x) ,即在随机向量x值已知的情况下,发生分类错误的概率。
对于随机向量 x 的每一个取值,都存在一个分类错误率
对于总体而言,错误率P(e)即为每一点分类错误率对随机向量x的期望,即:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 992
992











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









