






我是调剂学软件工程的,学校里讲的知识很基础,也不全面。今天面试又被虐了!一直有想放弃技术的想法,但是每想到有些人不如我一样找到好工作。因此我就下定决心,还得走技术这条路,不然能干什么呢,现在还没毕业有的是时间来学习。所以这里特意整理遇到的面试题,以备以后用到。
一、算法
几种常会用到的算法:
二、1.你理解的面向对象(经常会被问到)
现实世界中,随处可见的一种事物就是对象,对象是事物存在的实体,如人类、书桌、计算机、高楼大厦等。面向对象程序设计的思想就是以对象来思考问题,例如,现在面临一只大雁要从北往南飞这样一个问题。
(1)首先可以从这一问题中抽象出对象,这里抽象出的对象为大雁。
(2)然后识别这个对象的属性,对象具备的属性都是静态属性,如大雁有一对翅膀、一双脚、一只嘴等。
(3)接着识别这个对象的动态行为,即这只大雁可以进行的动作,如飞行、觅(mi)食、跳跃等。这些行为都是这个对象基于其属性而具有的动作。
(4)识别出这个对象的属性和行为后,这个对象就被定义完成了。
(5)然后可以根据这只大雁具有的特性制定这只大雁从北往南飞的具体方案以解决问题。
所有大雁都具有以上的属性和行为,可以将这些属性和行为封装起来以描述大雁这类动物。类实质上就是封装对象属性和行为的载体,而对象则是类抽象出来的一个实例。
2.面向过程(有时候会问面向对象和面向过程的区别,回答的时候可以先回答上面的,然后再简单解释下面向过程即可)
面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了。
三、面向对象的三大特征:封装、继承、多态
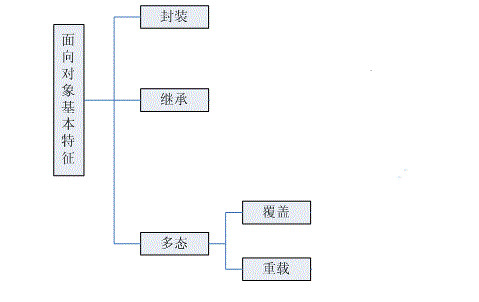
1.封装:将对象的属性和行为封装起来,其载体是类,类通常对用户隐藏其实现的细节而只为用户提供对象属性和行为的接口,用户通过这些接口使用这些类,无须知道这些类内部是如何构成的,不能操作类中的内部数据。
2.继承:继承是一种关联关系。当处理一个问题时,可以将有用的类保存下来在遇到同样问题时拿来复用。例如,解决一个信鸽送信问题,鸽子属于鸟类,具有与鸟类相同的属性和行为,我们创建信鸽时将鸟类拿来复用,保留了鸟类具有的属性和行为又添加一些信鸽具有的独特的属性和行为。这样就节省了定义信鸽和鸟类共同具有的属性和行为的时间,这就是继承的基本思想。使用继承思想可以缩短软件开发时间,复用那些已经定义好的类可以提高系统性能,减少系统在使用过程中出现错误的几率。
3.多态:多态具体的表现是重写与重载。重写是父类与子类之间的多态表现(子类中定义与父类同名同参数的方法)。重载是一个类中的多态表现(一个类中定义多个同名方法,但参数个数不同、类型不同或者两者都不同)。
用一个例子来实现多态(面试时让写)
DuoTaiDemo.java
package polymorphism;
//定义一个抽象动物类
abstract class Animal {
//抽象类里面必须包含至少一个抽象方法
abstract void eat();
}
//定义一个Cat类继承于Animal父类
class Cat extends Animal{
//在子类中重写父类方法
public void eat(){
System.out.println("吃鱼。。。");
}
//在子类中重写父类方法
public void catchMouse(){
System.out.println("抓老鼠。。。");
}
}
//定义一个Dog类继承父类Animal父类
class Dog extends Animal{
//在子类中重写父类方法
public void eat(){
System.out.println("吃骨头。。。");
}
//在子类中重写父类方法
public void watchHome(){
System.out.println("看家。。。");
}
}
//定义多态类
public class DuoTaiDemo{
//程序入口主函数
public static void main(String[] args) {
//调用function静态方法,并传递实例化对象
function(new Cat());
function(new Dog());
//这里的执行是在上面两步执行完毕后又执行的。对应程序结果中打印的最后两句。
Animal a=new Cat();//向上转型
a.eat();
Cat c=(Cat)a;//向下转型
c.catchMouse();
}
//上面调用了function方法后,会传递对象进来(这里是和Animal a=new Cat();//向上转型 相同的),进而此方法。
public static void function(Animal a){
//调用对象的方法
a.eat();
//使用instanceof操作符判断对象类型。
//语法:myobject(某类的对象引用) instanceof ExampleClass(某个类)
//返回值为布尔值,如果返回值为true,则myobject对象为ExampleClass的实例对象,否则不是。
if(a instanceof Cat)
{
Cat c=(Cat)a;//向下转型。注意:这里为什么要用instanceof操作符,当向下转型时,如果父类对象不是子类对象的实例,
c.catchMouse();//就会发生ClassCastException异常,所以在向下转型之前养成良好的习惯,判断父类对象是否为子类对象的实例。
}
else if(a instanceof Dog)
{
Dog d=(Dog)a;
d.watchHome();
}
}
}
程序运行结果:

四、多线程
1、我们可以通过计算机听歌、打印文件,而这些动作可以同时进行,这在java中被称为并发(binggfa),而将并发完成的每一件事情称为线程。在程序中执行多个线程,每个线程完成一个功能,并与其他线程并发执行,这种机制称为多线程。
2、每个独立执行的程序都称为进程,也就是正在执行的程序。
系统为每个进程分配一段有限的CPU时间片段,CPU在这段时间中执行某个进程,然后下一个时间段又跳至另一个进程中去执行。由于CPU转换较快,所使得每个进程好像是在同时执行一样。
注意:一个进程可以同时包含多个线程,一个线程就是进程中的中的一个顺序执行流。每个线程也可以得到一小段程序执行时间,这样一个进程就可以具有多个并发执行的线程。
进程和程序区别:
(1)进程和程序关系犹演出和剧本关系。
(2)进程是动态的,而程序静态的。
(3)进程有一定生命期,而程序是指令的集合,本身无“运动”含义。
(4)1个程序对应多进程,1个进程只能对应1个程序。
3、实现线程的两种方式,分别是继承java.lang包中的Thread类和实现java.lang包中的Runnable接口。
1.继承Thread类创建新线程的步骤:
(1)定义Thread类的子类,并重写该子类的run()方法,该run方法的方法体就代表了线程需要执行的任务。
(2)创建Thread子类的实例,即创建了线程对象。
(3)用线程对象的start()来启动该线程。
在main方法中,使线程执行需要调用Thread类中的start()方法,start()方法调用被覆盖的run()方法,如果不调用start()方法,线程永远都不会启动。
在主方法没有调用start()方法之前,Thread对象只是一个实例,而不是一个真正的线程。另外:主方法的线程启动由Java虚拟机负责,程序员负责启动自己的线程。
如果:start()方法调用一个已经启动的线程,系统会抛出IllegalThreadStateException异常。
package thread;
//1.1创建Thread类的子类FirstThread
public class FirstThread extends Thread{
private int i;
//1.2重写run()方法
public void run(){
for(int i=0;i<10;i++){
//当线程继承Thread类时,可以直接调用getName()方法返回当前线程名。
//如果想获得当前线程,可以直接使用this。
System.out.println(getName()+" "+i);//返回当前该线程的名字。
}
}
public static void main(String[] args) {
for(int i=0;i<10;i++){
//调用Thread的currentThrad方法获取当前线程。
System.out.println(Thread.currentThread().getName()+" "+i);
if(i==2){
//2创建Thread子类的实例,并
//3用线程对象的start()方法来启动该线程
new FirstThread().start();
//2创建Thread子类的实例,并
//3用线程对象的start()方法来启动该线程
new FirstThread().start();
}
}
}
}
main 0
main 1
main 2
Thread-0 0
Thread-0 1
Thread-0 2
Thread-0 3
Thread-0 4
Thread-0 5
Thread-0 6
main 3
main 4
main 5
main 6
main 7
main 8
main 9
Thread-1 0
Thread-1 1
Thread-1 2
Thread-1 3
Thread-1 4
Thread-0 7
Thread-1 5
Thread-0 8
Thread-1 6
Thread-0 9
Thread-1 7
Thread-1 8
Thread-1 9
2.当程序需要继承其他类(非Thread类)而且还要使当前类实现多线程,可以通过Runnable接口来实现。使用Runnable接口启动新线程的步骤:
(1)定义Runnable接口的实现类,并重写该接口的run()方法,该run方法的方法体同样是该线程的线程执行体。
(2)创建Runnable实现类的实例,并以此实例作为Thread的target来创建Thread对象,该Thread对象才是真正的线程对象。
(3)调用线程对象的start方法启动该线程。
package thread;
//1.1定义Runnable接口的实现类,
public class SecondThread implements Runnable{
private int i;
//1.2重写run方法
public void run(){
for(int i=0;i<10;i++){
//当线程类实现Runnable接口时,想获得当前线程只能用Thread.currentThread()方法
System.out.println(Thread.currentThread().getName()+" "+i);
}
}
public static void main(String[] args){
for(int i=0;i<10;i++){
System.out.println(Thread.currentThread().getName()+" "+i);
if(i==2){
//2创建Runnable实现类的实例
SecondThread st=new SecondThread();
//3并以此实例作为Thread的target来创建Thread对象,该Thread对象才是真正的线程对象。
//通过new Thread(target,name)方法创建新线程
new Thread(st,"新线程1").start();
new Thread(st,"新线程2").start();
}
}
}
}
程序运行结果:
main 0
main 1
main 2
新线程1 0
main 3
main 4
新线程1 1
新线程2 0
main 5
main 6
main 7
main 8
main 9
新线程2 1
新线程2 2
新线程2 3
新线程2 4
新线程1 2
新线程2 5
新线程1 3
新线程2 6
新线程1 4
新线程2 7
新线程1 5
新线程2 8
新线程2 9
新线程1 6
新线程1 7
新线程1 8
新线程1 9
4、线程的生命周期
线程生命周期包括7种状态,分别为:新建状态、就绪状态、(阻塞状态)、运行状态、死亡状态。
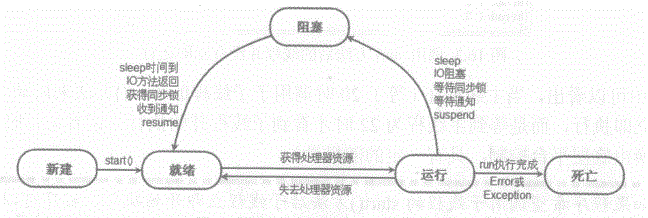
其当用new 创建完线程对象该线程处于新建状态
当线程对象调用了start()该线程处于绪状态
处于绪状态线程获得CPU时间片开始执行run方法线程执行体该线程处于运行状态
线程调用了sleep()或者调用了阻塞式IO方法等该线程处于阻塞状态
线程run()执行完成或者抛出未捕获异常等原因该线程处于死亡状态
五、集合类

1、java.util包中提供了集合类。集合类与数组的区别是数组长度不可变,集合长度可变。数组用来存放基本类型的数据,集合用来存放对象的引用。
2、Collection接口常用的方法:
(1)add(E e) 将指定的对象添加到该集合中
(2)remove(Object o) 将指定的对象从该集合中移除
(3)isEmpty() 返回boolean值,用于判断当前集合是否为空
(4)iterator() 返回在此Collection接口的元素上进行迭代的迭代器,用于遍历集合中的对象。
(5)size() 返回int型值,获取该集合中元素的个数。
3、List集合中的元素允许重复,各个元素的顺序就是对象插入的顺序。
1.List接口继承了Collection接口,因此包含Colleciton中所有的方法,此外还有两个很重要的方法:
(1)get(int index):获取指定索引位置的元素。
(2)set(int index,Object obj):将集合中指定索引位置的对象修改为指定的对象。
2.List接口常用的实现类是:ArrayList与LinkedList。
(1)ArrayList类是采用数组的形式保存对象的,这样可以根据索引位置对集合进行快速的随机访问;缺点是向指定的索引位置插入对象或删除对象的速度较慢。
(2)LinkedList类是采用链表结构保存对象,这种结构的优点是便于向集合中插入和删除对象,所以当需要向集合中插入、删除对象时使用LinkList类实现的List集合的效率高。但对于随机访问集合中的对象,使用LinkList类实现List集合的效率低。
4、Set集合
1.Set集合中的对象不按特定的方式排序,只是简单把对象加入到集合中,所以Set集合中不能包含重复的对象。
2.Set接口常用的实现类有HashSet类和TreeSet类
HashSet是Set接口典型的实现,大多数时候使用Set集合时就是用这个实现类。HashSet按Hash算法来存储集合中的元素,因此具有很好的存储和查找功能。
HashSet特点:
(1) 不能保证元素的排列顺序,顺序有可能是发生变化的。
(2)HashSet不是同步的,如果多个线程访问一个Set集合,或者多个线程同时访问一个HashSet,再者如果两条或两条以上的线程同时修改了HashSet集合时,必须通过代码来保证其同步。
(3) 集合元素值可以为null。
当向HashSet集合中存入一个元素时,HashSet会调用对象的HashCode()方法得到该对象的HashCode值,然后根据该HashCode值来决定该对象在HashSet中的存储位置。如果两个元素通过equals方法返回true,但是它们的HashCode()方法返回值不相等,HashSet会把它们存储到不同的位置,即是可以添加成功的。【HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的HashCode()返回值也相等】
TreeSet类不仅实现了Set接口,还实现了java.util.SortedSet接口,因此TreeSet类可以确保集合中的元素处于排序状态。TreeSet支持两种排序:自然递增排序和定制递增排序;即TreeSet类实现的Set集合在遍历集合时按照自然顺序递增排序,也可以通过比较器对用TreeSet类实现的Set集合中的对象进行排序。
3.Map集合没有继承Collection接口,其提供的是key到value的一对一的映射关系。
Map接口常用的实现类有HashMap和TreeMap。
(1)我们常用HashMap类实现Map集合,因为由HashMap类实现的Map集合添加、删除映射关系效率更高。因为HashMap是基于哈希表的Map接口的实现,HashMap通过哈希吗对其内部的映射关系进行快速查找。
(2)但此类不保证映射的顺序,特别是他不保证该顺序恒久不变。
(3)允许使用null值和null键,但必须保证键的唯一性。
TreeMap中的映射关系存在一定的顺序。所以如果希望Map集合中的对象也存在一定的顺序,就使用TreeMap类实现Map集合。另外:由于TreeMap类实现的Map集合中的映射关系是根据键对象按照一定的顺序排列的,因此不允许键对象为null。















 4982
4982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









