







利用Hadoop完成对NBA 30支球队球风的聚类
本程序完成了Hadoop下,利用MapReduce思想实现K_means聚类算法。由于本人只有一台笔记本,加之写这个程序的主要原因是学习MapReduce思想,以及如何使用Hadood编程,因此主要面向功能的实现,数据集没有选择大数据集。
本程序在Linux下利用Eclipse开发,开发之前需要搭建Hadoop集群,配置伪分布模式或完全分布模式,安装Eclipse并为其安装hadoop-eclipse-plugin-x.x.x.jar插件。以上步骤可参考网上其他博客~
实验数据为2016-2017NBA常规赛各支球队数据指标:http://www.basketball-reference.com/leagues/NBA_2017.html
我对其进行了下载和手工“清洗”。NBA本赛季跑轰风大行其道,以勇士,火箭,骑士等球队为代表,跑轰就是所谓的打小球的意思。衡量一个球队是不是跑轰型球队,很好的衡量标准就是此球队在场上的节奏值(pace值),跑轰球队都是小个,因此速度很快,有种打闪电战的意思,往往10秒以内就能完成一次进攻,迅雷不及掩耳盗铃,另对方措手不及。跑轰球队还有一个很重要的指标就是三分球出手次数,我们看到像勇士,火箭,骑士等球队场均三分球出手次数都特别高,而像马刺之类的传统球队,不仅pace值低,而且很少投三分。所以实验我为了简单,就用这两个指标作为球风的评判标准,看看哪些球队球风相似~
实验数据就俩,一个是所有球队三分球出手次数和pace值(data.txt 我后面会附上数据的下载链接,供大家验证),如下:
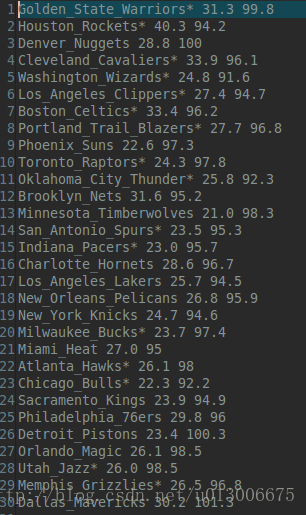
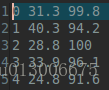
另一个就是我手工选取的初始五个聚类中心点(centers.txt 为了方便我直接选了前五个,必须承认这样是不好的,还是那句话,为了实现功能)
开始实验前,你必须将数据(.txt格式)存放到对应路径下(可能与代码中的路径不一致,请自行修改),然后将数据上传到HDFS文件系统中(利用Eclipse上传就好了),实验结束你会得到另一个txt文件,代表聚类结果(注意Eclipse中更新数据后必须右击刷新一下才能看到,这是个bug)
然后运行代码(代码写的比较粗糙,但整体思路还算清晰),稍等个把小时就能得出结果(你可以将代码中的迭代次数或者阈值修改一下,这样就能很快收敛,程序就可以快快的运行完成)
功能部分建议先了解一下思路,然后就能看懂了,如果哪里有疑问,或者有错误,请留言讨论,我就不解释了(人懒哈哈)。话不多说,上代码:
在此之前,先看下整个项目的目录结构
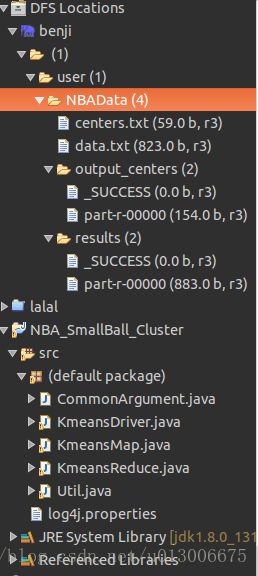
首先就是HDFS文件系统:里面NBAData目录中存放了NBA球队数据,然后项目中共有五个.java文件,建议看的顺序为CommonArgument –> KmeansDriver –> KmeansMap –> KmeansReduce,然后Util类中实现了一些辅助方法,因此你遇到这个方法打开Util找一下就好(穿插着看)。
//CommonArgument.java
import org.apache.hadoop.fs.Path;
public class CommonArgument {
public static final int K=5;//聚类的类别数为5
public static final String inputlocation="hdfs://localhost:8020/user/NBAData/data.txt";
public static final String outputlocation="hdfs://localhost:8020/user/NBAData/results";
public static final String center_inputlocation="hdfs://localhost:8020/user/NBAData/centers.txt";
public static final String center_outputlocation="hdfs://localhost:8020/user/NBAData/output_centers";
public static final String new_center_outputlocation="hdfs://localhost:8020/user/NBAData/output_centers/part-r-00000";
public static final int REPEAT=100;
public static final float threshold=(float)0.1;
public static Path inputpath=new Path(inputlocation);
public static Path outputpath=new Path(outputlocation);
public static Path center_inputpath=new Path(center_inputlocation);
public static Path center_outputpath=new Path(center_outputlocation);
}
//KmeansDriver.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
public class KmeansDriver {
// 主函数
public static void main(String[] args) throws Exception {
int repeats = 0;
do {
Configuration conf = new Configuration();
// 新建MapReduce作业并指定作业启动类
Job job = new Job(conf);
// 设置输入输出路径(输出路径需要额外加判断)
job.setJarByClass(KmeansDriver.class);
FileInputFormat.addInputPath(job, CommonArgument.inputpath);// 设置输入路径(指的是文件的输入路径)
FileSystem fs = CommonArgument.center_outputpath.getFileSystem(conf);
if (fs.exists(CommonArgument.center_outputpath)) {// 设置输出路径(指的是中心点的输出路径)
fs.delete(CommonArgument.center_outputpath, true);
}
FileOutputFormat.setOutputPath(job, CommonArgument.center_outputpath);
// 为作业设置map和reduce所在类
job.setMapperClass(KmeansMap.class);
job.setReducerClass(KmeansReduce.class);
// 设置输出键和值的类
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 启动作业
job.waitForCompletion(true);
repeats++;
} while (repeats < CommonArgument.REPEAT && (Util.isOK(CommonArgument.center_inputlocation,
CommonArgument.new_center_outputlocation, CommonArgument.REPEAT, CommonArgument.threshold)));
// 进行最后的聚类工作(由map来完成)
Configuration c_conf = new Configuration();
// 新建MapReduce作业并指定作业启动类
Job c_job = new Job(c_conf);
// 设置输入输出路径(输出路径需要额外加判断)
FileInputFormat.addInputPath(c_job, CommonArgument.inputpath);// 设置输入路径(指的是文件的输入路径)
FileSystem fs = CommonArgument.outputpath.getFileSystem(c_conf);// 设置输出路径(指的是中心点的输出路径)
if (fs.exists(CommonArgument.outputpath)) {
fs.delete(CommonArgument.outputpath, true);
}
FileOutputFormat.setOutputPath(c_job, CommonArgument.outputpath);
// 为作业设置map(没有reducer,则看到的输出结果为mapper的输出)
c_job.setMapperClass(KmeansMap.class);
// 设置输出键和值的类
c_job.setOutputKeyClass(Text.class);
c_job.setOutputValueClass(Text.class);
// 启动作业
c_job.waitForCompletion(true);
}
}
//KmeansMap.java
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class KmeansMap extends Mapper<LongWritable, Text, Text, Text> {
public static final int num = 2;// 定义对象维度
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 首先将value中的数字提取出来,放到容器当中
String data = value.toString();
data=data.replace("\t", " ");
String[] tmpSplit = data.split(" ");
System.out.println("#########################################################");
System.out.println(tmpSplit.length);
System.out.println("#########################################################");
List<String> parameter = new ArrayList<>();
for (int i = 0; i < tmpSplit.length; i++) {
parameter.add(tmpSplit[i]);
}
// 读取中心点文件(其中路径参数是从命令中获取的)
List<ArrayList<String>> centers = Util.getCenterFile(CommonArgument.center_inputlocation);
// 计算目标对象到各个中心点的距离,找最大距离对应的中心点,则认为此对象归到该点中
String outKey="" ;// 默认聚类中心为0号中心点
double minDist = Double.MAX_VALUE;
System.out.println("**********************************************************");
System.out.println(centers.size());
System.out.println("**********************************************************");
for (int i = 0; i < centers.size(); i++) {
// 由于是二维数据,因此要累加两次
double dist = 0;
for(int j=1;j<centers.get(i).size();j++){
double a=Double.parseDouble(parameter.get(j));
double b=Double.parseDouble(centers.get(i).get(j));
dist+=Math.pow(a-b,2);
}
if (dist < minDist) {
//outKey = Integer.parseInt(centers.get(i).get(0));// 中心点文件中所写的标号
outKey = centers.get(i).get(0);// 中心点文件中所写的标号
minDist = dist;
}
System.out.println("");
System.out.println(dist);
System.out.println("");
}
System.out.println("----------------------------------------");
System.out.println(outKey+"+");
System.out.println("----------------------------------------");
context.write(new Text(outKey), value);
}
}
//KmeansReduce.java
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.io.LongWritable;
public class KmeansReduce extends Reducer<Text, Text, Text,Text> {
public void reduce(Text key,Iterable<Text> value,Context context)
throws IOException,InterruptedException{
//把value值放进String数组中(只获取和处理一个)
long num=0;
double threePointAtmp=0;
double pace=0;
for(Text T:value){
num++;
String onePoint=T.toString();
onePoint=onePoint.replace("\t", " ");
String[] parameters=onePoint.split(" ");
//进行累加
//for(int i=0;i<parameters.length;i++){
threePointAtmp+=Double.parseDouble(parameters[1]);
pace+=Double.parseDouble(parameters[2]);
//}
}
System.out.println("@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@");
System.out.println(threePointAtmp);
System.out.println(pace);
System.out.println("@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@");
double avg_threePointAtmp=threePointAtmp/((double)num);
double avg_pace=pace/((double)num);
String result=avg_threePointAtmp+" "+avg_pace;
context.write(key,new Text(result));
}
}
//Util.java
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.util.LineReader;
public class Util {
//中心点的个数
public static final int K=5;
//读出中心点,注意必须包括键值
public static List<ArrayList<String>> getCenterFile(String inputPath){
List<ArrayList<String>> centers=new ArrayList<ArrayList<String>>();
Configuration conf=new Configuration();
try{
FileSystem fs=CommonArgument.center_inputpath.getFileSystem(conf);
Path path=new Path(inputPath);
FSDataInputStream fsIn=fs.open(path);
//一行一行读取参数,存在Text中,再转化为String类型
Text lineText=new Text();
String tmpStr=null;
LineReader linereader=new LineReader(fsIn,conf);
while(linereader.readLine(lineText)>0){
ArrayList<String> oneCenter=new ArrayList<>();
tmpStr=lineText.toString();
//分裂String,存于容器中
tmpStr=tmpStr.replace("\t", " ");
String[] tmp=tmpStr.split(" ");
for(int i=0;i<tmp.length;i++){
oneCenter.add(tmp[i]);
}
//将此点加入集合
centers.add(oneCenter);
}
fsIn.close();
}catch(IOException e){
e.printStackTrace();
}
//返回容器
return centers;
}
//判断是否满足停止条件
public static boolean isOK(String inputpath,String outputpath,int k,float threshold)
throws IOException{
//获得输入输出文件
List<ArrayList<String>> oldcenters=Util.getCenterFile(inputpath);
List<ArrayList<String>> newcenters=Util.getCenterFile(outputpath);
System.out.println("!!!!!!!!!!!!!!!!!!!!!!!!!!!!!");
System.out.println(oldcenters.get(0).size());
System.out.println("!!!!!!!!!!!!!!!!!!!!!!!!!!!!!");
//累加中心点间的距离
float distance=0;
for(int i=0;i<K;i++){
for(int j=1;j<oldcenters.get(i).size();j++){
float tmp=Math.abs(Float.parseFloat(oldcenters.get(i).get(j))
-Float.parseFloat(newcenters.get(i).get(j)));
distance+=Math.pow(tmp,2);
}
}
/*如果超出阈值,则返回false
* 否则更新中心点文件
*/
if(distance>threshold)
return true;
//更新中心点文件
Util.deleteLastResult(inputpath);//先删除旧文件
Configuration conf=new Configuration();
Path ppp=new Path("hdfs://localhost:8020/user/NBAData/");
FileSystem fs=ppp.getFileSystem(conf);
//通过local作为中介
fs.moveToLocalFile(new Path(outputpath), new Path(
"/home/blssel/Downloads/数据/16-17常规赛nba球队数据/tmp.data"));
fs.delete(new Path(inputpath), true);//在写入inputpath之前再次确保此文件不存在
fs.moveFromLocalFile(new Path("/home/blssel/Downloads/数据/16-17常规赛nba球队数据/tmp.data")
,new Path(inputpath));
return false;
}
//删除上一次mapreduce的结果
public static void deleteLastResult(String inputpath){
Configuration conf=new Configuration();
try{
Path ppp=new Path("inputpath");
FileSystem fs2= ppp.getFileSystem(conf);
fs2.delete(new Path(inputpath),true);
}catch(IOException e){
e.printStackTrace();
}
}
}
然后运行代码,喝杯咖啡,或者出去吃个饭,注意别让电脑休眠了,然后回来检查结果(如果有错,可能是项目中有个log4j.properties的问题,自行百度下)














 3835
3835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









