









一、大数据离线计算:MapReduce计算模型
1、MapReduce是处理HDFS上的数据
2、MapReduce的思想来源是PageRank(搜索排名),原理是进行分布式计算。

如上图,网页跳转中,访问网页3的次数最多,也就是权重最大的为网页3。比如京东、淘宝中给推荐的商品,就是近期访问的比较多的商品。
MapReduce的思想是把一个大任务拆分成多个小任务,再把小任务的结果汇总,得到最后的结果。
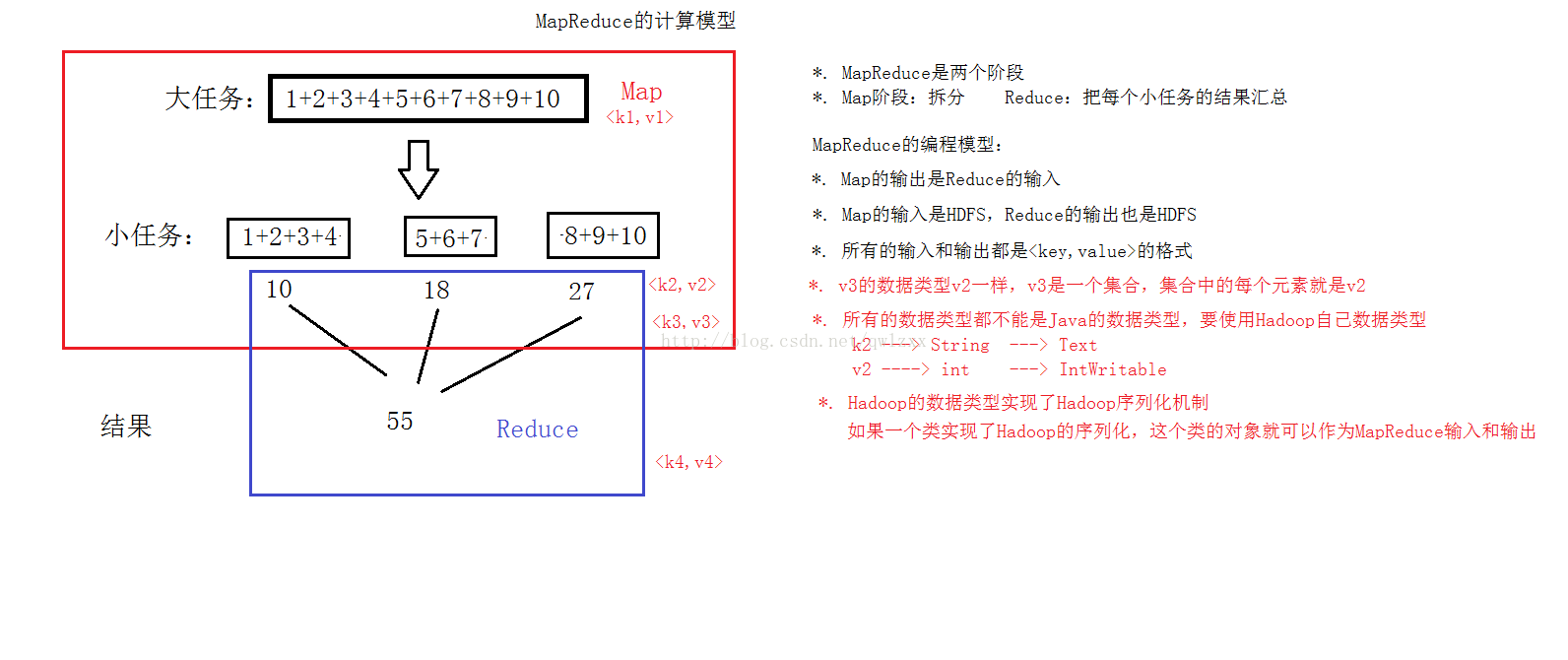
3、数据都是历史数据、数据已经存在(HDFS)
二、大数据实时计算:Apache Storm
1、特点:数据源源不断地产生,不停处理数据
2、例子:自来水厂
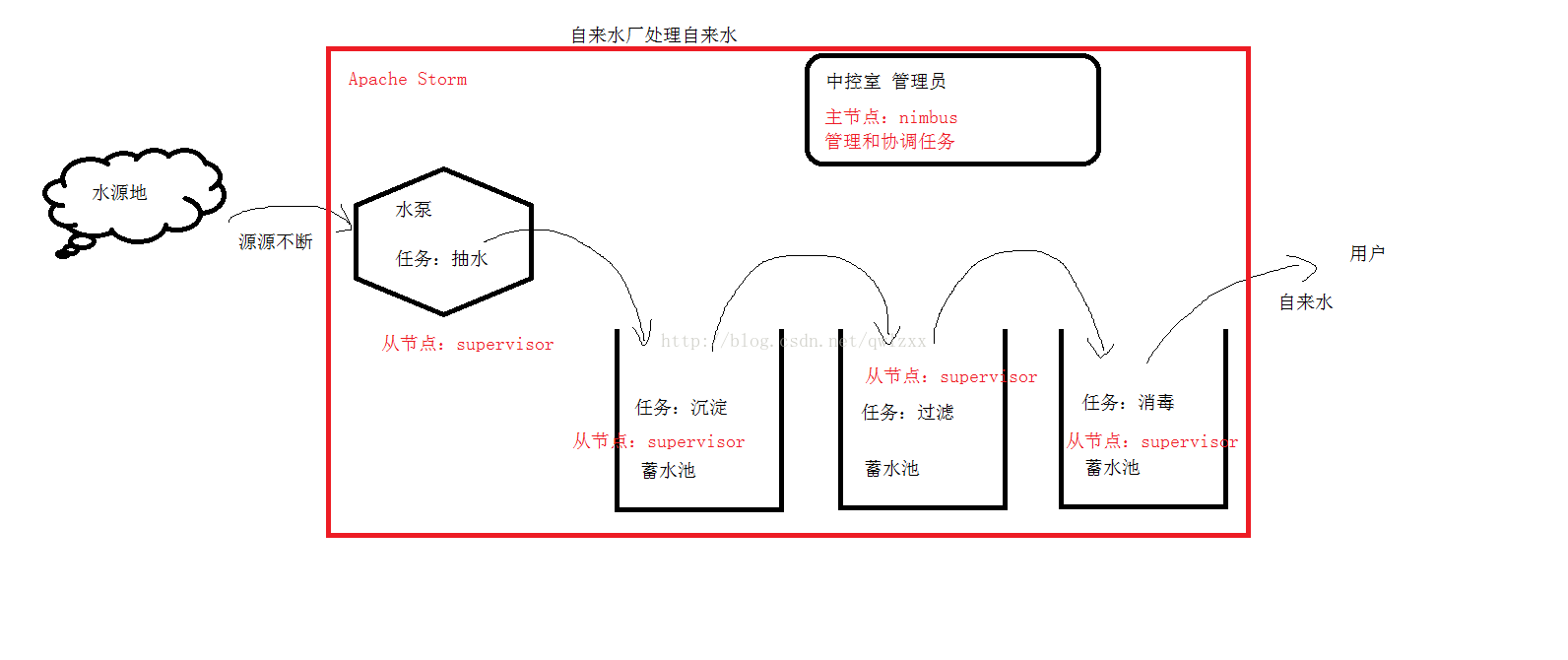
3、框架:Apache Storm、Spark Streaming
4、格式:storm jar jar文件 任务的类名 任务的别名
storm jar storm-starter-topologies-1.0.3.jar.jar org.apache.storm.starter.WordCountTopology MyWC
三、搭建Hadoop的Eclipse开发环境(不推荐)
1、配置Hadoop Home
2、hadoop.dll复制到c:\windows\system32
3、配置环境变量
HADOOP_HOME
%HADOOP_HOME%/bin配置到PATH里
4、推荐:MRUnit(MapReduce Unit),类似Junit
小结
对Hadoop的认识只停留在理论上,更多的操作在精力和时间的允许下有待实践。














 287
287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









