








在NYU上了Machine Learning,学到了一些以前没有注意或者不知道的知识。在原有部分博文的基础上进行更详细地讲解。
关于回归算法的Bias和Variance
加深了对误差理论的理解。
对于一个输入为 x⃗ 的回归算法,我们设算法输出的预测函数为 g(x) ,算法的真正分类函数为 f(x) 。我们期望的就是让 g(x) 尽可能地与 f(x) 靠近。
我们将
f(x)
和
g(x)
当成一个连续函数,那么对于特定的
xi
,
r
表示输入数据在该点的值,且
对于固定的 xi 和一堆 g(xi) (我们可以认为是假设集里的所有函数),那么 g(xi) 就变成了一个随机变量了。
现在考虑一个长度为
N
的
其中后者指的是多个函数之间的variance。
例子1
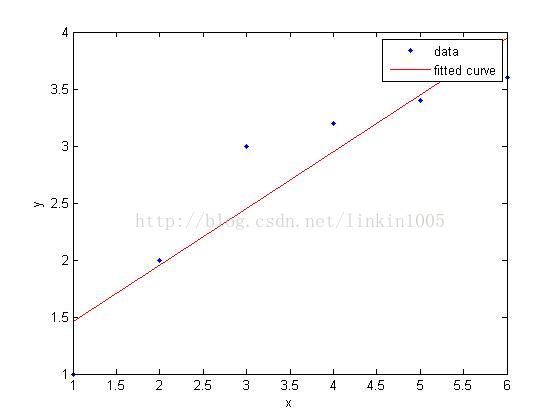
对于如图的输入样例,用一次函数去进行分类,那么我们可以明显地发现,对于特定的 xi , g(xi) 造成的bias非常大,也就是square error特别大。
但是考虑到假设集合(即,所有一次函数的集合),多个 g(x) 之间的variance是较小的。反正一次函数变来变去就只有ABC三个参数变,化简一下就只剩下斜率和偏移能够变化了。
那么当我们用五次函数去训练分类的时候,我们可以明显地发现,对于特定的 xi , g(xi) 造成的bias为0,但是五次函数的variance就明显比一次函数大多了。
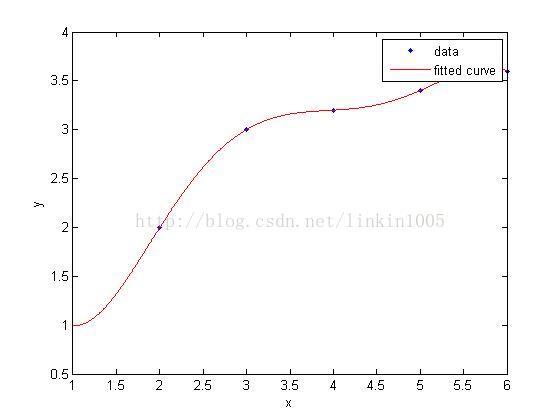
所以图1是欠拟合,图2则是过拟合。
例子2
设 f(x)=2 ,在输入的时候没有噪音,即 r=f(x)=2 。
设计算法:
- 当第一个输入的样例 (x′,r′) 中 x′>10 ,则让 g(x)=1 。
- 否则。让 g(x)=3
对于训练集合,我们让 xt 均匀得从 [0,20] 中随机得出。
设
我们可以看得出来这题的算法得出的 g(x) 的variance为0,但是它的bias却非常大。
关于逻辑回归函数的由来
Logistic函数
看到一个博客上面说逻辑回归为啥叫逻辑回归,是因为它用了Logistic函数。当时我就觉得非常牛逼,这个函数是科学家用硬生生猜出来的么。
现在才知道这个函数也是推导出来的。
我们要预测一个样本 x 的类别,则需要比较一下在输入为的x条件下,两个类别的概率大小
我们假设可以假设 P[+|x]>P[−|x] 。
那么我们就考虑函数 f(x)=log(y1−y) 。
我们让 z=log(y1−y)⇒y=11+e−z ,
同时我们让 wdxd+⋯+w1x1+w0=z ,可以得到
这就是Logistic函数的由来。
损失函数的由来
逻辑回归的损失函数是由log对数损失函数得来的。
输入 x1,x2,x3 ,那么他们的分类是 1,1,0 的概率是
我们让 y=P[1|x] ,那么对于 x1,…,xn 得到分类结果是 r1,…,rn 的概率是
最后得出的就是交叉熵
而我们的期望是找到 w⃗ 来使交叉熵最大,这样等价于找到一个 w⃗ 使得交叉熵的相反数最小。
我们可以假设 olog0=0 。
- 当 rt=1 时, cost=−log(yt)
- 当 rt=0 时, cost=−log(1−yt)
将以上两个表达式合并为一个,则单个样本的损失函数可以描述为:
全体样本的损失函数可以表示为:
这就是逻辑回归最终的损失函数表达式。
大家可以将 y=P[1|x]=11+e−wTx+w0 带入后进行求导,则可以得到
大家可以发现,使得上面的导数为0,是无法求出解的,所以只能用梯度下降计算
如果再考虑learning rate就可以了。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









